







 本文详细介绍了如何使用全卷积网络(FCN)解决图像语义分割问题,通过不含全连接层的全卷积结构、反卷积层的升采样以及跳级结构融合不同深度信息,实现了对任意尺寸输入的精确分割。在PASCAL VOC分割任务上取得了62.2%的IU,并提供了基于Caffe的模型和测试代码。训练过程分为四个阶段,逐步提升预测精度。
本文详细介绍了如何使用全卷积网络(FCN)解决图像语义分割问题,通过不含全连接层的全卷积结构、反卷积层的升采样以及跳级结构融合不同深度信息,实现了对任意尺寸输入的精确分割。在PASCAL VOC分割任务上取得了62.2%的IU,并提供了基于Caffe的模型和测试代码。训练过程分为四个阶段,逐步提升预测精度。
Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.
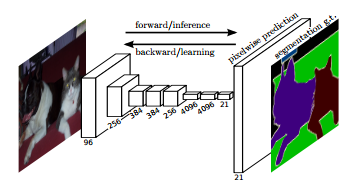
本文是深度学习应用于图像分割的代表作,作为Oral发表于CVPR 2015,在许多教程中都被推荐(例如Li Feifei在Standford的视觉识别CNN)。第二作者Evan Shelhamer也是Caffe的首席开发者。
本文在图像分割问题中应用了当下CNN的几种最新思潮,在PASCAL VOC分割任务上IU(交比并)达到62.2%,速度达到5fps。提供了基于Caffe的模型和测试python代码。
辨:两种分割任务
semantic segmentation - 只标记语义。下图中。
instance segmentation - 标记实例和语义。下图右。
本文研究第一种:语义分割

核心思想
本文包含了当下C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6122
6122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









