










ECCV 2016
code: http://www.cbsr.ia.ac.cn/users/hailinshi/
Embedding Deep Metric for Person Re-identification: A Study Against Large Variations
针对行人检索问题,这里主要做了两个方向的工作:1)针对大家使用的hard negative mining 策略,我们提出了 moderate positive mining策略,这两个策略是可以相互结合的。2)针对 Metric Learning,我们加了一个权值约束,Weight Constraint for Metric Learning,提高学习到的度量的泛化能力。
3.1 Moderate Positive Mining
Large Intra-class Variations 行人的同类间距很大,所以对于样本的选择还是有技术含量的。
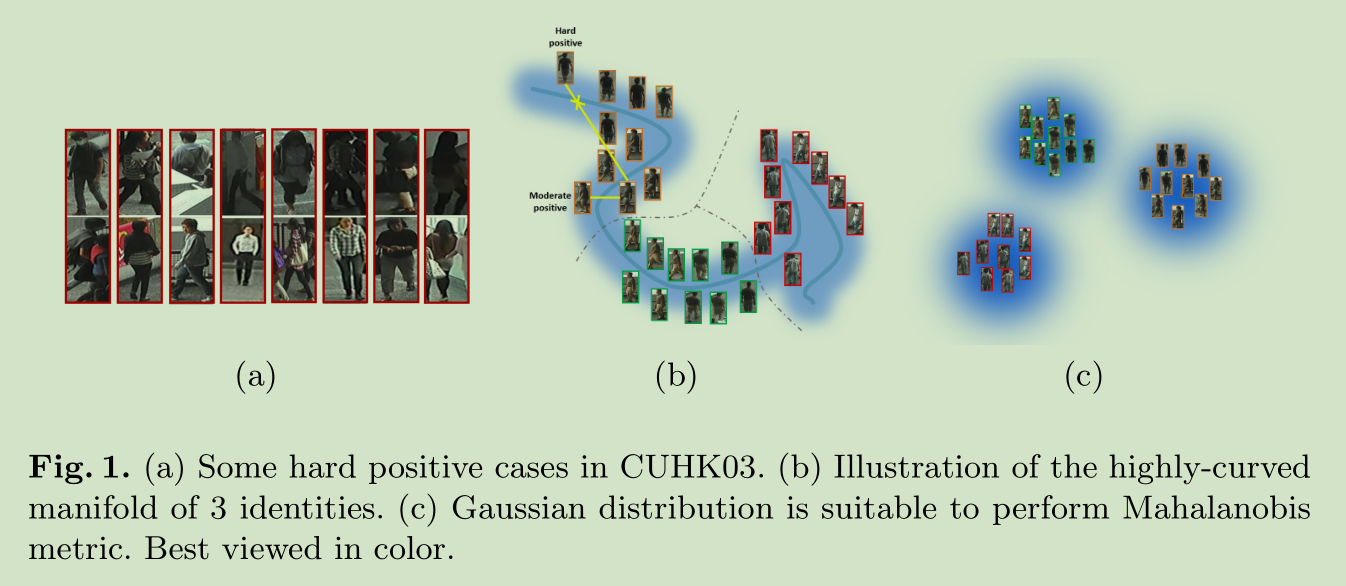
选择的样本不要太难,也不要太简单。
Here, we argue that selecting positive samples in the local range (pairing by the yellow line in Fig. 1(b)) is critical for training the network; training with the positive samples of large distance (the yellow line with cross) may distort the manifold and harm the manifold learning.

对于一个anchor样本,我们随机选择相同数据的正负样本构成一个mini-batch,然后从中找出 hardest negative sample,然后将距离小于最难负样本的正样本选出来, the positive samples that have smaller distances than the hardest negative,最后在这些正样本中选出最难正样本作为我们的 moderate positive sample。
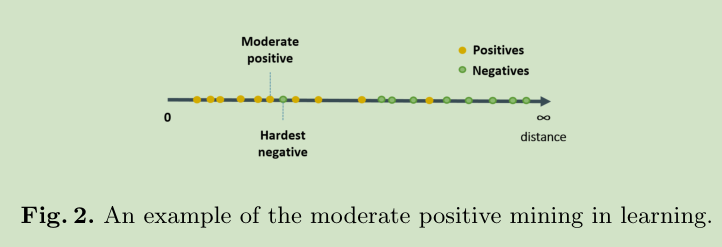
3.2 Weight Constraint for Deep Metric Learning
对于Deep Metric Learning 我们采用文献【11】中的DDML,公式如下
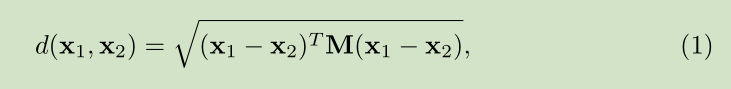
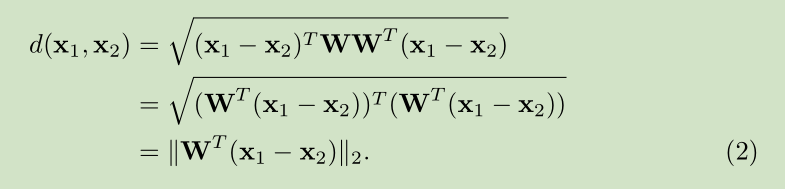

Metric Learning 网络层
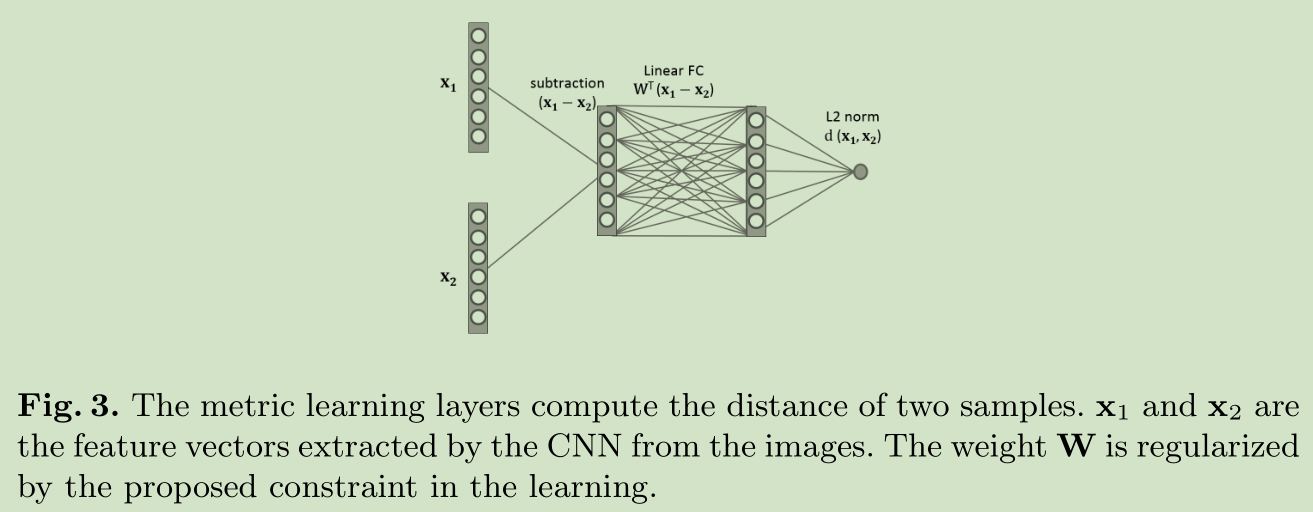
加入权值约束
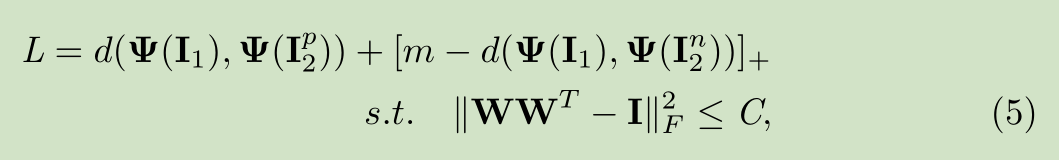
最终的损失函数
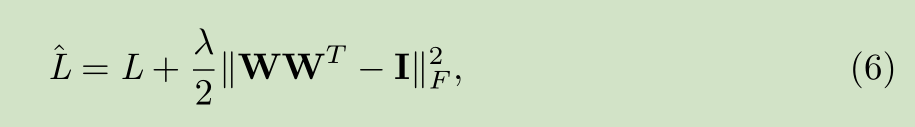
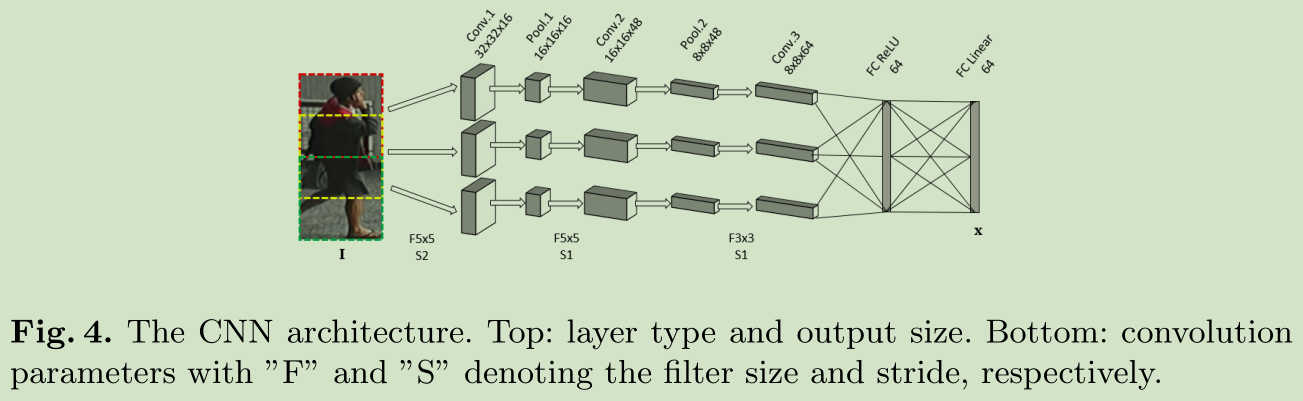
CNN网络结构如下:
结果:
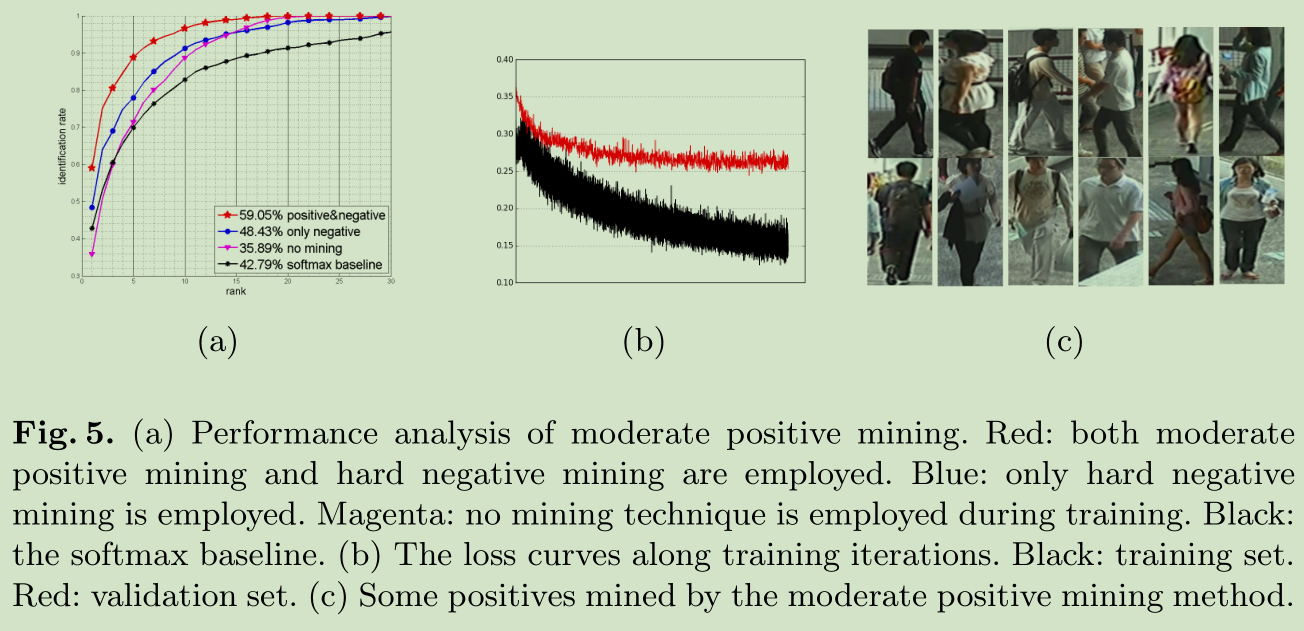
moderate positive mining对结果的影响
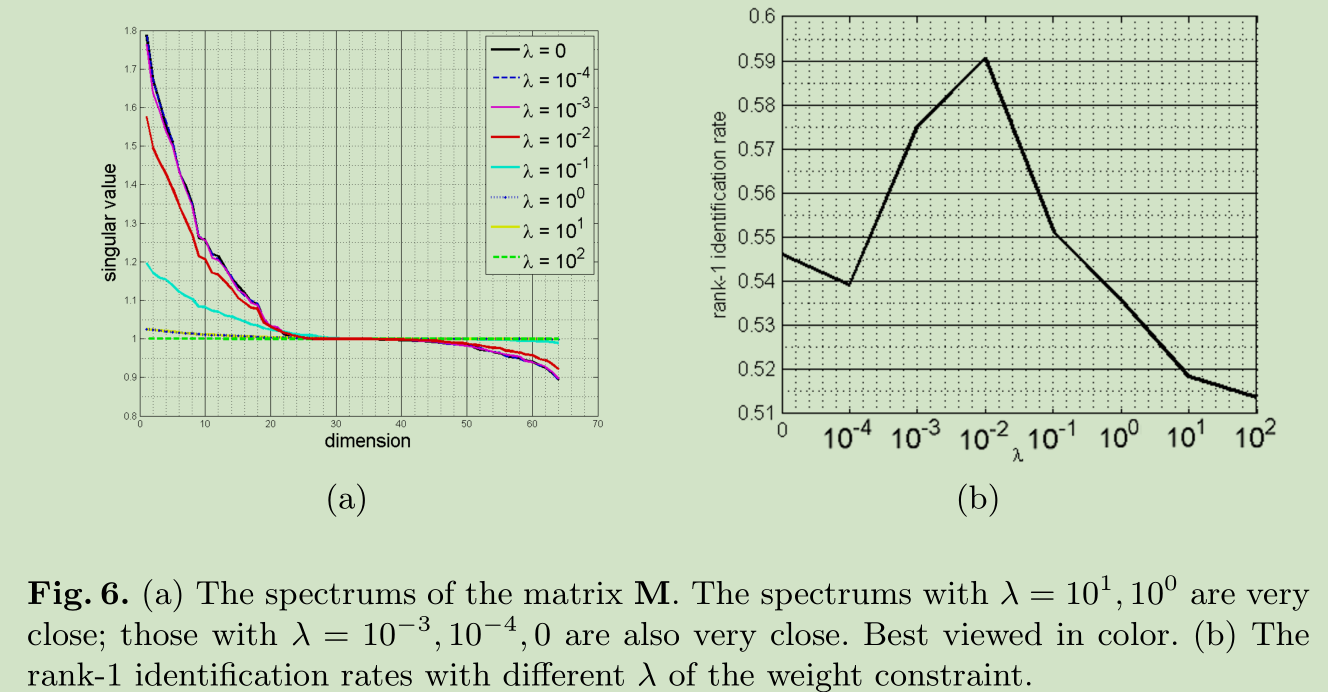
权值约束的影响
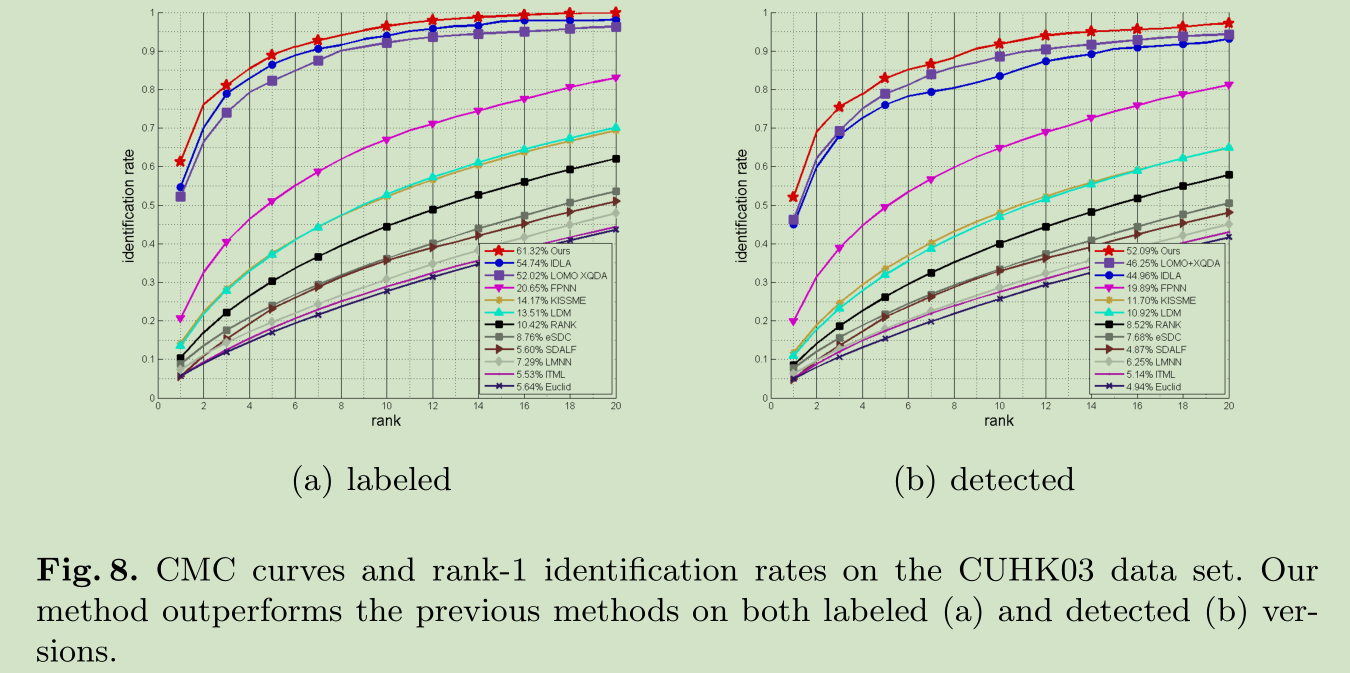
CUHK03 数据上的效果
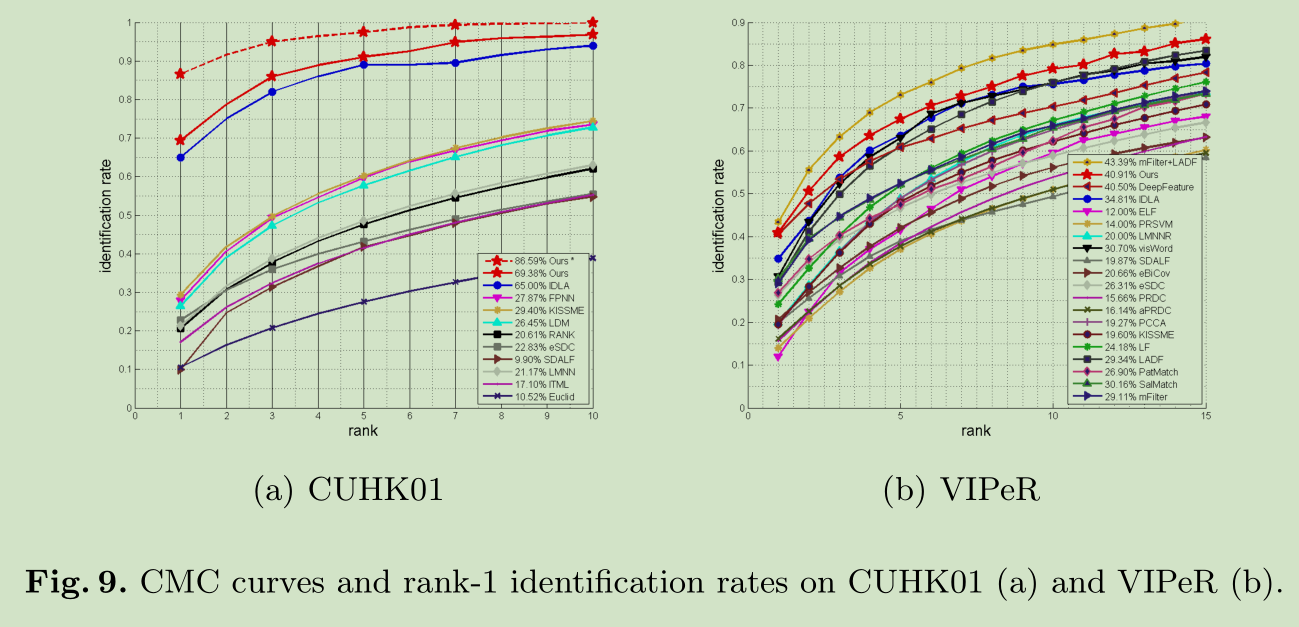
CUHK01和 VIPeR的效果















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









