







重构
但在本教程中,我们将重点关注受限玻尔兹曼机如何在无监督情况下学习重构数据(无监督指测试数据集没有作为实际基准的标签),在可见层和第一隐藏层之间进行多次正向和反向传递,而无需加大网络的深度。
在重构阶段,第一隐藏层的激活值成为反向传递中的输入。这些输入值与同样的权重相乘,每两个相连的节点之间各有一个权重,就像正向传递中输入x的加权运算一样。这些乘积的和再与每个可见层的偏差相加,所得结果就是重构值,亦即原始输入的近似值。这一过程可以用下图来表示:
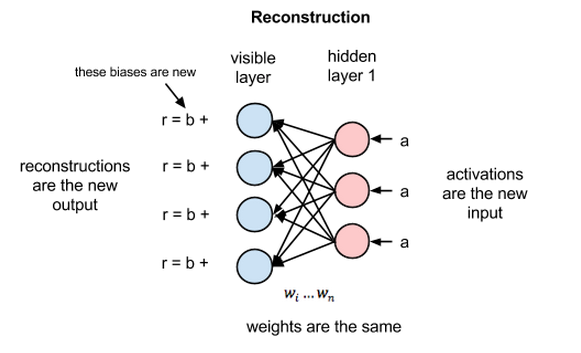
由于RBM权重初始值是随机决定的,重构值与原始输入之间的差别通常很大。可以将r值与输入值之差视为重构误差,此误差值随后经由反向传播来修正RBM的权重,如此不断反复,直至误差达到最小。
由此可见,RBM在正向传递中使用输入值来预测节点的激活值,亦即输入为加权的x时输出的概率:p(a|x; w)。
但在反向传递时,激活值成为输入,而输出的是对于原始数据的重构值,或者说猜测值。此时RBM则是在尝试估计激活值为a时输入为x的概率,激活值的加权系数与正向传递中的权重相同。 第二个阶段可以表示为p(x|a; w)。
上述两种预测值相结合,可以得到输入x和激活值a的联合概率分布,即p(x, a)。
重构与回归、分类运算不同。回归运算根据许多输入值估测一个连续值,分类运算是猜测应当为一个特定的输入样例添加哪种具体的标签。而重构则是在猜测原始输入的概率分布,亦即同时预测许多不同的点的值。这被称为生成学习,必须和分类器所进行的判别学习区分开来,后者是将输入值映射至标签,用直线将数据点划分为不同的组。
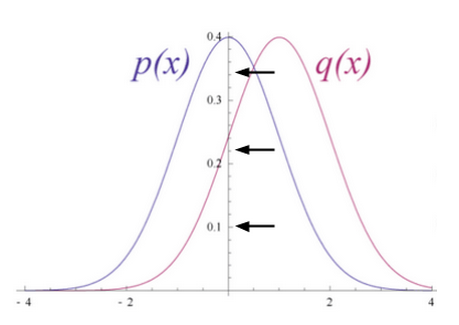
试想输入数据和重构数据是形状不同的常态曲线,两者仅有部分重叠。
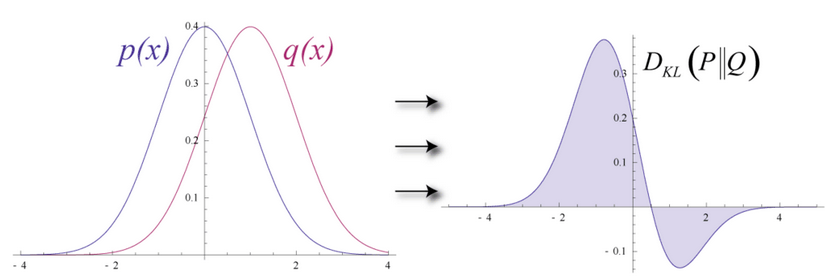
RBM用Kullback Leibler散度来衡量预测的概率分布与输入值的基准分布之间的距离。
KL散度衡量两条曲线下方不重叠(即离散)的面积,而RBM的优化算法会尝试将这些离散部分的面积最小化,使共用权重在与第一隐藏层的激活值相乘后,可以得到与原始输入高度近似的结果。下图左半边是一组原始输入的概率分布曲线p,与之并列的是重构值的概率分布曲线q;右半边的图则显示了两条曲线之间的差异。
RBM根据权重产生的误差反复调整权重,以此学习估计原始数据的近似值。可以说权重会慢慢开始反映出输入的结构,而这种结构被编码为第一个隐藏层的激活值。整个学习过程看上去像是两条概率分布曲线在逐步重合。















 3427
3427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









