









Anchor-Free系列之CornerNet: Detecting Objects as Paired Keypoints_程大海的博客-CSDN博客
Anchor-Free系列之CenterNet:Objects as Points_程大海的博客-CSDN博客
Anchor-Free系列之FCOS:A Simple and Strong Anchor-free Object Detector_程大海的博客-CSDN博客
Anchor-Free系列之YOLOX:Exceeding YOLO Series in 2021_程大海的博客-CSDN博客
【目标检测】无需锚框的物体检测-关键点法CornerNet - 知乎
CornetNet不使用anchor box来完成目标检测,并且达到了与当时的one-stage检测算法更好的精度。作者分析了anchor box的两个主要缺点:
- 为了提升目标检测效果,通常需要生成大量的anchor box,以YoloV3为例,在13x13、26x26、52x52三种尺度的特征图上,每个位置生成9个anchor box,一共有31941个anchor box,更多的anchor box可以保证每个目标都能够被anchor box所覆盖,提升目标检测结果的召回率,但是更多的anchor box带来了训练过程中的正负样本极度不平衡问题,减慢了训练过程
- 在生成anchor box的时候,涉及到很多超参数,如anchor box的大小,宽高比,anchor的数量等,当需要在不同尺度的特征图上做目标检测时,anchor的超参数选择就变的很复杂。以YoloV3为例,在13x13、26x26、52x52三种尺度的特征图上,13x13特征图上使用大的anchor box用来检测大目标,26x26特征图上使用中等的anchor box用来检测中等的目标,52x52特征图上使用小的anchor box用来检测小的目标。
CornerNet的核心思想:
- 使用卷积网络预测输出每个目标的左上角corner和右下角corner,同时为预测输出的每个corner输出一个embedding,用来表示这个corner
- 网络模型经过训练后,对于同一个object目标的左上角corner和右下角corner,模型预测输出的左上角embeding和右下角embedding之间的距离很小,或者说相似度很高

Corner pooling:
在进行目标检测的bounding box标注时,普遍采用的是矩形框标注,也就是通过目标的左上角和右下角坐标就能确定目标的bounding box坐标,但是由于目标通常是不规则的,在bounding box的左上角和右下角的局部区域,通常都是不包含目标的区域的,如下图所示:

针对上图中这种普遍存在的现象,由于左上角和右下角的corner根本就不存在目标,也就没办法根据这两个局部区域学习得到目标的bounding box。所以需要想办法将目标的整体特征和这两个corner区域关联起来。
左上角top-left:
通过观察左上角我们发现,目标在左上角坐标的右侧和下方
右下角bottom-right:
通过观察右下角我们发现,目标在右下角坐标的左侧和上方
基于上面的观察规律,作者设计了corner pooling,corner pooling对feature map的每个channel进行单独计算,对于feature map上的每个点:
左上角的corner pooling计算如下:
- 计算feature map上每个位置右边的最大值
- 计算feature map上每个位置下方的最大值
- 将上述两个最大值相加作为当前位置的top-left corner pooling的结果
同理,我们可以计算右下角的corner pooling.
右下角的corner pooling计算如下:
- 计算feature map上每个位置左边的最大值
- 计算feature map上每个位置上方的最大值
- 将上述两个最大值相加作为当前位置的bottom-right corner pooling的结果

CornerNet网络结构:

- backbone网络之后接两个分支的子网络,分别用来计算top-left corner和bottom-right corner的特征图,top-left分支采用适用于top-left corner的corner pooling(关注右边和下方),bottom-right分支采用适用于bottom-right corner的corner pooling(关注左边和上方)
- 将top-left corner的特征图进行corner pooling,在corner pooling的结果上进一步计算得到top-left corner的Heatmaps、Embeddings、Offsets,Heatmaps的输出通道数等于目标的类别数,每个通道对应一个类别
- 将bottom-right corner的特征图进行corner pooling,在corner pooling的结果上进一步计算得到bottom-right corner的Heatmaps、Embeddings、Offsets,Heatmaps的输出通道数等于目标的类别数,每个通道对应一个类别
其中,Heatmaps的通道数等于总类别数,表示feature map上每个位置是每个类别目标的corner的概率,Embedding表示每个corner位置的特征向量,对于属于同一目标的top-left corner embedding和bottom-right corner embedding,他们之间具有更小的空间距离,或者说具有更大的相似度。offset用来对corner的坐标结果进行修正。
Corners检测:
Corner positive和negative划分:
- 对于每个corner,在图片上只有一个positive corner,其余位置的corner均为negative,这就导致了正负样本的不均衡,所以论文采用了Focal Loss损失函数来消除正负样本不均衡带来的影响。
- 在模型训练阶段,并不是对所有的negative都一视同仁,划定在positive corner一定半径范围内的negative corner,表明这个corner虽然不完美,但是足够精确了,所以这部分negative corner带来的损失权重就小一些,其他在positive corner半径之外的negative corner的权重是一样的,如下图:

上图中,红色实线框是ground truth,绿色虚线框是预测的bounding box,橙色的圆圈标志ground truth corner的有效半径。可以看到,绿色虚线框虽然不完美,但是已经很准确率,同时看到绿色虚线框的top-left corner和bottom-right corner落在橙色圆圈内。关于positive corner周围的半径划分,论文采用IoU进行约束,也就是在半径区域内,预测结果的最小IoU要大于0.3。
在Focal Loss损失函数的基础上,加上对于负样本的加权得到如下损失函数:

Corners Offset:
在训练神经网络过程中,经常使用下采样操作,常见的包括卷积下采样,池化下采样等,然而当在模型输出层将模型的预测结果映射到原始图像上时,会存在一定的误差,这些误差对于小目标的预测准确性影响很大。CornerNet为了消除这种误差,进一步侧得到一个corner的偏移量Offset,用这个offset来修正corner的坐标。
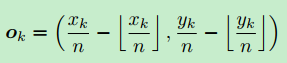
上图中的![]() 表示原图中的坐标
表示原图中的坐标![]() 经过n倍的下采样之后差生的误差偏移。然后训练网络,在输出层预测每个位置的偏移量。
经过n倍的下采样之后差生的误差偏移。然后训练网络,在输出层预测每个位置的偏移量。
Corners分组:
在图片中可能检测到多个top-left corner和多个bottom-right corner,如何将属于同一目标的top-left corner和bottom-right corner关联起来?受到人体关键点检测采用关键点embedding相似度匹配的启发,CornerNet中对每个corner都学习得到一个embedding向量,然后通过embedding向量的匹配完成top-left corner和bottom-right corner的匹配,从而检测识别目标的bounding box。
在前面介绍Corner检测时讲过,对于top-left和bottom-right的Heatmap的通道数都等于总的类别数,Heatmap上每个通道上的每个数值表示这个位置是一个目标类别的corner的概率。所以可以将top-left和bottom-right的Heatmap的对应channel的embedding进行匹配,匹配规则如下:
- 如果top-left corner和bottom-right corner属于同一目标,则拉近pull这两个corner的embedding之间的距离
- 否则,如果top-left corner和bottom-right corner属于不同目标,则分离push这两个corner的embedding之间的距离,并且分离度要达到预定的阈值条件
- 假设一张图片上有N个目标,简单理解,只有每个目标对应的那一对corner需要pull拉近,不属于同一目标的两个corner组成的N(N-1)个corner对都需要push分离。
备注:这个pull和push过程和度量学习里面用到的损失函数原理是一样的,关于度量学习的介绍,可以参考我之前的文章。

Corners Pooling:
计算corner pooling时,水平方向和竖直方向上的pooling分别在不同的feature map上进行。

















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









