









Anchor-Free系列之CornerNet: Detecting Objects as Paired Keypoints_程大海的博客-CSDN博客
Anchor-Free系列之CenterNet:Objects as Points_程大海的博客-CSDN博客
Anchor-Free系列之FCOS:A Simple and Strong Anchor-free Object Detector_程大海的博客-CSDN博客
Anchor-Free系列之YOLOX:Exceeding YOLO Series in 2021_程大海的博客-CSDN博客
开源代码:https://github.com/tianzhi0549/FCOS
备注:由于不熟悉latex公式编辑,以前都是直接从word编辑公式粘贴过来,操蛋的CSDN会把每个公式当做图片打上水印,完全没法看,所以本文的文字基本上都是截图,需要的凑合看。
Anchor-based目标检测算法的缺点:
- anchor的大小、宽高比以及anchor的数量这些超参数对算法性能影响较大,在使用anchor box的时候,涉及的超参数如下:
- anchor的大小
- anchor的宽高比
- anchor的数量
- anchor box与ground truth的IoU阈值,用来确定anchor是否为positive
- anchor box与ground truth的IoU阈值,用来确定anchor是否为ignore
- anchor box与ground truth的IoU预祝,用来确定anchor是否为negative
- 在anchor确定以后,当需要检测的目标大小尺度、宽高比发生变化时,由于采用了固定的anchor,无法很好的检测出这些尺度发生变化的目标
- 由于feature map特征图上每个位置都产生多个anchor,导致产生了大量的anchor,并且这些anchor绝大部分都是negative,导致了正负样本的极度不均衡(可以采用Focal Loss损失函数进行缓解)
- Anchor box在使用时需要额外的计算量,如需要计算anchor box与grundth truth的IoU来确定anchor是positive还是negative,以及对最终的预测输出结果进行NMS过滤
- Anchor-based的方法可以看做是Fast RCNN之前那些基于sliding window方法的升级版,anchor是基于先验知识生成的,而不是像sliding window那样暴力搜索的
YoloV1可以认为是使用Anchor-free方法较早的目标检测算法,但是YoloV1的召回率不高,所以在v2、v3、v4、v5等版本中一直使用了基于1 – IoU距离度量的kmeans方法寻找anchor。
FCOS算法整体流程:


FCOS的网络输出:

FCOS的损失函数:
- 分类:借鉴RetinaNet算法,分类分支采用Focal Loss
- 回归:借鉴RetinaNet算法,回归分支采用GIoU Loss(IoU Loss、CIoU Loss、DIoU Loss、GIoU Loss)
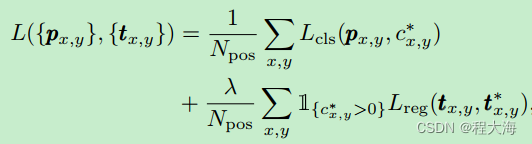
FCOS的FPN骨干网络:

基于anchor的目标检测算法,在不同尺度的特征图上,使用不用尺寸的anchor,将anchor box与FPN的特征图进行绑定,让大尺寸的特征图用来预测小目标,小尺寸的特征图用来预测大目标。而在FCOS算法中,直接设置每个特征图负责预测的目标尺寸范围,超过范围的则不在预测的职责范围内。在P3到P5上,设置的特征图负责预测目标的坐标偏移大小![]() 为64、128、256、512和无穷大,那么在P3到P5上,负责预测的目标尺寸大小为128x128、256x256、512x512、1024x1024及以上。
为64、128、256、512和无穷大,那么在P3到P5上,负责预测的目标尺寸大小为128x128、256x256、512x512、1024x1024及以上。
在FOCS中,在FPN的特征之上,对于每个层级的特征共享同一个预测头,由于不同的特征图负责预测不同尺寸的目标,共享同一个预测头可能会由于预测数值分布的差异导致性能下降,FCOS对预测头的输出结果使用stride步长进行了缩放,比如原本在P3上预测输出64,在P4上预测输出128,P5上预测输出256,由于P3、P4、P5的下采样倍数分别是8,16,32,那么64,128,256在经过各自的下采样倍数缩放以后输出结果都是8,这就消除了数值差异带来的问题。
FCOS的center-ness目标中心化度量:

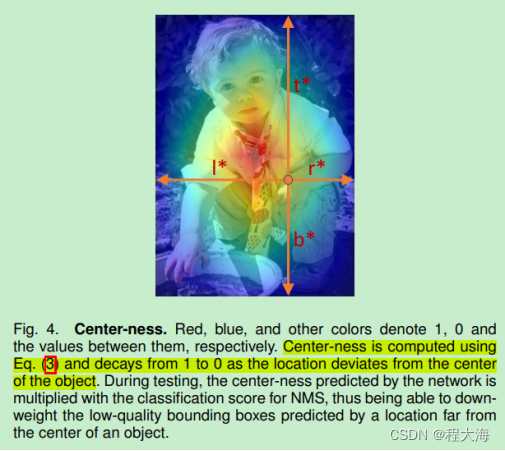
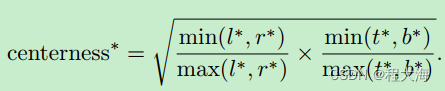

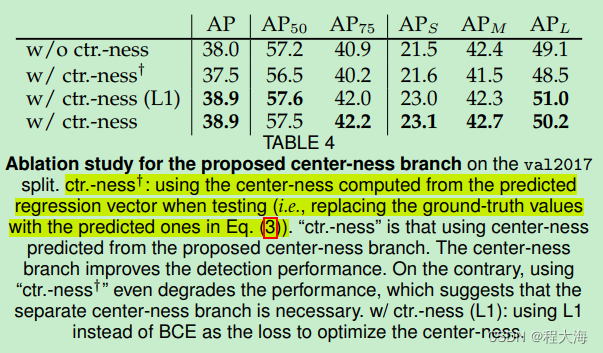
在模型测试阶段,使用预测输出的中心点概率和目标本身的类别概率共同确定目标的预测置信度:
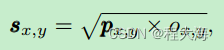
这样的话,当两个预测结果有相同的预测概率,但是由于两个目标距离目标中心的概率不同,基于此可以实现预测结果的进一步过滤选择。














 1566
1566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









