









写在前面
ATSS全名Adaptive Training Sample Selection,是在2020年提出的针对目标检测模型的一种自适应训练(正负)样本选择算法,并不是一种目标检测模型。本文针对ATSS的论文,对其中的有价值的研究结果进行了要点总结。
论文链接here

零、本文主要贡献

一、基于anchor的模型与anchor-free模型本质区别
目标检测模型可大致分为基于anchor的模型与anchor-free的模型。前者又可按stage细分为one-stage和two-stage,后者可按检测点分为key-point和center-point。论文以“基于anchor的one-stage模型RetinaNet”和“anchor-free的center-point模型FCOS”为例,比较这两者的区别,并以实验探究出基于anchor的模型与anchor-free模型的最本质区别:正负样本定义方式。RetinaNet与FCOS的我也做了要点总结,感兴趣的可以关注一下(RetinaNet;FCOS)。
1. 存在的三点区别
文章经过对比分析,总结出了两种模型的三点区别:
-
特征图每个位置上堆叠anchor的数量不同(可将FCOS的anchor point视为一个anchor)
RetinaNet论文版本在特征图的每个location堆叠A=9个anchors,而FCOS每个location视为一个anchor point。
-
正负样本定义方式不同
RetinaNet靠anchor box与GT box的IoU值来确定正负样本,而FCOS依据location在原图上是否落入GT box以及GT box尺寸大小与特征图level关系来综合确定正负样本(这里提到的FCOS未使用
center-sampling机制,更有趣的是,其实此机制就是本论文作者团队提出的,后来被FCOS团队采用并入FCOS第二版论文)。

-
Bounding box的回归计算起始态不同
RetinaNet在anchor基础上,回归计算其与结果box的4个offsets { Δ x , Δ y , Δ w , Δ h } \{\Delta x, \Delta y, \Delta w, \Delta h \} {Δx,Δy,Δw,Δh},而FCOS在location基础上,计算其与结果box的4个边界距离 { l , r , t , b } \{l, r, t, b \} {l,r,t,b}。

两种模型最本质最关键的区别就藏在这三点之中。
2. 对比实验以及结果
由于FCOS使用了一些RetinaNet上未使用的新的技巧提升模型性能,论文首先做了不一致的消除,以保证后续对比实验的科学性。如下表所示,作者将RetinaNet每个location的anchors设置为1个,与FCOS相同;之后依次将FCOS里的新技巧运用于RetinaNet。不一致消除后,两者仍然差距0.8个点,这就说明这部分差距一定是由最本质最关键区别带来的。接下来可以开展正式的对比试验了。

由于在不一致消除中,上述三点的第一点已被探究并排除,文章主要探究后两点是否为最本质最关键的区别。下图为实验结果。

先看看表格的表头。首列表头为正负样本定义方式的区别,对应三点区别的第二点,Intersection over Union即为RetinaNet使用的IoU方式,而Spatial and Scale Constraint则为FCOS使用的方式;首行表头为bbox回归起始态的区别,对应三点区别最后一点,Box为RetinaNet使用的方式,而Point对应FCOS。
接下来观察表内实验数据:竖看会发现,使用同一回归起始态的两种模型依旧有近0.8个点的性能差距;横看又会发现,使用同一正负样本定义方式的两种模型性能几乎持平了,并且使用FCOS方式后的RetinaNet尽管保留了其原本边界框回归起始态,性能却也提升至与FCOS相当。由此得出结论:造成基于anchor模型与anchor-free模型性能差异的最本质最关键的区别为正负样本定义方式。

二、ATSS算法
基于上述对比实验结果,论文提出了一种全新的、普适的、高性能的正负样本定义方式:Adaptive Training Sample Selection,即ATSS算法。下面为算法流程。

算法其实就做了三件事:(1)为每个GT box在每个level特征图上选择候选正样本集合;(2)计算每个GT box所有候选正样本的数字特征;(3)根据特征选择正负样本。
-
Line 2 ~ Line 6
为每个GT box g g g建立一个候选正样本集合 C g C_{g} Cg,在每个level上根据GT目标中心与anchor的L2距离选出最近的k个候选正样本,k为超参数。候选正样本集合 C g C_{g} Cg为每个level上候选正样本集合的并集。举个例子,若共有L个level,则每个GT box的候选正样本集合中元素个数为 k ∗ L k * L k∗L个。论文后来通过实验证明ATSS算法对于唯一超参数k值不敏感,几乎可以视为无超参数(见下图table 4)。 -
Line 7 ~ Line 10
对于某个GT box g g g,将之与 C g C_{g} Cg中候选正样本依次计算IoU值,得到IoU集合 D g D_{g} Dg;之后计算 D g D_{g} Dg的均值 m g m_{g} mg与标准差 v g v_{g} vg;最后得到此GT box g g g阈值 t g = m g + v g t_{g} = m_{g} + v_{g} tg=mg+vg。 -
Line 11 ~ Line 13
对于 C g C_{g} Cg中每个候选正样本:若(1)其与GT box的IoU值 ≥ t g \geq t_{g} ≥tg,并且(2)其中心点落入GT box内部,则该候选正样本被选为正样本;反之则被归为负样本。

三、实验及其结果
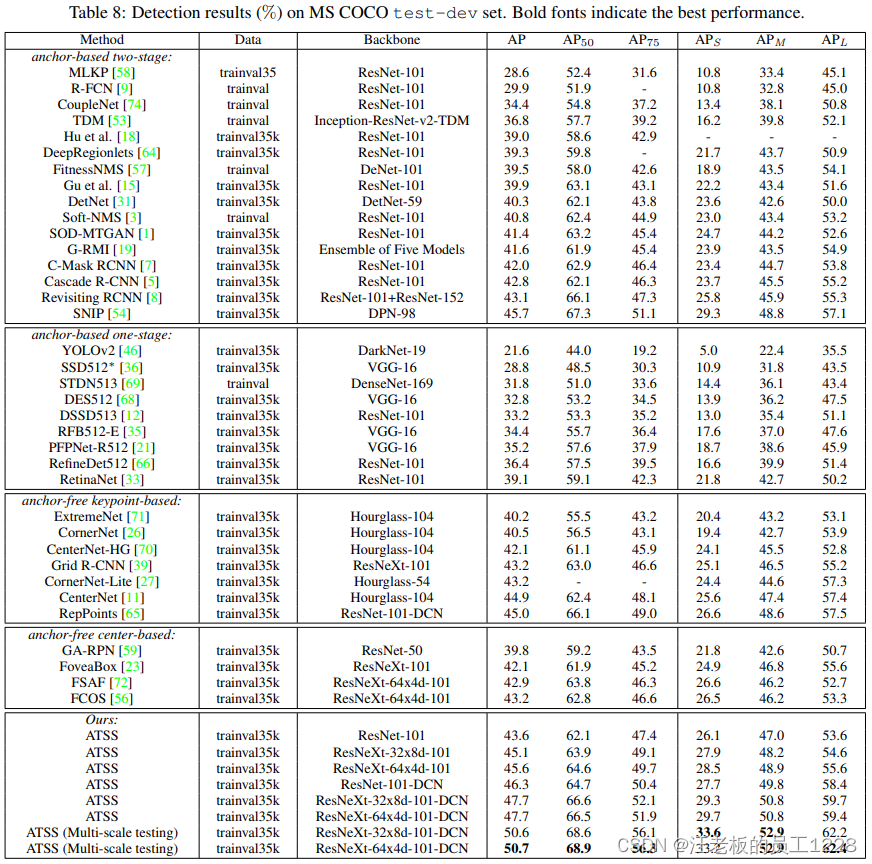
之后,论文将ATSS用于目标检测模型,并于各种模型进行性能上的对比。
可以看到,ATSS效果超群。使用ResNet-101坐backbone的ATSS模型击败了同backbone的所有模型;使用ResNeXt-32x8d-101和ResNeXt-64x4d-101的升级版本更是几乎无敌手(仅落后SNIP 0.1个点);之后论文还添加DCN结构和使用多尺度测试,这些让模型性能更上一层楼,并达到SOTA:50.7%的AP。
在讨论阶段,论文探究了超参数k值对算法的影响(算法阶段已提到这里不赘述);还对于anchors的设置探究了“使用ATSS算法的模型对于anchors设置的鲁棒性”,其中包括:是否有必要像RetinaNet一样在每个location上堆叠许多不同大小以及宽高比的anchors?结果是:(1)使用ATSS算法的模型对于anchors设置非常鲁棒;(2)没有必要像RetinaNet一样在每个location上堆叠许多不同大小以及宽高比的anchors。下图为实验结果表格,两张图分别对应(1)与(2)。




















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











