







JSP(Job Shop Scheduling Problem)是一种经典的组合优化问题,它的目标是在一组机器上安排一组工件的加工顺序,使得完成所有工件所需的最短时间(Cmax)最小。JSP 是一个 NP-hard 问题,即没有已知的多项式时间的算法可以找到最优解,因此需要使用一些启发式或近似的方法来求解。
强化学习(Reinforcement Learning, RL)是一种模拟智能体与环境的交互过程的学习方法,它的基本思想是通过不断地尝试不同的动作,观察环境的反馈(奖励或惩罚),来更新智能体的策略(行为准则),从而逐渐提高智能体的性能(累积奖励),直到达到预设的目标。强化学习的优点是可以在不完全或不确定的环境中进行学习,不需要事先知道环境的模型,可以自适应地调整策略,缺点是需要大量的试错,可能陷入局部最优,需要设计合适的奖励函数,状态空间,动作空间等。
结合以上代码,强化学习求解 JSP 问题的流程如下:
首先,定义强化学习的基本要素,如状态空间,动作空间,奖励函数,策略,值函数等。
状态空间:表示智能体所处的环境的情况,可以用一个二维矩阵来表示,其中每个元素表示一个机器上的一个工件,每一行表示一个机器,每一列表示一个时间段,每个元素的值表示该工件的编号,如果该位置没有工件,则用 0 表示。例如,[[0, 0, 0, 0, 0], [1, 2, 0, 0, 0], [0, 0, 3, 4, 0]] 表示有三台机器,五个时间段,第一台机器没有工件,第二台机器有工件 1 和 2,第三台机器有工件 3 和 4。
动作空间:表示智能体可以采取的行为的集合,可以用一个列表来表示,其中每个元素表示一个可行的动作,每个动作是一个元组,表示将一个工件从一个机器上移动到另一个机器上,例如,[(1, 2), (2, 3), (3, 1)] 表示可以将工件 1 从机器 2 移动到机器 1,将工件 2 从机器 3 移动到机器 2,将工件 3 从机器 1 移动到机器 3。
奖励函数:表示智能体在每个状态下采取每个动作后,环境给予的反馈,可以用一个函数来表示,输入是一个状态和一个动作,输出是一个数值,表示奖励或惩罚的大小,例如,reward(s, a) = -Cmax(s, a) 表示奖励函数的值是负的 Cmax 值,即完成所有工件所需的最短时间,这样可以让智能体倾向于选择能够减少 Cmax 值的动作。
策略:表示智能体在每个状态下选择每个动作的概率分布,可以用一个函数来表示,输入是一个状态和一个动作,输出是一个数值,表示选择该动作的概率,例如,policy(s, a) = softmax(Q(s, a)) 表示策略函数的值是 Q 函数的 softmax 归一化,即根据 Q 函数的值来分配概率,Q 函数的值越大,概率越高。
值函数:表示智能体在每个状态下或者在每个状态下采取每个动作后,能够获得的期望累积奖励,可以用一个函数来表示,输入是一个状态或者一个状态和一个动作,输出是一个数值,表示期望累积奖励的大小,例如,V(s) = max_a Q(s, a) 表示值函数的值是 Q 函数的最大值,即在当前状态下,选择能够获得最大 Q 值的动作后,能够获得的期望累积奖励,Q(s, a) = r(s, a) + gamma * V(s') 表示 Q 函数的值是当前奖励加上折扣后的下一个状态的值函数的值,即在当前状态下,采取当前动作后,能够获得的期望累积奖励,其中 gamma 是一个常数,表示折扣因子,s' 是下一个状态。
然后,初始化强化学习的参数,如初始状态,初始策略,初始值函数,学习率,折扣因子,探索率,终止条件等。
初始状态:表示智能体开始时所处的环境的情况,可以用一个二维矩阵来表示,其中每个元素表示一个机器上的一个工件,每一行表示一个机器,每一列表示一个时间段,每个元素的值表示该工件的编号,如果该位置没有工件,则用 0 表示。例如,[[0, 0, 0, 0, 0], [1, 2, 0, 0, 0], [0, 0, 3, 4, 0]] 表示有三台机器,五个时间段,第一台机器没有工件,第二台机器有工件 1 和 2,第三台机器有工件 3 和 4。
初始策略:表示智能体开始时在每个状态下选择每个动作的概率分布,可以用一个函数来表示,输入是一个状态和一个动作,输出是一个数值,表示选择该动作的概率,例如,policy(s, a) = 1 / len(A(s)) 表示初始策略是均匀分布,即在每个状态下,选择每个动作的概率都相等,其中 A(s) 表示在状态 s 下可行的动作集合。
初始值函数:表示智能体开始时在每个状态下或者在每个状态下采取每个动作后,能够获得的期望累积奖励,可以用一个函数来表示,输入是一个状态或者一个状态和一个动作,输出是一个数值,表示期望累积奖励的大小,例如,V(s) = 0 表示初始值函数都为 0,即在每个状态下,能够获得的期望累积奖励都为 0,Q(s, a) = 0 表示初始 Q 函数都为 0,即在每个状态下,采取每个动作后,能够获得的期望累积奖励都为 0。
学习率:表示智能体在更新值函数时,对新的信息的重视程度,可以用一个常数或者一个函数来表示,输入是一个状态或者一个状态和一个动作,输出是一个数值,表示学习率的大小,例如,alpha = 0.1 表示学习率是一个固定的常数,alpha(s, a) = 1 / N(s, a) 表示学习率是一个递减的函数,其中 N(s, a) 表示在状态 s 下采取动作 a 的次数,这样可以让智能体在初期更加探索,后期更加利用。
折扣因子:表示智能体在计算累积奖励时,对未来的奖励的重视程度,可以用一个常数来表示,输入是一个状态或者一个状态和一个动作,输出是一个数值,表示折扣因子的大小,例如,gamma = 0.9 表示折扣因子是一个接近于 1 的常数,这样可以让智能体更加关注长期的收益,而不是短期的收益。
探索率:表示智能体在选择动作时,以一定的概率随机选择一个动作,而不是根据策略选择一个动作,可以用一个常数或者一个函数来表示,输入是一个状态或者一个状态和一个动作,输出是一个数值,表示探索率的大小,例如,epsilon = 0.1 表示探索率是一个固定的常数,epsilon(s, a) = 1 / t 表示探索率是一个递减的函数,其中 t 表示当前的迭代次数,这样可以让智能体在初期更加探索,后期更加利用。
终止条件:表示智能体在何时停止学习的判断标准,可以用一个布尔值或者一个函数来表示,输入是一个状态或者一个状态和一个动作,输出是一个布尔值,表示是否终止学习,例如,terminate = False 表示终止条件是一个固定的布尔值,terminate(s, a) = (Cmax(s, a) < threshold) 表示终止条件是一个函数,其中 threshold 是一个常数,表示 Cmax 值的阈值,如果在当前状态下,采取当前动作后,Cmax 值小于阈值,就终止学习,这样可以让智能体在达到一定的性能后,停止学习。
然后,开始强化学习的过程,即智能体与环境的交互过程,可以用一个循环来表示,当终止条件为 False 时,继续循环。
在循环中,首先根据当前状态和策略,选择一个动作,可以用一个函数来表示,输入是一个状态,输出是一个动作,例如,choose_action(s) = argmax_a policy(s, a) 表示选择一个能够使策略函数值最大的动作,即最有可能被选择的动作,或者 choose_action(s) = random.choice(A(s)) if random.random() < epsilon else argmax_a policy(s, a) 表示以一定的概率随机选择一个动作,否则选择一个能够使策略函数值最大的动作,即以探索率的概率探索,否则利用。
然后,根据当前状态和选择的动作,执行该动作,观察环境的变化,得到下一个状态和奖励,可以用一个函数来表示,输入是一个状态和一个动作,输出是一个状态和一个数值,表示下一个状态和奖励,例如,take_action(s, a) = (s', r(s, a)) 表示执行动作 a 后,得到下一个状态 s' 和奖励 r(s, a)。
然后,根据当前状态,选择的动作,下一个状态,和奖励,更新值函数,可以用一个函数来表示,输入是一个状态,一个动作,一个状态,和一个数值,输出是一个数值,表示更新后的值函数的值,例如,update_V(s, a, s', r) = V(s) + alpha * (r + gamma * V(s') - V(s)) 表示根据贝尔曼方程,用学习率,折扣因子,当前奖励,和下一个状态的值函数的值,来更新当前状态的值函数的值,update_Q(s, a, s', r) = Q(s, a) + alpha * (r + gamma * max_a' Q(s', a') - Q(s, a)) 表示根据贝尔曼方程,用学习率,折扣因子,当前奖励,和下一个状态的最大 Q 值,来更新当前状态和动作的 Q 值。
然后,根据当前状态,选择的动作,下一个状态,和奖励,更新策略,可以用一个函数来表示,输入是一个状态,一个动作,一个状态,和一个数值,输出是一个数值,表示更新后的策略函数的值,例如,update_policy(s, a, s', r) = policy(s, a) + beta * (Q(s, a) - policy(s, a)) 表示用一个常数 beta 和 Q 函数的值,来更新策略函数的值,使其更接近于 Q 函数的值,或者 update_policy(s, a, s', r) = softmax(Q(s, a)) 表示用 softmax 函数,来更新策略函数的值,使其符合概率分布的要求。
最后,将当前状态更新为下一个状态,继续循环,直到终止条件为 True,结束强化学习的过程。
RL求解JSP示例代码笔记
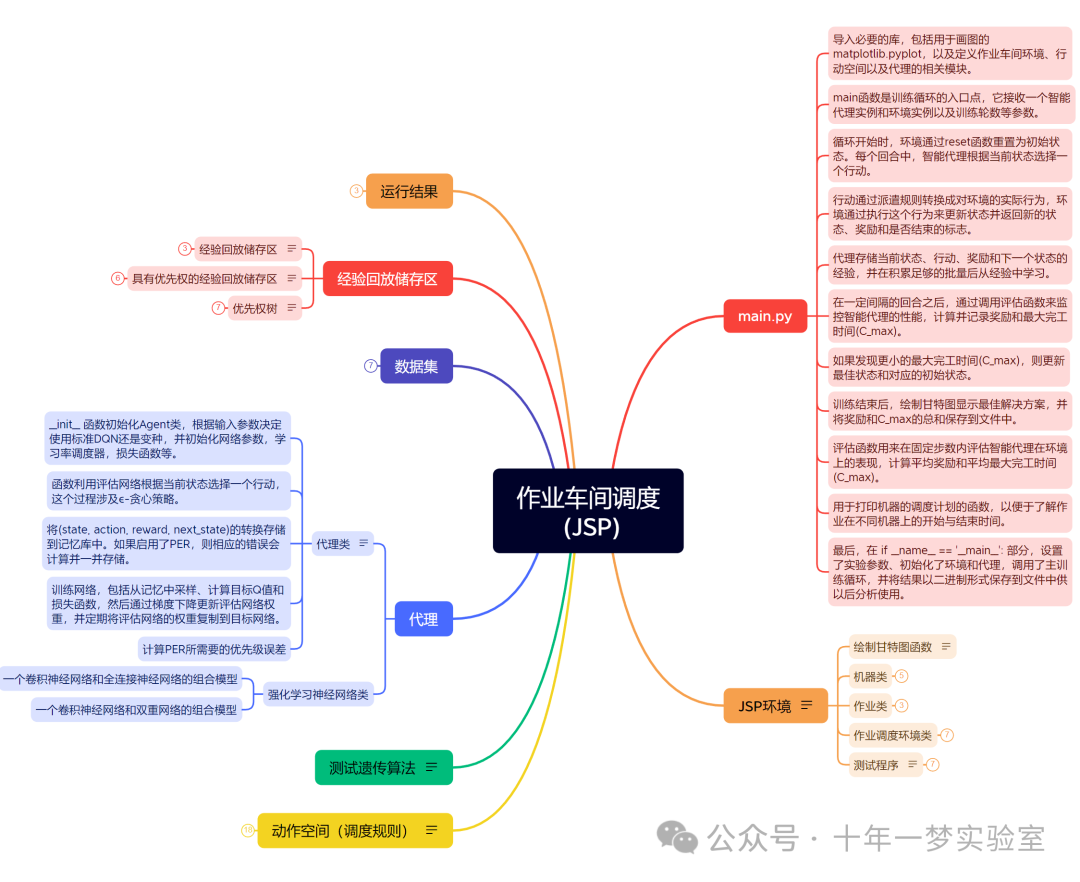
示例代码思维导图

机器调度情况(迭代20次),纵轴-设备号, 横轴-作业工序,
最佳完工时间1442

机器调度情况(迭代200次),最佳完工时间1405
……
关于优先级经验回放区:

结 语
强化学习算法变体很多,后面得深入学习。示例代码为作业车间调度问题提供了基于强化学习的解决框架,包括了环境的初始化、智能代理的决策过程、学习和评估机制以及结果的保存与可视化。对于一些代码的理解还不够透彻需要日后继续学习研究。















 8926
8926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









