







上次给大家介绍了这款软件如何计算新变量以及连续变量和分类变量的处理,今天再给大家介绍一下数据处理模块中的另外一个功能——数据缺失处理。缺失数据处理是数据分析中一个非常重要的环节,以下是几种常见的缺失数据处理方式。
1、数据处理(3)
- 删除法
-
列表删除法:直接删除包含缺失值的整个观测记录。这种方法的优点是简单快捷,不会引入额外的偏差,但缺点是可能导致样本量大幅减少,尤其是当数据中缺失值较多或缺失模式复杂时,可能会丢失大量有价值的信息,影响分析结果的准确性和可靠性。
-
成对删除法:在进行相关性分析或回归分析时,仅删除那些在分析中涉及的变量存在缺失值的观测记录,而保留其他变量完整的观测记录。这种方法可以最大限度地利用数据,但可能导致不同分析之间使用的样本不一致,增加了分析的复杂性,且在某些情况下可能会引入偏差。
-
- 填补法
-
均值填补:用变量的均值来填补缺失值。这种方法操作简单,适用于缺失数据比例较小且数据呈正态分布的情况。但缺点是会降低数据的方差,可能会掩盖数据的真实分布特征,导致分析结果的偏差,尤其是当数据分布偏斜或存在异常值时,均值可能无法很好地代表该变量的典型水平。
-
中位数填补:用变量的中位数来填补缺失值。中位数对异常值不敏感,适用于数据分布偏斜或存在极端值的情况。与均值填补类似,它也会在一定程度上影响数据的分布特征,但相对均值填补来说,对数据方差的影响较小。
-
众数填补:用变量的众数来填补缺失值,通常用于分类变量。它能够保持数据的类别分布特征,但在存在多个众数或数据类别分布不均匀时,可能会导致填补结果不够准确。
-
热卡填补:从数据集中找到一个与缺失值观测记录在其他变量上相似的记录,用该记录的值来填补缺失值。这种方法考虑了数据之间的相似性,填补结果相对更合理,但需要确定合适的相似性度量标准和匹配方法,且当数据集中存在多个相似记录时,可能会引入一定的主观性。
-
回归填补:通过建立回归模型,将缺失变量作为因变量,其他变量作为自变量,根据模型预测缺失值。这种方法能够充分利用变量之间的相关性来填补缺失值,填补结果较为准确,但对模型的假设和拟合效果要求较高,如果模型不准确,可能会导致填补值的偏差。
-
缺失值哑变量替换:具体操作是创建两个新的变量,哑变量(D):表示数据是否缺失。如果数据缺失,D=1;如果数据不缺失,D=0。替代变量(X'):将缺失值用一个常数(如非缺失数据的均值)填充,非缺失值保持不变。在回归分析中,同时将哑变量(D)和替代变量(X')纳入模型。哑变量(D)的系数表示在控制其他变量的情况下,缺失数据的个体与非缺失数据的个体在因变量上的差异。具体来说,D的系数可以解释为“在控制了其他变量的情况下,具有缺失数据的个体其因变量的预测值与具有平均值的个体在因变量上的预测值之差”。替代变量(X')的系数表示在控制其他变量和缺失状态的情况下,非缺失数据对因变量的影响。这种方法更适合于缺失数据对分析结果有重要影响且不能简单删除或填补的场景,但是可能会产生有偏误的系数估计值,因此一般不建议在所有情况下使用。
-
多重填补:先建立一个缺失数据的模型,然后根据该模型生成多个可能的填补值,形成多个完整的数据集,对每个数据集分别进行分析,最后将分析结果综合起来得到最终的结论。这种方法考虑了填补值的不确定性,能够提供更准确的估计和推断,但计算过程相对复杂,且需要对多个数据集的分析结果进行合理的整合。
-
- 基于模型的处理方法
-
最大似然估计:通过最大化数据的似然函数来估计模型参数,同时对缺失数据进行处理。它不需要事先填补缺失值,而是直接在模型估计过程中考虑缺失数据的影响,能够充分利用所有可用信息,得到较为准确的参数估计值,但对模型的假设和分布形式要求较高,且计算复杂度较大。
-
贝叶斯方法:从贝叶斯的角度出发,将缺失数据视为随机变量,通过构建先验分布和后验分布来对缺失数据进行推断和处理。这种方法能够自然地处理填补值的不确定性,提供完整的概率分布信息,但需要合理地选择先验分布,且计算过程通常较为复杂,需要借助马尔可夫链蒙特卡洛(MCMC)等算法进行近似计算。
-
- 利用机器学习算法
-
K近邻填补:KNN插补(K-Nearest Neighbors Imputation)是一种基于实例的缺失值填补方法。其核心思想是利用数据集中与缺失值最接近的K个样本的信息来填补缺失值。这种方法简单易实现,能够较好地捕捉数据中的局部结构和相似性,但对K值的选择和距离度量方法较为敏感,且当数据维度较高时,计算效率可能会降低。KNN插补能够利用数据中的局部模式来填补缺失值,因此通常比简单的均值或中位数填补更准确。KNN插补的计算复杂度较高,尤其是在数据集较大时。不同的K值会对插补效果产生影响。通常需要通过实验选择最优的K值。例如,可以通过交叉验证来评估不同K值下的模型性能。选择合适的K值和距离度量方法对填补效果至关重要,需要根据具体数据情况进行调整。
-
决策树填补:利用决策树算法对数据进行分类或回归,根据决策树的规则来预测缺失值。决策树能够自动处理变量之间的非线性关系和交互作用,填补结果具有一定的可解释性,但可能会受到决策树模型的过拟合或欠拟合问题的影响。
-
随机森林填补:基于随机森林算法,通过构建多个决策树并综合它们的预测结果来填补缺失值。随机森林能够提高填补的准确性和稳定性,对数据中的噪声和异常值具有一定的鲁棒性,但计算复杂度较高,且需要合理地设置随机森林的参数,如树的数量、树的深度等。
-
- 特殊情况下的处理方法
-
时间序列数据中的缺失处理:对于时间序列数据,可以根据时间序列的特性采用特定的方法,如线性插值、样条插值等,根据已知的时间点上的数据值来估计缺失时间点的值;也可以使用时间序列模型,如ARIMA模型等,对缺失数据进行预测和填补。
-
空间数据中的缺失处理:在处理空间数据时,可以利用空间自相关性,采用空间插值方法,如克里金插值等,根据已知空间位置上的数据值来估计缺失位置的值,以保持空间数据的连续性和完整性。
-
了解了缺失数据处理的重要性和方法,接下来我们看看风锐软件如何实现基本的缺失数据处理吧。
13)数据缺失处理
a)数据缺失查看
首先,我们需要了解有哪些变量有缺失,缺失占比是多少?在风锐中直接点击数据缺失查看就可以。出来的结果有图和表两种方式。
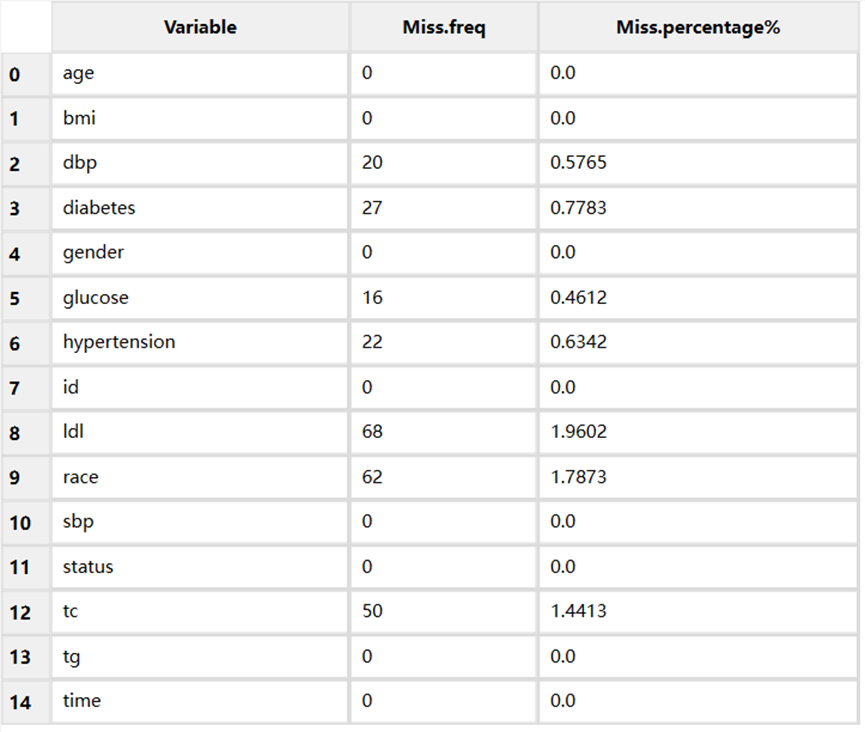
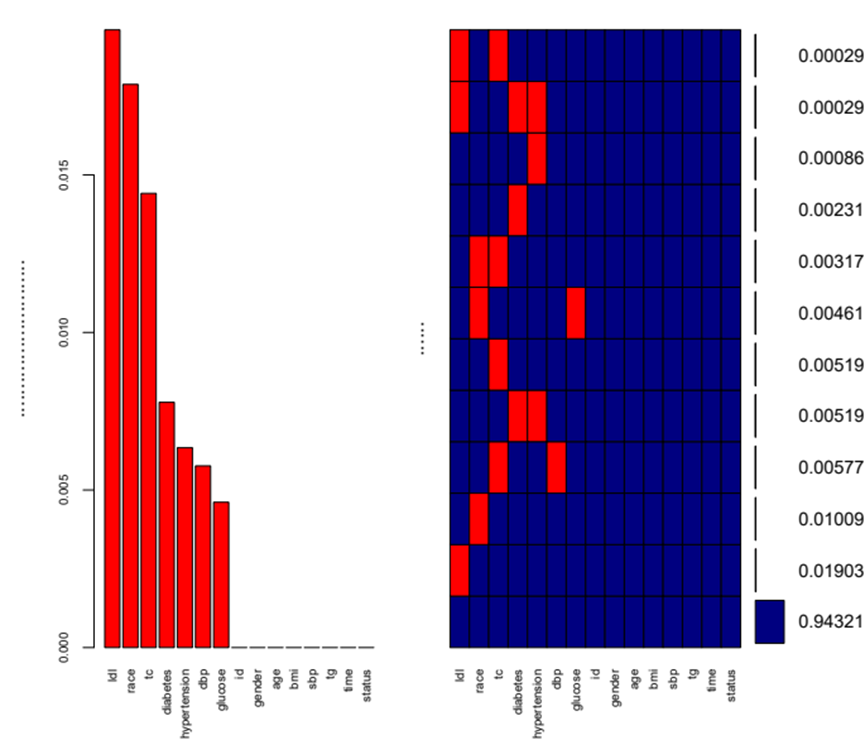
上图左侧显示了我们的数据中哪些变量有缺失,右侧显示了缺失变量占比。比如ldl缺失占比约2%。
b)缺失值简单替换
现在我们已知连续变量中ldl、tc、dbp和glucose有缺失,可以对连续变量的缺失值进行简单的替换,风锐中可以选择替换成mean(均值)/ median(中位数)/ mode(众数)/9/other,其中9一般在数据库中代表缺失,也可以选择other自定义数值。
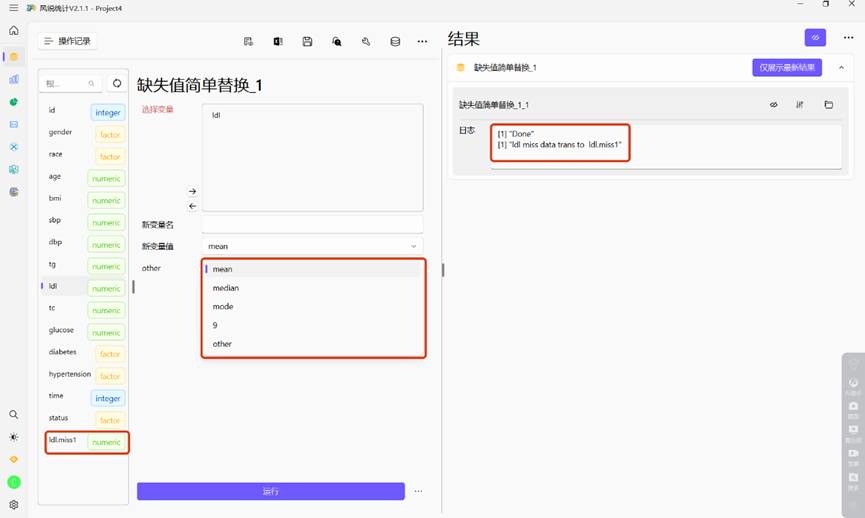
上图中选择将ldl中的缺失值替换成均值后,软件生成了新变量ldl.miss1,后续分析时使用这个变量即可。
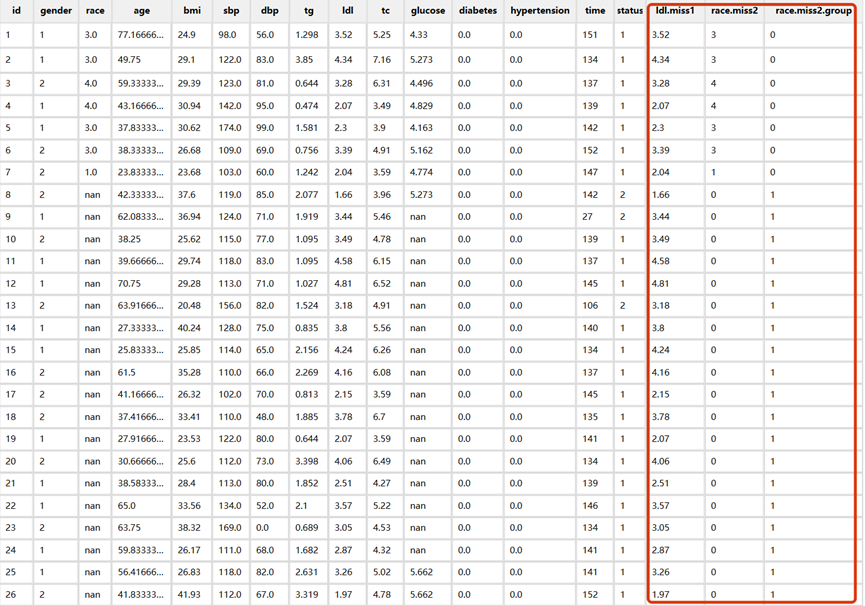
c)缺失值哑变量替换
分类变量中race、diabetes和hypertension有缺失,我们对race进行哑变量处理后,会发现系统生成了两个新变量。另外两个变量用同样的方法处理即可。
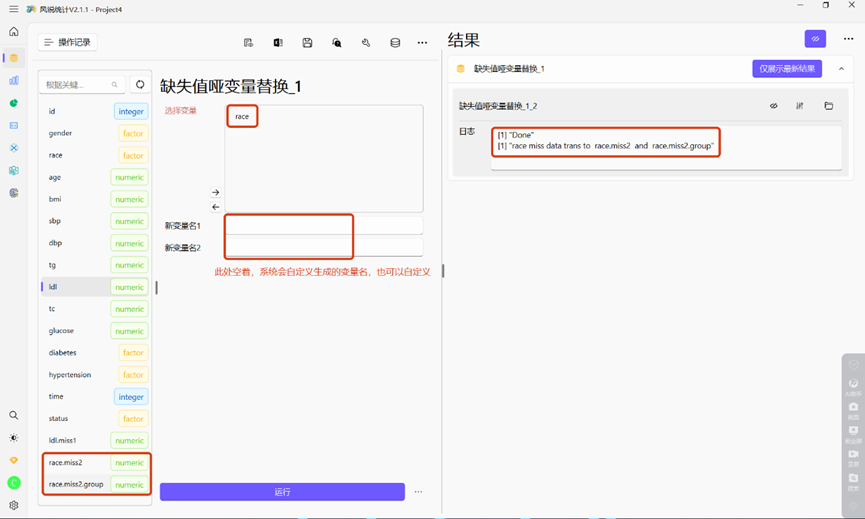
生成的新变量如下图所示:
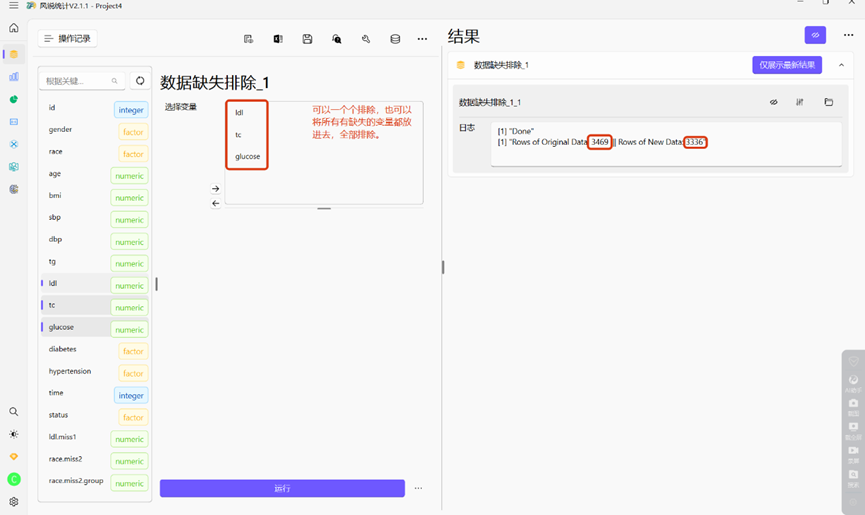
d)数据缺失排除
当然,如果你的样本量非常大,觉得数据缺失处理起来非常难,我们也可以直接删除所有缺失的数据。可以逐个排除缺失变量,也可以将所有有缺失的数据一起排除。
e)缺失值knn插补
风锐统计中我们需要在选择变量组中输入需要插补的缺失变量以及其他预测协变量,至少选择2个变量用于拟合KNN插补模型。
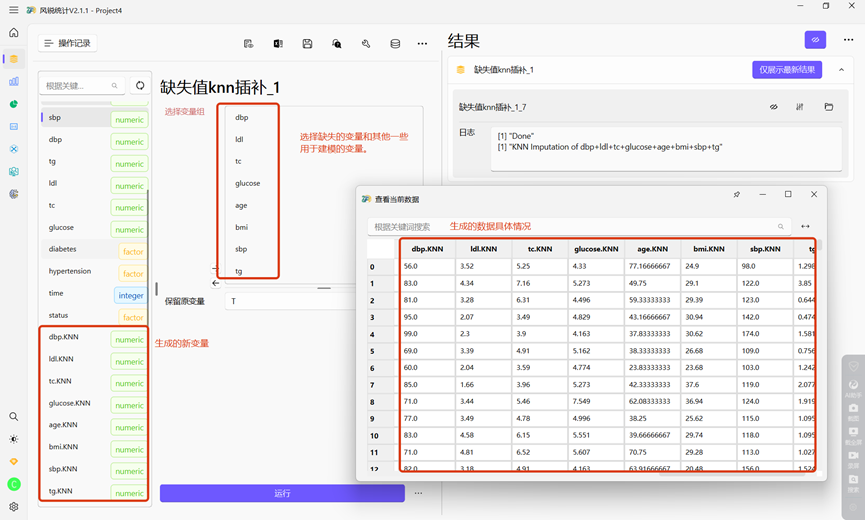 通过knn插补之后,软件会生成带.KNN的新变量,后续进行数据分析时用这几个新变量即可。
通过knn插补之后,软件会生成带.KNN的新变量,后续进行数据分析时用这几个新变量即可。
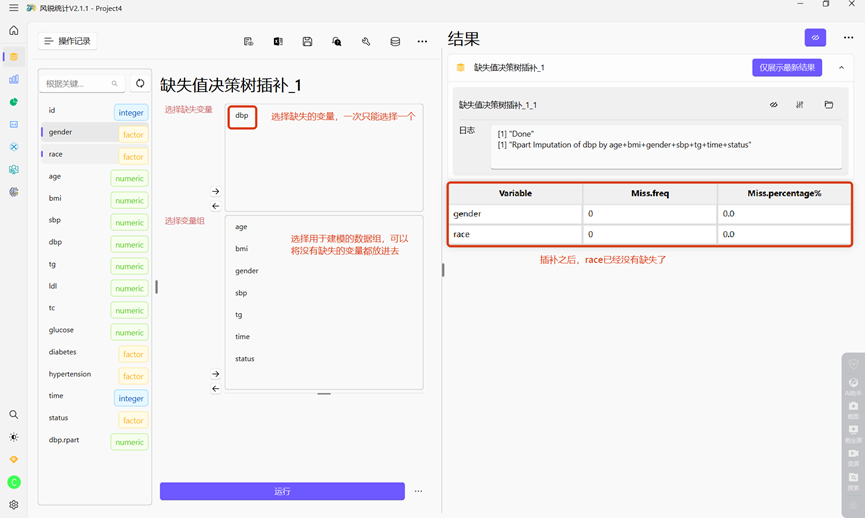
f )缺失值决策树插补
决策树插补适用于数据集较小且特征之间存在复杂关系的情况,其基本原理是将缺失值视为目标变量,将其他非缺失的特征作为输入变量,构建决策树模型,然后利用该模型预测缺失值。
g)插补缺失数据集
如果你觉得一个个去处理缺失数据特别麻烦,风锐也提供了一键多重插补缺失数据集的方法。具体操作如下图所示,我们可以选择插补出来的任意一套数据进行后续的分析。
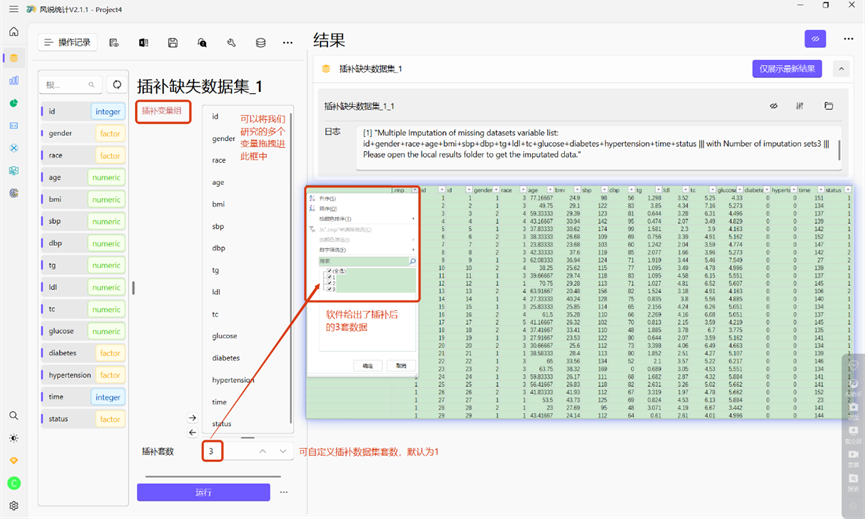
今天给大家介绍了数据处理中非常重要的缺失数据的处理方式,风锐软件给到了缺失值简单替换(可替换成均数、中位数、众数以及自定义)、缺失值哑变量替换、缺失值排除、缺失值knn插补、缺失值决策树插补以及多重插补缺失数据这6种方法,在做数据分析之前,干净整洁的数据集是必不可少的,大家也可以下载软件,动手操作起来,开启自己的科研之路。
官网链接:临床科学家![]() https://pc.clinicalscientists.cn/#/index
https://pc.clinicalscientists.cn/#/index
软件下载链接:

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









