









线性神经网络
线性神经网络和单层感知机非常相似,输入层、输出层甚至是误差迭代函数都相同,唯一的区别就是他们的传输函数不同。
回顾一下
单层感知机的传输函数:
y=sgn(x)
sgn{
x>0 y=1
x<=0 y=0
}
这是二值的函数,所以只能解决二分类问题。
而线性神经网络的传输函数:
sgn{
y=x;
}
这就决定了线性函数可以拟合线性方程,而且比感知机拟合出来的误差小的多得多。
线性神经网络的误差迭代
线性神经网络用的是LMS(最小均方)算法,并且利用梯度下降法进行收敛,效果很好。
我们假设 实际输出量是y 预期输出量是d
误差e就是:e=d-y
我们把代价函数设置为,L=1/2*e^2 ,因为e^2是二次函数,最小极值点必定是最小点,不容易陷入局部最小。
我们把误差方程展开:
假设x为输入量,w为权值。
y=wx;
e=d-wx;
现在我们对L求w的偏导:
dL/dw=e*(de/dw);
de/dw=-x;
dL/dw=-x*e;
学习率为sigma,并且把学习单位设为梯度下降的程度。就有如下迭代公式:
w=w+sigma*x*e;
是不是和上一节我们讨论的单层感知机很像?
实现线性神经网络(Matlab非API)
拟合线性方程
下面我们就利用matlab来实现一下怎样拟合出线性方程。
首先我们要创建x,y变量:
我们给y加入噪声来干扰拟合:
x=-5:1:5;
y=6*x+3;
y=y+randn(1,length(x)); %加入噪声
x=[x;
ones(1,length(x))]; %加上偏置b输出看一下
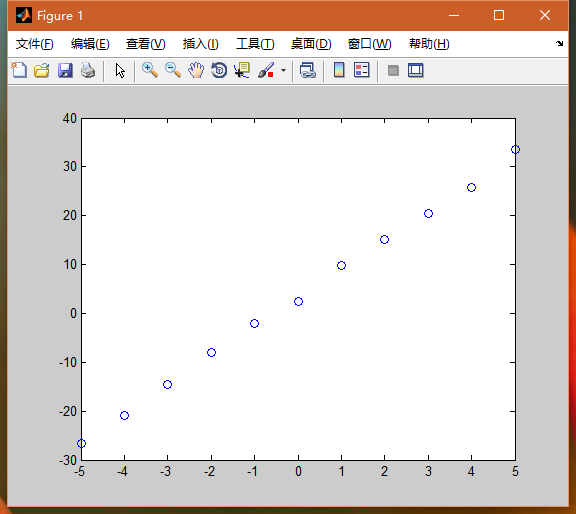
肉眼也看得出这是一条不直的线,但均匀分布在y=6*x+3周围。
第二步,设置参数
w=[0,0]; %加上偏置一共二维向量
lr=0.01; %学习率
maxiterator=20000;
wr=[10,10]; %前一次迭代的权值w
第三步,迭代使代价函数最小
for i=1:maxiterator
fprintf('迭代次数 %d',i);
t=w*x;
e=y-t;
e %输出误差
if (sum(e.^2)/length(e))<0.5
break;
end
w=w+lr*e*x';
w %输出w权值
if abs(sum((wr-w).^2))<10^-20;
break;
end
wr=w;
end
运行一下来看一下输出:
迭代次数 189
e =
-0.0118 0.3412 -0.5452 -1.3498 0.3252 0.0444 1.2586 0.8142 1.0187 -0.8305 -1.0650
w =
6.0471 2.8934
可以看出,权值与真实值非常接近。
我们再来看一下输出图:
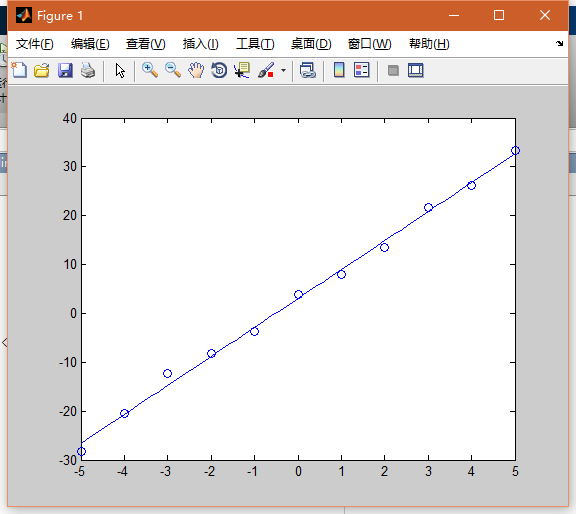
非常的均匀!!
这里我们可以对学习率进行改进
我们知道,学习率在整个公式里面处于一个非常重要的地位,学习率过大会导致一直在极值附近震荡,学习率过小会导致收敛过慢,如果我们可以写一个动态学习率,使一开始离极值远学习率高而在极值领域时减小学习率让收敛更加精准。
lr=0.9999^i*lr;
i表示迭代次数,我们将迭代次数作为依据,让学习率以指数速度下降。
做个前后对比。
我们把初始学习率定为0.02,用同一组数据:
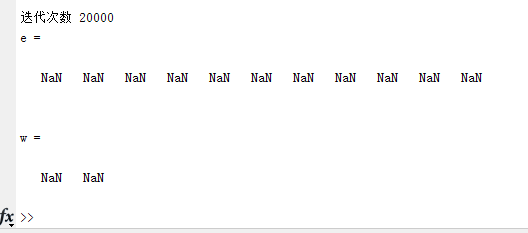
我们发现以前 的方法已经无法收敛了
再看一下新的方法:
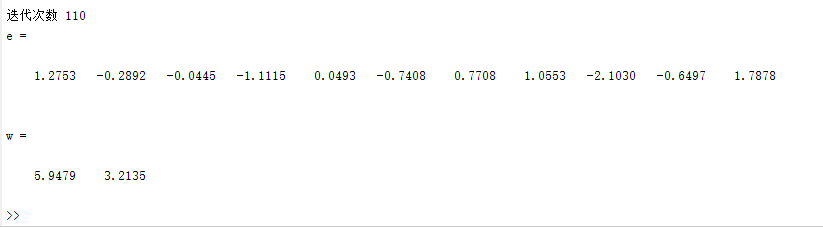
仅仅110次迭代就已经收敛。
我们再试试学习率为0.01固定不变:

结果和前面一样,但却需要190次才能收敛。
这就说明了新的方法对高速收敛有着独到的优势!!
结束语
经过这次学习,我们已经可以解决一些线性拟合问题,并且优化了学习率,接下来我们将会涉及非线性拟合。















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









