









BP神经网络
前面我们所讲的几节都是线性神经网络,都无法解决线性不可分的问题,今天我们就来学习非常非常经典的非线性多层前向网络——误差反向传播网络(BP——Error Back Propagtion)。
BP神经网络和前面所说的线性神经网络有什么区别呢?
1.隐含层可以不唯一,这就大大提高了非线性能力。
2.隐含层节点不唯一,也就是一层可以有多节点连接。
3.隐含层的传输函数为sigmoid函数,而非普通的线性函数,输出层的传输函数为线性函数
4.引入多层误差调整,原有的单层误差传播无法解决多层误差的调整。
5.引入动量的概念,避免BP算法的缺点(陷入局部最小值)。
一、首先我们来了解一下什么是SIGMOID函数
在bp网络传输函数的选择中,首要的就是函数可微,也就是函数平滑。其次,我们需要找到一个函数在比较大的x值下有较小的梯度,防止函数直接震荡而无法收敛,并且,其值可以归一化在我们预期的二值之间。
比如我们取预期二值为0,1。那么我们就可以用一个函数满足上面这些条件。
函数:1/(1+exp(-x))
这个函数称为log-sigmoid函数
我们来看一下他的图像:
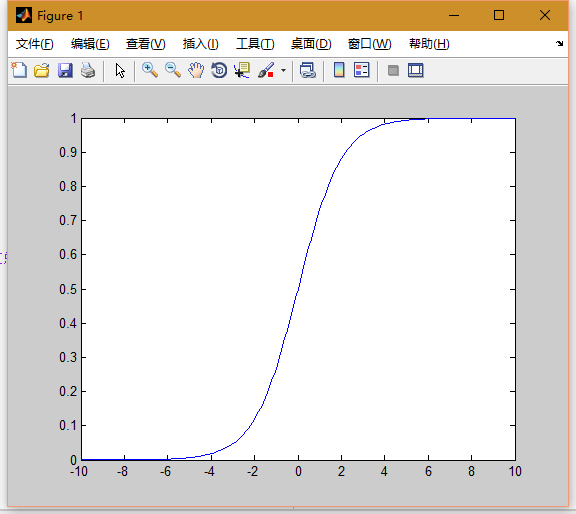
这个函数的特点是在数值很大的时候可以降低他们的梯度,而在数值较小的时候可以增加他们的梯度加快收敛速度。
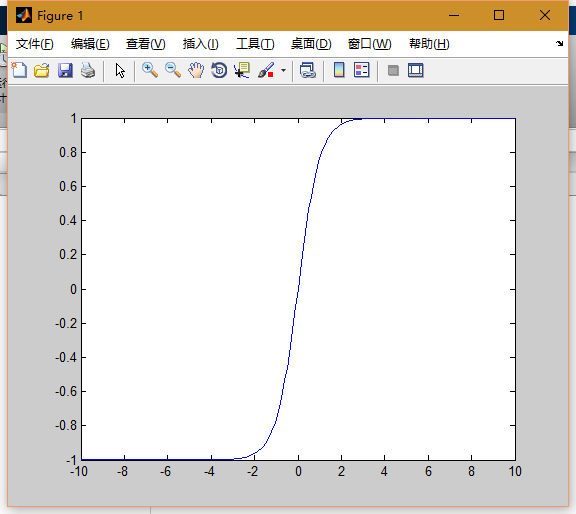
同理,如果把函数归在(-1,1)下就有如下函数:
2/(1+exp(-2*n))-1
我们来看一下他的图像
二、解析多层的误差传播算法
如果想要误差从顶层向下传,那么每一层都要有y=wx+b这个函数式,然后对w利用梯度下降法做调整。
1.顶层也就是输出层,预期输出我们设为label,实际的输出层输出我们设为out2.
误差设为err:err=label-out2;
我们把误差代价函数设置为ed=1/2*(err^2);
梯度我们设为delta
学习率设置为sigma
隐含层输出为out1
隐含层权值为w2
那么权值迭代公式为:w2=w2 + sigma * delta;
这里未知量就是delta,delta就是代价函数对自变量w2的导数。
这里我们展开为链式求导。
d(ed)/d(w)=
[d(ed)/d(err)] * [d(err)/d(out2)] * [d(out2)/d(out2_temp)] * [d(out2_temp)/d(out1)]
因为传输函数在输出层是线性的,所以第三项为1。
=err * (-1) * 1 * out1;
2.上面的顶层还算简单,下面是隐含层的梯度
误差未知 我们设为errnon
输入层输入为input
输入层的权值为w1
权值迭代公式如下: w1=w1+sigma * delta;
这里的未知量还是delta,我们再次对他求导:
导数为-[d(errnon)/d(input)] * [d(out1)/d(out1_temp)]
第一项未知:所以只能利用上一层梯度造成权值变化的影响代替
所以第一项写为 :err*w2
第二项为logsigmoid的导数。
最后迭代式如下:
w1 = w1 + sigma * err * w2 * dlogsig(out1_temp,out1) * input;
三、动量稳定收敛法
对迭代式加入动量因子:
deltaw=sigma * ( 1 - alpha ) * delta + alpha * deltaw_forward;
delta_forward是前一次迭代差;
alpha就是动量因子。
加入动量因子的变化:
1.当函数在大梯度时,需要更高的下降梯度,而我们的学习率是固定的,现在加入上一次的迭代改变量后,可以加大权值下降量,更快的收敛。
2.当函数在局部最小值而非全局最小值时,动量因子可以让梯度保持,减缓收敛速度,这就大大减小了陷入局部最小值的几率。
四、Matlab实现(非API)
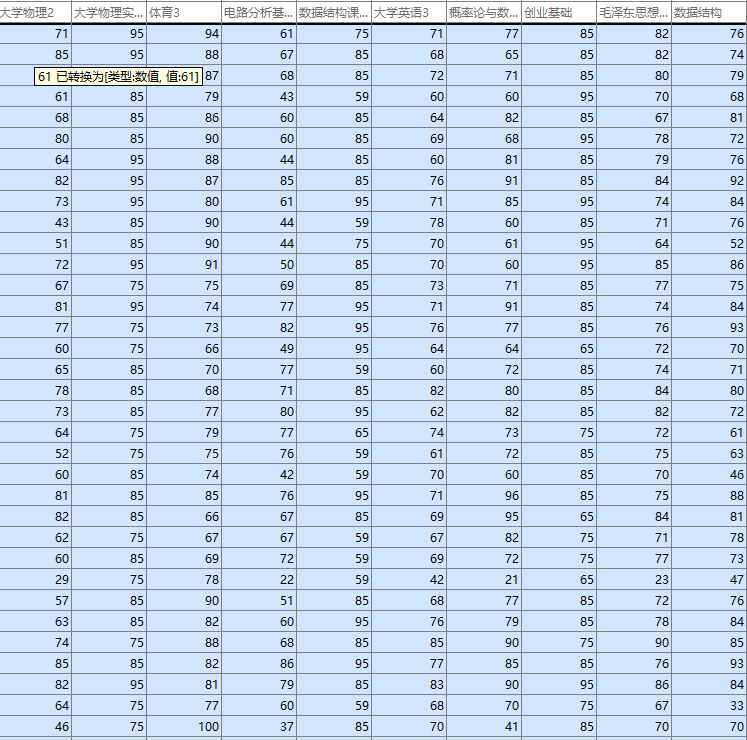
第一步:读取一些数据,班上男女生的各科成绩作为data,男女性别作为label,寻找各科成绩与性别的关系。
function [data,label] = getdataxls( filename)
data=xlsread(filename,'c3:l26');
label=zeros(1,length(data(:,1)));
for i=13:24
label(i)=1;
end
end看一下这些毫无规律的数据
接下来需要将这些数据归一化到同一个单位下,并且对他们进行均值平移,方差归一化。
因为有b向量,所以我们要在最后一行加上全为一的维度。
function [ dataone ] = toone(data )
dataavg=sum((data'))/length(data(1,:));
for i=1:length(data(1,:))
data(:,i)=data(:,i)-dataavg';
end
datastd=zeros(1,length(data(:,1)));
for i=1:length(data(:,1))
datastd(i)=std(data(i,:));
data(i,:)=data(i,:)/datastd(i);
end
dataone=[data;
ones(1,length(data(1,:)))];
end归一化后的数据

定义一些初始变量
maxiterator=10000;
eb=0.001;
sigma=0.1; %学习率
alpha=0.8; %动态因子误差的迭代:
w2foward=net.w2;
w1foward=net.w1;
for i=1:maxiterator
input1=net.w1*data;
out1=logsig(input1);
input2_temp=[out1;
ones(1,length(out1(1,:)))];
input2=net.w2*input2_temp;
out2=input2;
err=label-out2;err
see=sumsqr(err);out2
if see<eb
break;
end
deltaw2=sigma*(1-alpha)*(err)*input2_temp'+alpha*w2foward;
deltaw1=sigma*(1-alpha)*(net.w2(:,1:end-1)'*err.*dlogsig(input1,out1))*data'+alpha*w1foward;
if i==1
deltaw2=sigma*err*input2_temp';
deltaw1=sigma*(net.w2(:,1:end-1)'*err.*dlogsig(input1,out1))*data';
end
net.w2=net.w2+deltaw2;
net.w1=net.w1+deltaw1;
w2foward=deltaw2;
w1foward=deltaw1;
if sumsqr(errf-err)<10^-5
break;
end
end这时让我们来检测一下我们的正确率:
前12个应该为女生;后面的应该全部是男生;
[chdata,chlabel]=checkdata('成绩汇总.xlsx');
chdata=chdata';
chdata=toone(chdata);
chinput1=net.w1*chdata;
chout1=logsig(chinput1);
chinput2_temp=[chout1;
ones(1,length(chout1(1,:)))];
chinput2=net.w2*chinput2_temp;
cherr=chlabel-chinput2;
ch=char(1,42);
for i=1:42
if(chinput2(i)>0.5)
ch(i)='男' ;
else
ch(i)='女';
end
end前12个女生:
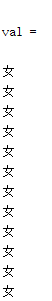
后面的男生:


42个样本 错误的为5个
准确率在88%左右;
看一下误差迭代图:
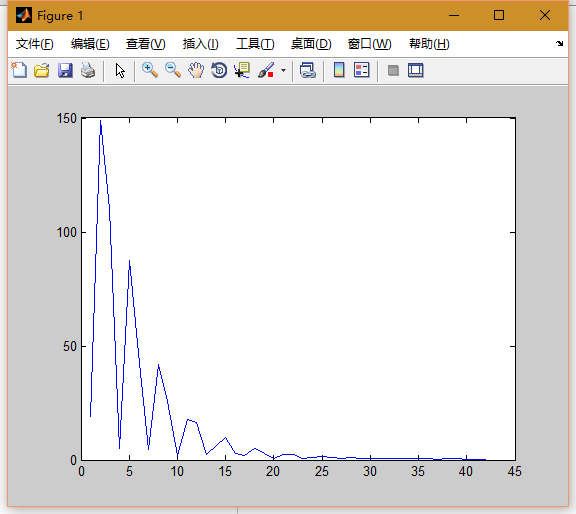
结束语
BP神经网络对非线性拟合的比较好,并且加入了动量算法后变得更加的鲁棒,但是依然有因为初始权值不好而导致训练错误率非常高的情况,而这个问题已经在deeplearning中解决了很多,以后我们将更加深入的学习。















 2305
2305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









