







本文是《统计学习方法》李航著学习笔记。
k近邻法是一种基本的分类与回归方法,这里主要讨论分类问题的k近邻法。
k近邻算法的有关内容,都基于监督学习的训练数据集的各实例点的类确定情形!
以下讨论主要分三部分:(1.)应用k近邻算法做预测,(2.)k近邻模型的基本构成要素,(3.)k近邻算法的实现——kd树。
应用k近邻算法做预测:
这里说做预测,显然模型已经确定,只需对新的输入实例点应用k近邻模型进行类别判断。即不用再考虑此处训练实例点的类别是怎么分类的,怎么得到这样的分类的过程,这一问题显然属于模型的学习过程,而不是预测新实例点时应该有的情况。

k近邻模型的基本构成要素:
k近邻模型的三个基本要素——距离度量、k值的选择、分类决策规则。
即当训练集、距离度量、k值的选择、分类决策规则确定后,对于任何新的输入实例,它的类唯一确定。
单元:
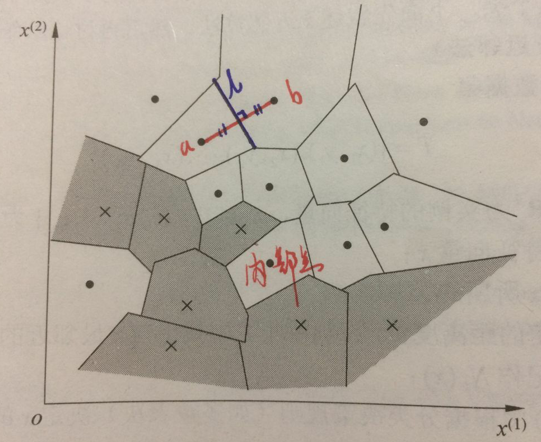
引入单元的概念是为了形象化表示k近邻模型中训练实例点的类别对特征空间的划分,尤其对于“最近邻法”,落某个单元内的“预测实例点”类别,就是该单元内“训练实例点”的类别。

距离度量:
距离度量这里仅给出几个公式,有关性质不过多赘述,感兴趣的人可以参看《泛函分析》教材。
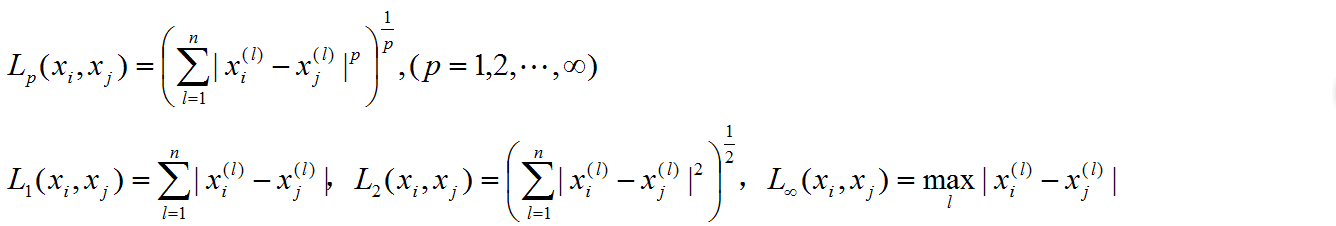
需要注意的是,不同的距离度量方式得到的k个最近邻点可能有所不同。
k值选择、多数表决规则:
k值选择反映了“近似误差”与“估计误差”间的权衡,可以利用交叉验证选k,下面陈述S折交叉验证选k的具体过程:

k值较小表示整体模型较复杂,易发生过拟合;k值较大,整体模型变简单,但较远不相似的训练示例也对预测起作用,使预测发生错误。
k近邻算法的实现——kd树:
对训练数据的k近邻个点进行线性扫描计算量过大,为提高效率减少计算距离的次数,考虑用特殊的数据结构存储训练数据,kd数方法就是满足这一需求的一种算法。
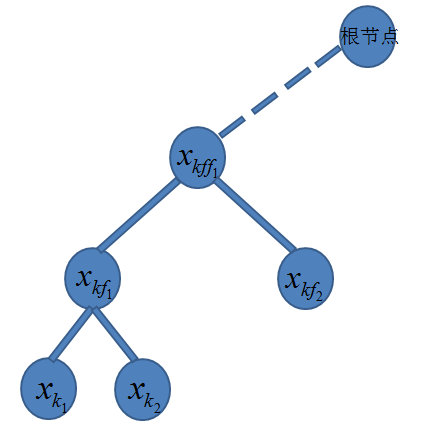
首先,构造kd树,以便于对于任意给定的预测实例点查找其对应的k个近邻点:


特征空间划分、kd树对应示意图:

其次,搜索kd树,演示对于新给定的实例点,根据kd树结构寻找k个近邻点的过程(这里以最近邻为例说明搜索过程):


















 3318
3318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









