







1 动机
在大规模推荐系统中,模型需要从数以百万或数十亿计的候选项目中筛选出用户可能感兴趣的项目。推荐模型在训练过程中通过正样本(用户已互动的项目)和负样本(用户未互动的项目)之间的对比来学习用户的偏好。然而,由于候选项目数量庞大,使用全部未互动项目作为负样本会导致计算成本过高。因此,负采样技术被广泛应用,目的是从大量未互动项目中选择少量的负样本,以平衡训练效果和计算效率。
缺陷:
传统的随机负采样方法尽管简便,但往往强化了流行度偏差,即使模型在热门项目上表现更佳,却难以推荐长尾项目。此外,不同的负采样策略在实际应用中各有利弊,例如流行度采样可能导致流行项目过多曝光,而局部采样(如批内采样)虽然计算效率高,但容易忽略全局分布中的负样本多样性。
2 贡献
-
系统性地分析与实现多种负采样方法:首次在序列推荐领域内系统地实现和分析了六种不同的负采样方法,包括随机采样、流行度采样、批内采样、混合采样、自适应采样和自适应混合采样。
-
引入流行度感知的推荐评价指标:引入了流行度感知的推荐指标,将项目按流行度划分为头部、中部和尾部,并分别进行评估。
-
负采样策略对推荐偏差的影响研究:关注不同负采样策略对推荐系统偏差(尤其是流行度偏差)的影响。通过实验分析,揭示了各采样策略在热门项目和长尾项目上的差异表现,从而提出了减缓推荐偏差的方法。
3 负采样
全局采样
-
随机采样(Random Sampling)
- 原理:排除用户序列中已经存在的项目,根据项目频率或逆项目频率为每个用户均匀随机选择负项目。
- 优缺点:简单直接、计算开销低,但可能包含过多简单负样本,导致模型对流行项目的偏好增强,削弱对长尾项目的推荐效果。
-
基于流行度的采样(Popularity-Based Sampling)
- 原理:根据项目的流行度选择负样本,优先选择较热门的项目。
- 优缺点:能提升模型对热门项目的预测准确度,但易加剧对热门项目的偏好,进一步弱化长尾项目的推荐。
局部采样
- 批内采样(In-Batch Sampling)
- 原理:从当前训练批次中的项目选择负样本,在每个批次中,所有未互动项目均作为负样本。
- 优缺点:计算效率高,但因依赖批次数据分布,可能导致多样性和全局性不足,尤其在数据稀疏场景中效果有限。
混合采样
-
混合采样(Mixed Sampling)
- 原理:结合全局采样和批内采样,从全局项目池和当前批次项目中混合选择负样本。
- 优缺点:兼顾全局和局部信息,提升负样本多样性,减少全局采样的计算成本,提升模型的泛化能力。
-
自适应采样(Adaptive Sampling)
- 原理:动态调整负样本选择策略,优先选择模型可能误分类的项目作为负样本。
- 优缺点:提升模型对难区分项目的学习效果,但计算成本高,因为需要持续计算每个负样本的预测得分。
-
自适应混合采样(Adaptive Mixed Sampling)
- 原理:结合自适应采样和混合采样的优点,在全局和当前批次项目池中选择负样本,并进一步筛选困难负样本。
- 优缺点:兼顾全局信息、局部信息和样本难度,实现更加精准和多样化的负样本选择,在推荐效果和计算效率之间取得平衡。
4 评估指标
对HR(Hit Rate)指标进行了改进,以便更好地衡量负采样方法在推荐系统中的表现。特别关注了流行度对推荐性能的影响,从而帮助理解不同负采样策略在热门项目和长尾项目上的表现差异。
1. 改进后的Hit Rate
基于项目流行度进行分层。项目被分为三类:头部(Head)、中部(Mid)和尾部(Tail),根据它们在训练数据集中出现的频率划分。这种基于流行度的分层评价可以反映模型在不同流行度项目上的表现,有助于评估模型是否在流行项目上表现过好,或者是否能够合理推荐冷门项目。
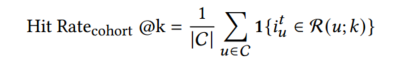
c为该项目的受欢迎程度队列(交互频率),分为头部,中部和尾部![]()
2. 平衡
使用一个称为“平衡”的新度量,基于Gini系数来评估由不同负抽样方法产生的所有模型的头部、中部和尾部队列之间的准确性分布,该度量定义为:
![]()
5 实验部分
-
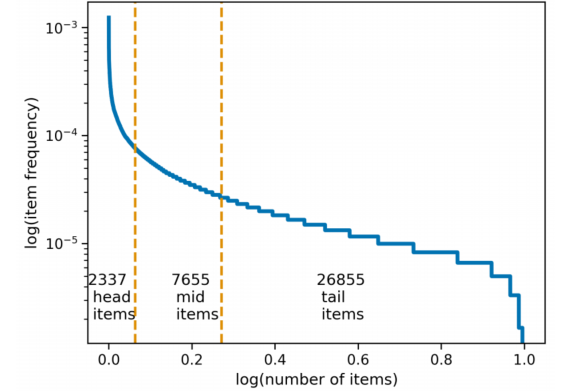
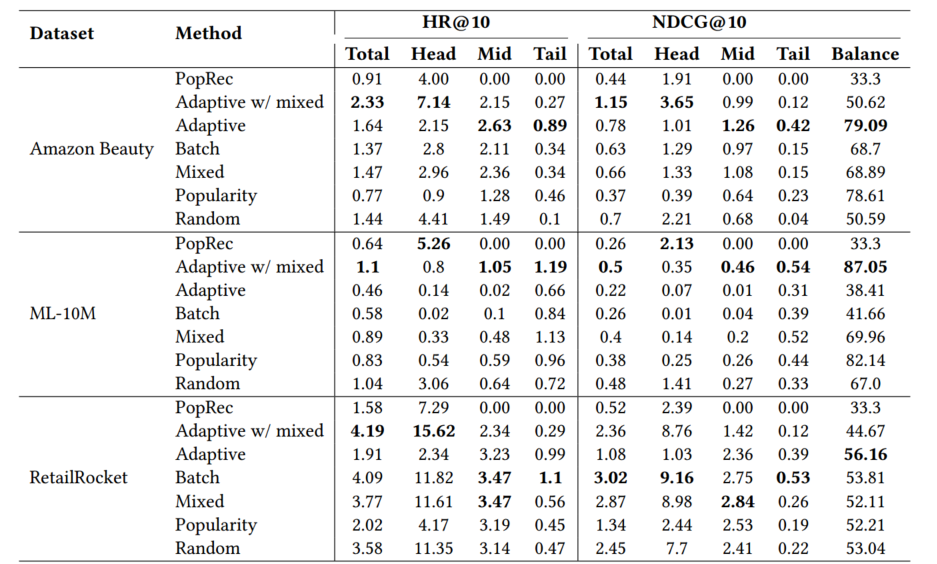
MovieLens 10M:该数据集头部和中部的项目较少,但尾部项目数量庞大。在此数据集上,随机采样和自适应混合采样的表现较好,既达到了较高的准确率,也在推荐平衡性上表现良好。而批内采样则表现较差,可能是因为该方法降低了采样的随机性,容易对流行项目造成过度惩罚。
-
Amazon Beauty 和 RetailRocket:这两个数据集中,项目的多样性较高,尤其在中部和尾部区域。在Amazon Beauty数据集中,用户偏好更倾向于小众项目,因此自适应采样和自适应混合采样的效果尤为突出。这些方法更好地选择了困难负样本,能够提升推荐系统在冷门项目上的推荐精度。(适用于淘宝、天猫)
随机负抽样强化了流行偏差:上图RNS实现了较高的模型性能,但强化了数据中的流行偏差。强化导致模型对头部项目的表现比中间或尾部项目要好得多。具体来说,头部NDCG与尾部NDCG的比值大于1。随机抽样增加了从不受欢迎的项目中抽样的可能性,并从数据中继承了受欢迎的偏见。
基于流行度的采样:可以通过增加中队列和头部队列的HR@10来帮助减少性能不平衡,但以头部队列的低HR@10为代价。因此,与随机抽样相比,它显著降低了模型的整体性能(NDCG)。
自适应混合采样实现了高的模型性能:在上图,自适应混合采样不仅达到了高模型性能,还在不同流行度层次(头部、中部和尾部项目)的推荐平衡性上表现良好。相比之下,随机采样和批内采样等传统方法在热门项目上表现更佳,但会加剧流行度偏差,而自适应混合采样在缓解这种偏差的同时保持了较好的推荐精度。
自适应混合采样:结合了全局随机采样和批内采样,即一部分负样本从当前训练批次中选择(批内采样),另一部分则从全体项目池中随机选择(全局随机采样);在选择完初步的负样本之后,自适应混合采样会进一步筛选“困难”负样本。计算负样本的预测得分,并选择那些得分接近正样本得分的项目作为最终的负样本,同时随着模型的训练动态调整负样本的难度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









