






1机器学习分类
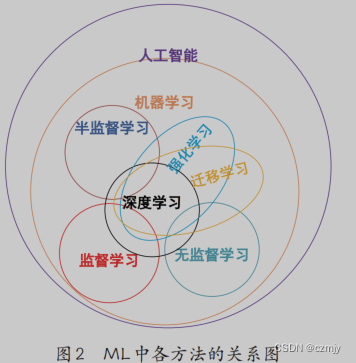
根据训练样本和反馈方式的不同,机器学习分为监督学习、无监督学习、半监督学习、深度学习、强化学习和迁移学习六类。
1.1.监督学习(Supervised learning,SL):提供人为标注的监督信号
1.2.无监督学习(Unsupervised learning,UL):是指从无标注数据中学习预测模型的机器学习方法,其本质是学习数据中的统计规律或潜在结构。无监督学习方法:聚类、K均值、PCA等
1.2.1自监督学习(Self-supervised Learning):是指直接从大规模的无监督数据中挖掘自身监督信息来进行监督学习和训练的一种机器学习方法(可以看成是无监督学习的一种特殊情况。PS:也有人看成是有监督学习的一种特殊情况),自监督学习需要标签,不过这个标签不来自于人工标注,而是来自于数据本身。自监督的监督信号来源于数据本身的内容,也就是自己给自己监督信号(self的含义)。也可以认为是实例级别的标注,每个样本是一个类。自监督学习方法:基于上下文、基于时序、基于对比等。
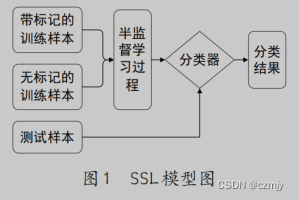
1.3.半监督学习(Semi-Supervised Learning,SSL) :用少量标记的大量未标记的数据啦执行有监督或无监督的学习任务。
1.4.
深度学习(Deep learning,DL):
训练样本是有标签
的,试图使用复杂结构或由多重非线性变换构成的多
个处理层对数据进行高层抽象
1.5.
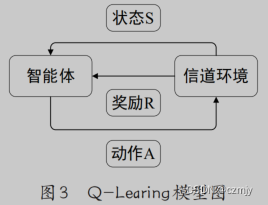
强 化 学 习 (Reinforcement learning,RL) : 训练和
UL同样都是使用未标记的训练集,其核心是描述并解
决智能体在与环境交互的过程中学习策略以最大化回报或实现特定目标的问题。
SL或 UL主要应用的是统计学,RL则更多地使用了随机过程、离散数学等方法。常见的RL代表算法:Q-学习算法、瞬时差分法、自适应启发评价算法等。
1.6.
迁移学习(Transfer Learning,TL):根据任务
间的相似性,将在辅助领域之前所学的知识用于相似
却不相同的目标领域中来进行学习,有效地提高新任
务的学习效率。迁移学习可分为基于样本、基于参数、
基于特征表示和基于关系知识的四类迁移方式。
1.7.各学习方法之间的联系
SL、SSL和 UL是传统 ML 方法;DL提供了一个更强大的预测模型,可产生良好的预测结果;RL提供了 更快的学习机制,且更适应环境的变化;TL突破了任 务的限制,将 TL应用于 RL中,能帮助 RL更好地落实到实际问题。
RL的训练通常在
自有规则的虚拟环境中进行,现实中要复杂得多;神经
网络的训练太费时,所需数据集不统一。因此,用TL将
已经训练好的模型运用于其他任务上变得越来越重要。
2.机器学习算法
2.1 支持向量机算法(SVM)
SVM 是一种对数据进行二元分类的广义线性分类器,其决策边界即对学习样本求解而得到的最大边 距超平面,它的算法就是求解凸二次规划的最优化算法,关键在于求得分类间隔最大值的目标解。可以更好地解决小样本问题,具有强大的泛化能力。
2.2 k均值算法
一种常用的聚类算法,可解释性强、收敛速度快。其核心是将数据集划分为多个聚类,并使得数据集中的数据点到其所属聚类质心的距离平方和最小,考虑算法应用的场景不同,此处描述的“距
离”包括却不限于欧氏距离和曼哈顿距离等。
2.3 CNN算法
CNN是典型的深度学习算法,主要是由卷积层、输出层和全连接层组成,卷积层执行卷积操作,而全连接层则执行点乘操作,使用反向传播算法来优化参数。
常见网络:
AlexNet、VGGNet、GoogleNet和 OverFeat
等。
2.4 Q-学习算法
强化学习常用算法。
2.5 AdaBoost算法
将弱分类器提升为高分类精度的强分类器。
AdaBoost 算法对异
常值和噪声数据比较敏感,具有可改善子分类器预测
精度、无需先验知识、理论十分扎实、克服过拟合问题
等优点。
参考文献:
[1]杨晓静,张福东,胡长斌.机器学习综述[J].科技经济市场,2021(10):40-42.
深度学习中,自监督(self-supervised)和无监督(unsupervised)有什么区别? - 知乎 (zhihu.com)















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









