






注意力机制与傅里叶变换的结合在近年来的深度学习和信号处理领域中备受关注,这种结合方式通过提取频域特征和动态关注关键信息,显著提升了模型的性能和效。
我还整理出了相关的论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
标题:
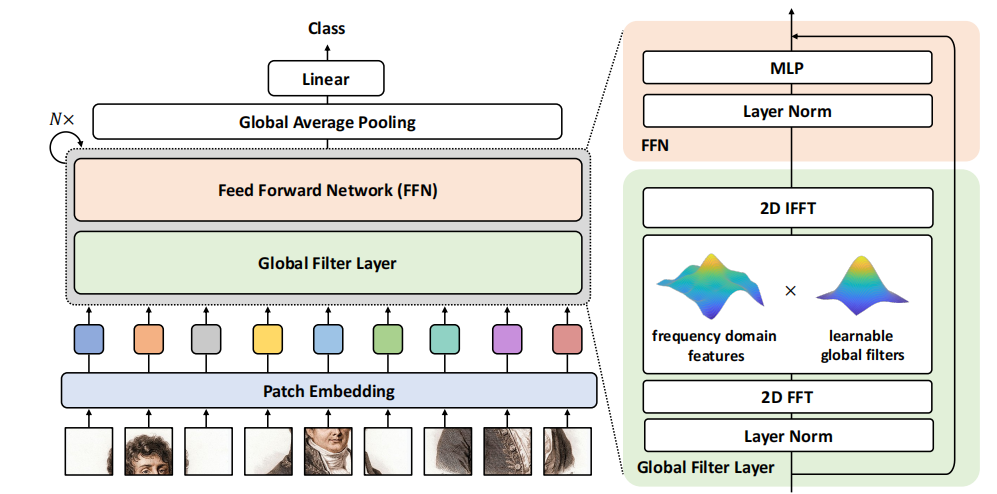
Global Filter Networks for Image Classification
用于图像分类的全局滤波网络
方法:
-
全局滤波层(Global Filter Layer):提出了一种基于频域的全局滤波层,通过二维离散傅里叶变换(2D FFT)、频域特征与可学习全局滤波器的逐元素乘法以及二维逆傅里叶变换(2D IFFT)来实现空间位置之间的长距离依赖关系。
-
架构设计:基于Vision Transformer架构,用全局滤波层替代了自注意力层,同时保留了前馈网络(FFN)作为模型的基本构建块。
创新点:
-
频域交互建模:通过频域中的全局滤波器学习空间位置之间的交互,避免了自注意力和MLP模型中复杂度随图像分辨率二次增长的问题。
-
计算效率提升:全局滤波层的复杂度为O(L log L),相比自注意力(O(L²))和MLP(O(L²))大幅降低,使得模型在高分辨率特征图上的应用更加高效。
-
性能提升:在ImageNet数据集上,GFNet-XS模型在224×224分辨率下达到78.6%的Top-1准确率,比ResMLP-12高出2.0%,GFNet-B达到80.7%,优于DeiT-B(81.8%)等模型。
论文2
标题:
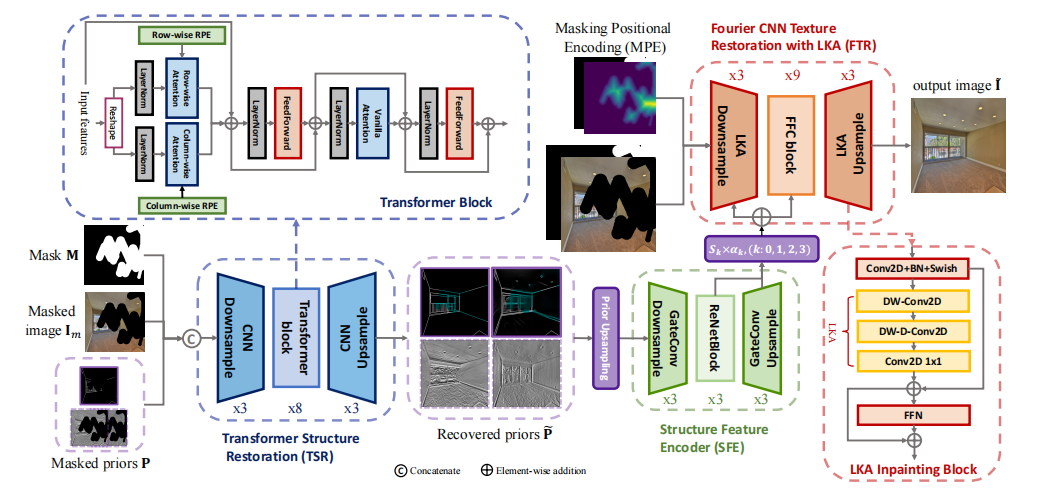
ZITS++: Image Inpainting by Improving the Incremental Transformer on Structural Priors
ZITS++:通过改进基于结构先验的增量式Transformer进行图像修复
方法:
-
Transformer结构恢复模块(TSR):在低分辨率下恢复整体结构先验,包括学习边缘、线段和梯度等结构信息。
-
简单结构上采样模块(SSU):将恢复的结构先验上采样到更高分辨率,以支持高分辨率图像修复。
创新点:
-
结构恢复性能提升:TSR模块能够更准确地恢复结构先验,如边缘和线段,与之前的方法相比,结构恢复的F1分数显著提高,例如在Indoor数据集上,L-Edge的F1分数从28.55提升到52.07。
-
纹理修复性能提升:通过引入大核注意力卷积(LKA)和改进的傅里叶卷积,FTR模块在高分辨率图像修复中表现出更好的性能。例如,在512×512分辨率下,ZITS++的FID从25.64降低到23.24,LPIPS从0.118降低到0.092。
-
高分辨率修复能力:通过E-NMS技术和SSU模块,ZITS++能够将结构先验上采样到任意分辨率,显著提升了高分辨率图像修复的效果。例如,在1024×1024分辨率下,ZITS++的PSNR达到29.03,SSIM达到0.925,FID降低到14.72。
论文3
标题:
WAVTOKENIZER: AN EFFICIENT ACOUSTIC DISCRETE CODEC TOKENIZER FOR AUDIO LANGUAGE MODELING
WAVTOKENIZER:一种高效的音频语言建模的离散声码器标记器
方法:
-
编码器设计:采用全卷积编码器网络,通过多层卷积和LSTM进行序列建模,提取音频特征。
-
单量化器设计:通过扩展量化空间(VQ空间)并结合K-means聚类初始化和随机唤醒策略,将多层量化器压缩为单个量化器。
创新点:
-
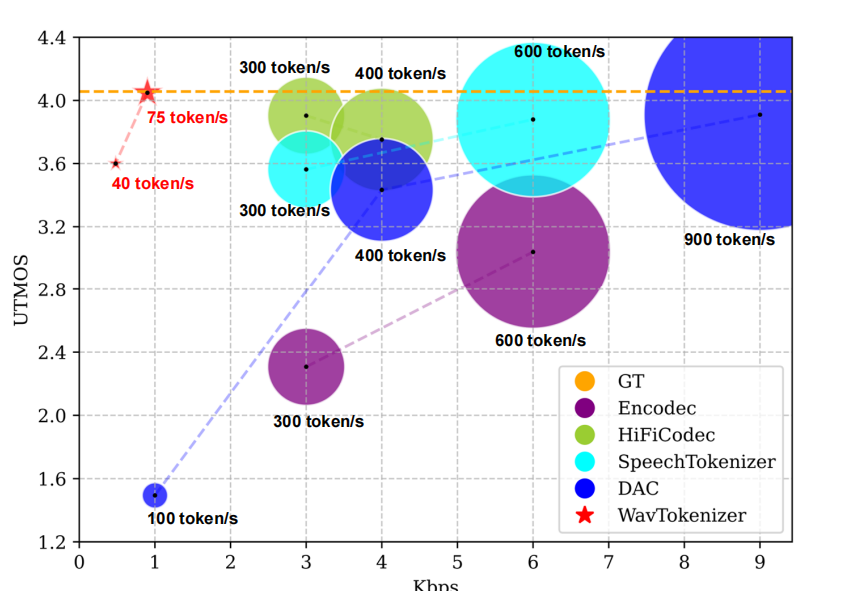
单量化器压缩:通过扩展VQ空间和优化训练策略,将多层量化器压缩为单个量化器,显著降低计算复杂度。例如,WavTokenizer仅用75个token即可重建24kHz音频,而传统方法如DAC需要900个token。
-
语义信息增强:通过注意力机制和扩展上下文窗口,显著提升了模型的语义信息建模能力。在ARCH基准测试中,WavTokenizer在多个数据集上的分类准确率显著高于其他单量化器模型。
-
重建质量提升:引入逆傅里叶变换和多尺度判别器,显著提升了音频重建质量。例如,在UTMOS评分中,WavTokenizer在0.9kbps的比特率下达到4.0486,优于9kbps的DAC模型(3.9097)。
论文4
标题:
NBC2: Multichannel Speech Separation with Revised Narrow-band Conformer
NBC2:基于改进的窄带Conformer的多通道语音分离
方法:
-
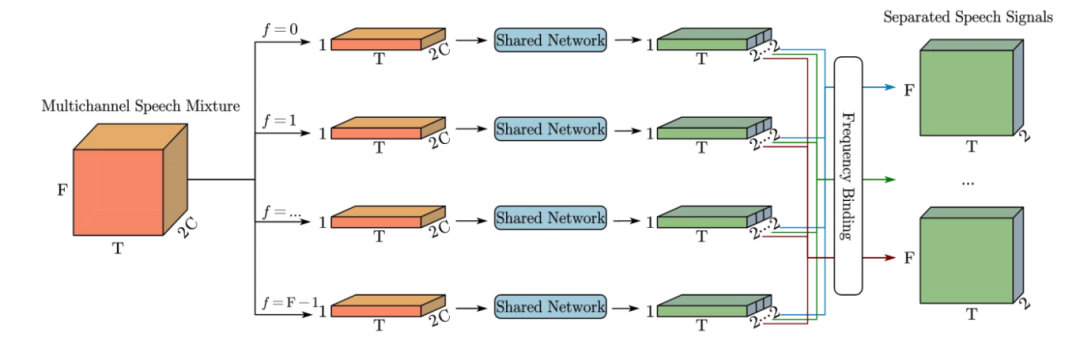
窄带分离框架:在短时傅里叶变换(STFT)域中独立处理每个频率,所有频率共享同一网络,预测多个说话人的STFT系数。
-
自注意力机制:利用自注意力模块对帧级空间向量进行聚类,计算向量相似性并聚合相似向量。
-
卷积前馈网络:通过卷积层进行信号平滑和混响处理。
创新点:
-
窄带分离性能提升:通过改进的Conformer网络,显著提升了窄带语音分离的性能。例如,NBC2-large在16kHz数据上的SDR达到25.2dB,优于其他方法(如Beam-Guided TasNet的19.0dB)。
-
组批归一化(GBN):相比传统的批量归一化(BN)、层归一化(LN)和组归一化(GN),GBN显著提升了分离性能。例如,GBN使SDR提升了超过3dB。
-
频率排列问题解决:通过全带排列不变训练(fPIT),解决了窄带方法中的频率排列问题,提升了多频率分离的性能。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









