






 本文探讨了机器学习如何模仿人类经验学习过程,通过大量样本训练模型,解决如垃圾邮件辨别、图像识别(猫狗区分)、人脸识别和数字识别等任务,强调了机器学习在处理复杂关系和人类难以完成的高难度任务中的重要性。
本文探讨了机器学习如何模仿人类经验学习过程,通过大量样本训练模型,解决如垃圾邮件辨别、图像识别(猫狗区分)、人脸识别和数字识别等任务,强调了机器学习在处理复杂关系和人类难以完成的高难度任务中的重要性。
所谓的机器学习就是让机器去学习, 在这里关键词是学习两个字
在我们传统的学习算法的过程中, 我们真正要做的事情其实是让机器去执行,也就是说设计一个算法, 去让机器具体的完成一个任务,而不是学习一个任务
最早的机器学习应用-垃圾邮件辨别
传统的计算机解决问题思路:
- 编写规则, 定义“垃圾邮件”, 让计算机执行
- 对于很多问题, 规则很难定义
- 规则在不断变化
过程输入样例(邮件)——>编写一个传统算法——>输出结果
依据的规则也在不断变化, 一个典型的例子是图像识别
-
图像识别
- 难题:如何区分图像中的猫和狗
- 传统方法:难以定义图像特征,如何判断是猫还是狗?
- 机器学习方法:帮助机器寻找难以描述的图像关系
![![[Pasted image 20230831194246.png]]](https://img-blog.csdnimg.cn/85434047b2aa4418b8714945d0cc4f4f.png)
大家可以看现在的这两个照片,我们人类可以很清除的区分狗和猫,但如果让大家具体的说,究竟是什么让你认为左侧是狗,右侧是猫,这个问题就很难回答,尤其是对于这两张图,它们俩摆了同样的姿势,都有耳朵,都有眼睛,都有鼻子,都有嘴,都有爪子,都有毛,那么我们到底怎样来定义什么是猫,什么是狗呢?可能有些同学会说右侧的猫,它有猫科动物特有的斑纹,可问题在于,就算你制定出了这个规则,那么我还是能找到很多的猫没有这种斑纹。与此同时,我也能找到一些狗,它拥有这些斑纹,更不用说人类描述的有斑纹的特征
如果用计算机量化描述的话,究竟怎样就叫做有斑纹?其实这个规则是很难编写的,也正因如此,图像识别领域需要大量使用机器学习的方法来解决, 机器学习的方法就是让机器去寻找图片的信息和它对应的是猫还是狗这之间的这个关系,那么这个关系很有可能使用我们人类的语言甚至都描述不出来, 相应的,其实我们很难解释我们最终得到的这个对应关系, 它的意义到底是什么,但是机器学习得到的这种对应关系却能够真实的帮助我们判别出究竟一张图片是猫还是狗。与之相应的一个非常成熟的应用其实就是人脸识别领域。大家都知道,人和人整体的特征其实是完全一致的,都拥有五官、头发、皮肤等等,但与此同时,人跟人之间的样貌相差也是非常大的,我们人类可以非常容易的分辨出这个人是谁,另外一个人是谁。可是如果这件事让计算机去做的话,就会非常非常的困难。不过庆幸的是,现在计算机科学家们已经发现使用机器学习的方法来完成人脸识别这个任务,效果是非常好的。
-
人脸识别
- 挑战:人类轻松识别人脸特征,计算机难以模仿
- 解决方案:机器学习方法显著提升人脸识别效果
![![[Pasted image 20230831194324.png]]](https://img-blog.csdnimg.cn/cbc9bb381e4749958a25987a391f6ba2.png)
![![[Pasted image 20230831194346.png]]](https://img-blog.csdnimg.cn/a4cd1ba5cf4541e982de9eb1d566577b.png)
另外一个更加简单且非常实用的一个任务就是数字识别领域,在这里大家看到的这个图片其实是一个非常著名的数据集,叫做MNIST数据集, 图片是数据集中一部分数据内容。数字识别顾名思义就是给出一个手写数字的图片,去判断这张图片它代表的数字是0123456789其中的哪一个数字, 目前这个任务已经应用了机器学习并得到了非常好的解决,准确率能达到99%以上,这使得我们整个邮政系统的效率得到了极大的提升。
在邮寄的过程中,邮政编码是一个非常重要的特征,可以帮助我们快速的将所有的信件、快递、包裹投送到哪个城市、哪个区域进行分类,这个过程如果使用人工来完成的话, 费时, 费力,而且易出错,效率低。有了数字识别,这个过程完全可以让机器取代。
- 数字识别也展示了机器学习威力
- 数字识别任务:判断手写数字中的数字为多少
- 应用:邮政系统提高邮件处理效率
前面我们举了一些例子,比如垃圾邮件的识别,人脸识别,图像的识别,数字的识别等等,大家可能就会发现这些任务其实人类做起来非常容易,但是计算机却做起来非常困难的任务,这和我们人类发明计算机之初,让计算机执行的那些任务是有本质的区别的。大家可以思考一下我们在传统的经典的算法中,执行的那些任务其实都是让计算机执行容易,让人类执行却很困难的。比如说给100万个数去排序,让人类执行效率会非常非常的低,但是让计算机执行很快就完成了,包括对很大或很多的数据进行简单的运算, 这样的任务其实人类做起来都非常的难,但是机器做起来却非常的容易,可是机器学习将要处理的事情正好相反,这就让机器学习算法的发明者开始去思考——人类到底是怎么进行学习的?
比如说图像识别这个任务,我们从根本不知道什么是猫,什么是狗,到看了一眼照片马上就能分辨出猫和狗,仔细分析一下大家就会知道,其实我们人类的学习过程是一个典型的经验学习的过程。首先我们需要有一定的样本资料,大家可以想象一下,在我们很小的时候,无论是在图书中,还是在电视中,或者是在现实中,爸爸妈妈告诉我们,看, 那有一只猫、看,那是一只狗, 我们不断的接收不同的猫和狗的图片的信息资料,经过我们大脑的学习、归纳、整理和总结,最终形成了属于我们的知识,或者说经验。
![![[Pasted image 20230831194445.png]]](https://img-blog.csdnimg.cn/6978d199ddd347fcb7321eeb34c55f7a.png)
在此基础上,等我们长大后,再遇到类似的对象,比如我们在大街上又看到了一只流浪猫,或者是在电视中看见了一只猫,那么我们能迅速根据我们得到的知识或者经验来做出反应, 在这里,所谓的反应就是判断出了这是一只猫。
其实我们大多数的学习过程都是这样的,我们通过一些样本资料和自己大脑的学习,归纳、整理和总结来获取知识和经验,再碰到类似的任务,就能做出相应的反应。那么事实上机器学习的过程和我们人类学习的过程是极其相似的,对于机器学习和机器学习的算法来说这个过程做的其实就是我们为这个算法送进去的大量的学习的资料,或者说是样本资料
回过头再来看一下什么是机器学习?
![![[Pasted image 20230831194534.png]]](https://img-blog.csdnimg.cn/6f4f73feb95c446aa03b26e77dc28c8e.png)
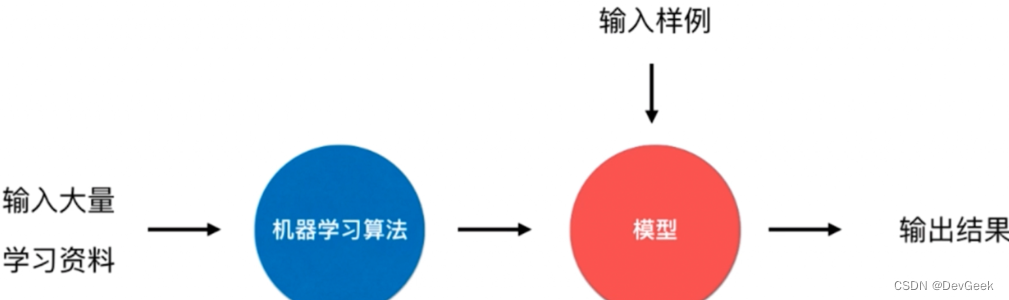
比如说将大量的猫和狗的照片给机器学习的算法,于是这个机器学习的算法将会得到一个可以执行任务的具体的算法, 通常在这个机器学习领域,我们将这种执行任务的具体算法称之为是一个模型, 基于输入的大量样本资料所训练的一个模型。那么当我们有了这个模型之后,我们再来输入新的样例时,比如说再给一个新的照片,拿给这个模型,这个模型就可以判断出来照片中的对象到底是猫是狗。
可能对于大多数人来说,我们只需见过几只猫或者几只狗后,就能非常准确的分辨出猫和狗, 虽然我们不能准确的阐述出区别具体是什么,但是当面对一个新的图像也好,照片也好,或者是一个小动物也好,我们都可以以较高的准确率说出来它到底是猫还是狗,但是对于机器来说却不一样,机器其实是非常笨的,它的优势依然在于运算效率非常的高,所以它可以处理海量的资料,我们可能需要喂给机器几百甚至几千张猫或者狗的照片,机器才有可能面对任意一张的猫或者狗的照片,得到相对比较高的这种输出结果。
- 任务难度与传统算法区别
- 区别:人类容易执行的任务,机器难以完成
- 计算机初期任务:处理人类难以胜任的任务
- 机器学习方法的重要性:处理复杂任务与关系
![![[屏幕截图 2023-08-31 185154.png]]](https://img-blog.csdnimg.cn/a4a4209c2b7144028366ab11f5a44ae9.png)
![![[屏幕截图 2023-08-31 185230.png]]](https://img-blog.csdnimg.cn/5220955a5e6d4793899cabd8bbe981b8.png)
















 6852
6852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











