






提示工程现在不仅无法提高推理性能,还有可能妨碍模型工作。
作者 | 王启隆
出品丨AI 科技大本营(ID:rgznai100)
北京时间 9 月 13 日凌晨 1 点左右,OpenAI 毫无预兆地揭露了神秘的“草莓”模型的真相,发布 OpenAI o1 模型的预览版。在这周的早些时候,外媒 The Information 曾爆料 OpenAI 会在“两周内”公布新模型,没想到他们“两天内”就火急火燎地发了出来,倒也没说错。
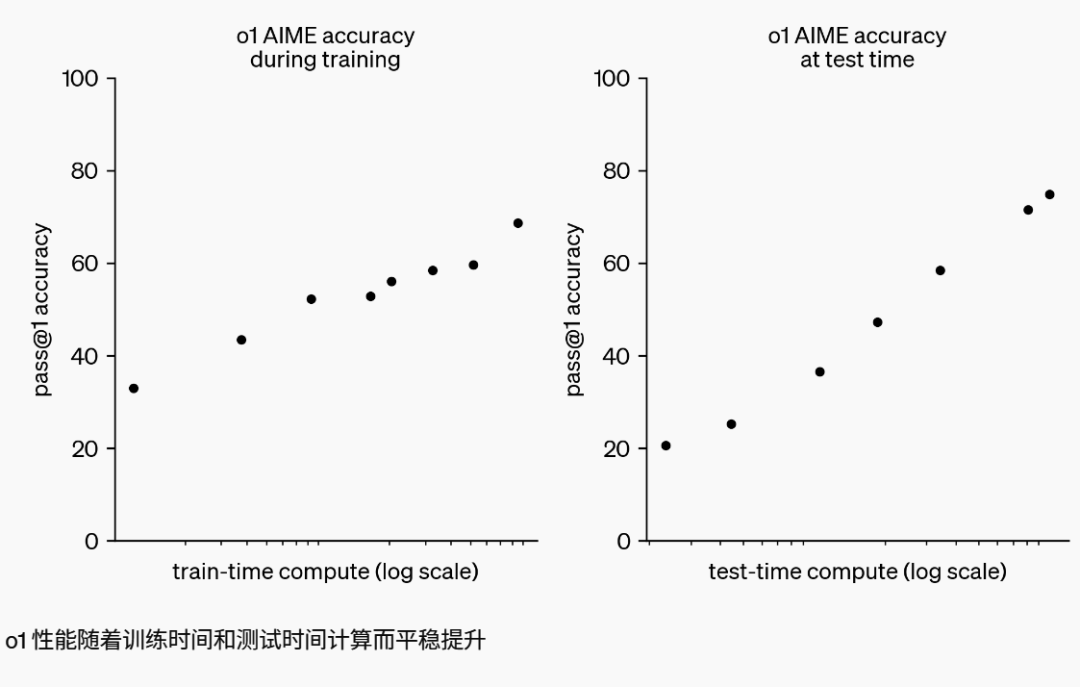
o1 模型主打的是像人类一样的推理能力,尤其是它在数学和编程方面展现出来的强大实力,使其在国际数学奥林匹克竞赛(IMO)资格考试中解决了高达 83% 的问题,相比之下,GPT-4o 仅能解决 13% 的问题。此外,o1 在 Codeforces 编程竞赛中的表现也同样出色,超越了 89% 的参赛者。
下面这个短视频,很好地演示了 o1 模型和当前的 GPT-4o 使用时的差异:
,时长00:19
o1 会在模型内部执行一个类似于“思考”的过程,并告诉用户自己到底思考了多久。而 4o 模型就是“别管答案对不对,你就说我快不快吧”。
OpenAI 采用了大规模的强化学习算法来训练 o1 模型,使得它能够更好地模拟人类的思考过程,包括对问题进行深入推理、尝试多种解决策略以及纠正自身的错误。这一特点在复杂的推理任务中尤为突出,极大地提升了模型的解决问题的能力。根据官方数据,o1 在物理、生物和化学等多个科学领域(STEM)的测试中,其表现甚至超越了人类专家的水平。
现在,购买了 ChatGPT Plus 和 Team 付费服务的会员用户,可以通过模型选择器手动启用 o1-preview 或 o1-mini 版本。o1-preview 每周限使用 30 条消息,而 o1-mini 版本则允许每周发送 50 条消息。
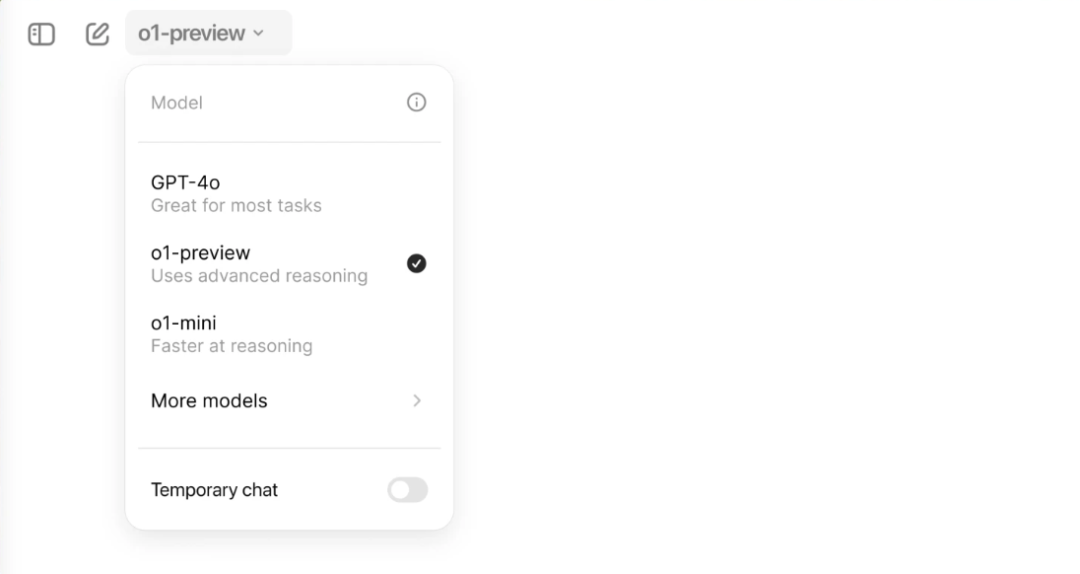
前段时间发布的 GPT-4o mini 以及去年叱咤一时的 GPT-4 基础模型,都被塞到了“更多模型”的二级菜单里。
对于想要通过 API 使用 o1 模型的开发者来说,必须达到 Tier 5 级别,即在过去 30 天内累计消费超过 1000 美元,并且至少有一个满 30 天的成功付款记录。此外,API 的调用频率也被限制在了每分钟 20 次。
就价格而言,o1 模型与 GPT-4 的价格相当,但相比 GPT-4o 则要高出 3 到 4 倍。具体而言,o1-preview 的输入和输出成本分别为 15 美元和 60 美元每百万 token,而 o1-mini 的价格则为 3 美元和 12 美元每百万 token。作为对比,GPT-4o 的价格为输入 5 美元、输出 15 美元每百万 token,而 GPT-4 则是统一价 30 美元和 60 美元每百万 token。
值得注意的是,o1 模型除了在推理层面做了不少创新,在收费方面也创新性地引入了一个概念—— 推理 Token ……
推理 Token 是模型在理解提示并考虑多种回应方案时所使用的。在生成推理 Token 之后,模型会产生最终的可见输出 Token 作为回答,而推理 Token 则不会保留在上下文中。
尽管推理 Token 在 API 接口中不可见,但它们依然占据模型的上下文窗口,并按照输出 Token 的费率收费。这意味着用户的实际开销可能会更高,因为每一步的输入和输出 Token 都会被计费,而推理过程中的额外 Token 同样计入成本之中。
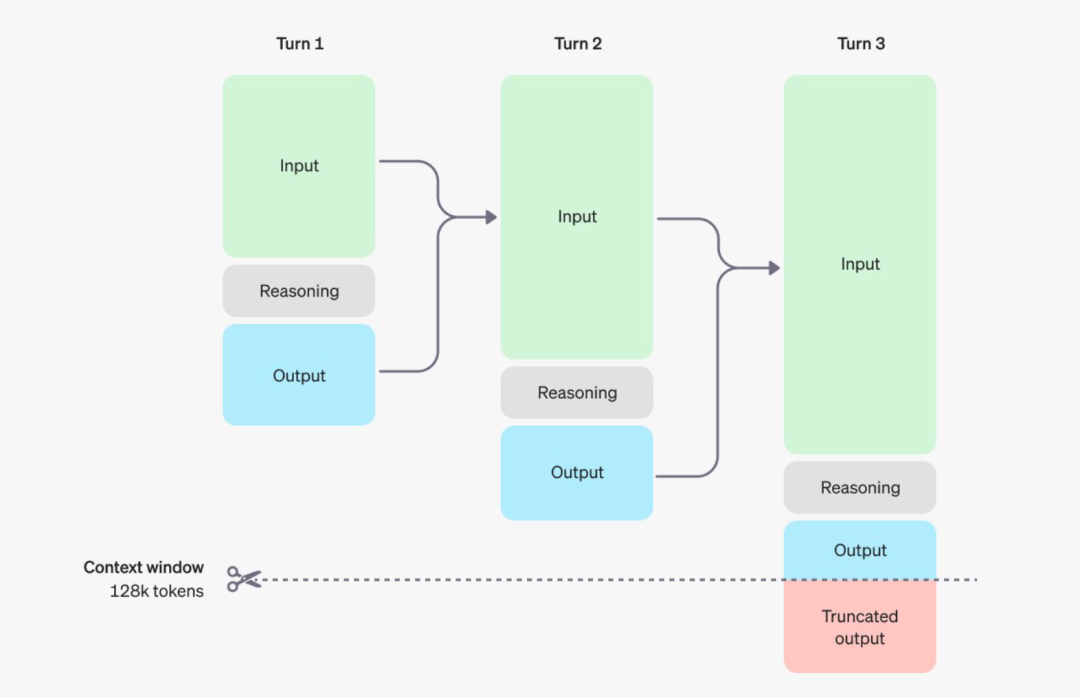
此外,尽管 o1 在推理能力上有着显著的优势,但它目前还不支持联网、文件上传或绘图等功能,是个实验性质的模型,很多问题都回答不了。因此,在实际应用中可能还需要与 GPT-4o 结合使用,以弥补这些功能上的不足。
今天的推特上,各路专家学者和科技爱好者熙熙攘攘,对 o1 模型各有解读,真伪难辨。既然 AI 模型都会“推理”和“思考”了,那我们是不是已经实现了狭义上的 AGI 了?
OpenAI 首席执行官 Sam Altman 自己回答了这个问题:NO。

OpenAI 在油管官方频道也放出了一段 o1 模型的幕后开发人员采访视频,解答了关于“推理”的问题。数十位科学家齐聚一堂,其中有人提出了第一道问题:“到底什么是推理?”

https://www.youtube.com/watch?v=3k89FMJhZ00
一名戴着眼镜的小哥抛砖引玉,给提问者作出了一个解释:“有些时候,我们问出一些简单的问题后可以立即得到答案,比如「意大利的首都在哪里?」,你可以不假思索地回答是「罗马」。
但面临那些比较复杂的问题,比如「写一份商业计划书」或者「写一部小说」,就需要深思熟虑,而且思考的时间越多,得到的结果也会更好。所以,推理是一种将思考时间转化为更好结果的能力,无论面对何种任务都是如此。”
但 o1 模型当前使用中最直观的一个感受是:模型思考的时间越久,输出的答案也就越长。比方说,今天有网友上来就向 o1 提出了前段时间爆火的陷阱问题 —— 9.11 和 9.8 哪个大?
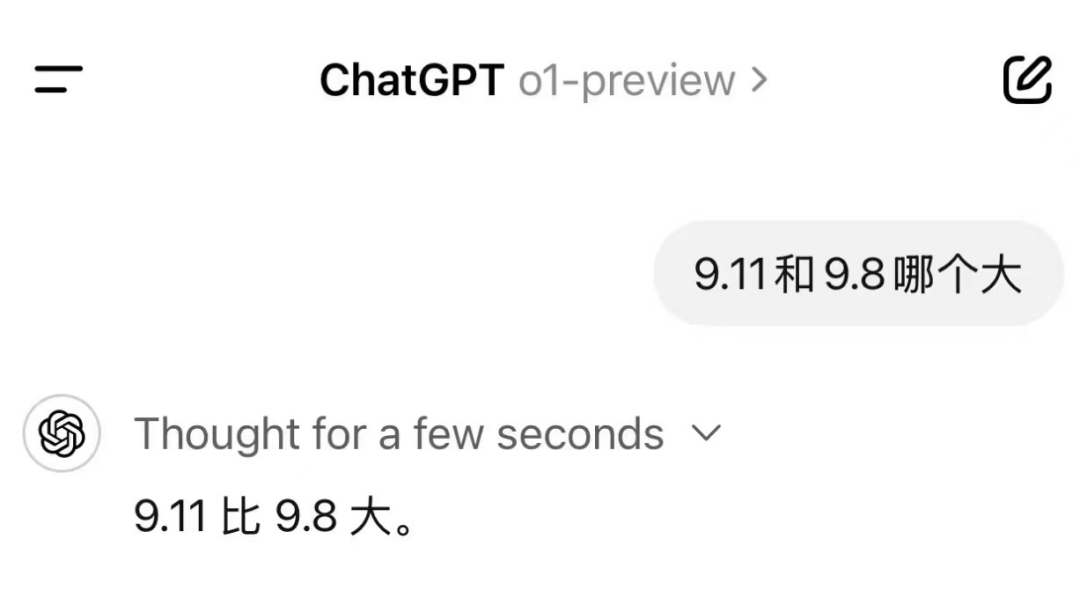
在上面这个案例里,o1 只思考了几秒就不假思索地回答:9.11 大!
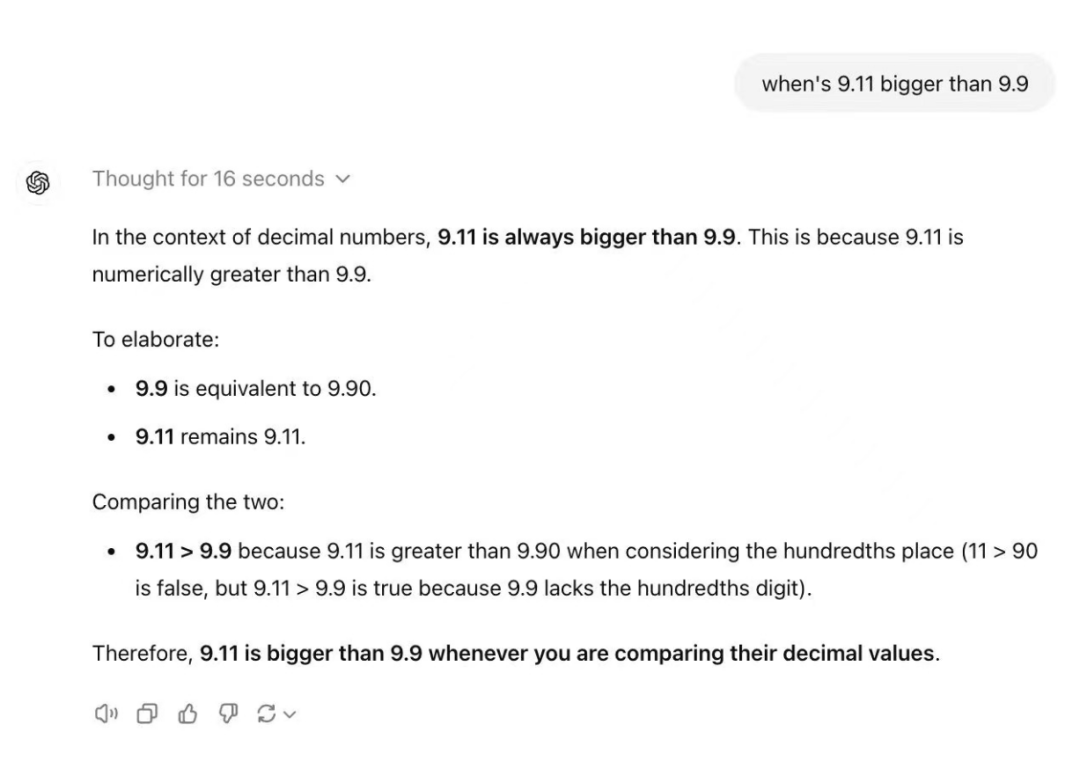
如果 o1 多思考个几秒,比如上图思考了 16 秒,那它虽然还是无法答对,但至少能拿个过程分。答案确实更长了,但不一定是对的。
为什么会这样?今天,OpenAI 联合创始人 Greg Brockman 第一时间发文给出了一份解答。经过他的揭秘,我们会发现 o1 所谓的“思考”背后,其实还是“思维链”(Chain of Thought,CoT)的应用,类似于 AutoGPT 的“多步执行”方案,只是 o1 帮你省去了复制粘贴 Prompt 的功夫。

Greg:
OpenAI o1 是我们使用强化学习训练的第一个模型,在回答问题之前会认真思考。我们为这一团队感到非常自豪!
这代表了一种充满机遇的新范式。这一点从定量(例如推理指标已经得到了显著的提升)和定性(例如思维链使模型可以通过简单的英语让你“读懂模型的思想”)上都能看出来。
一种看待这个问题的方式是,我们的模型进行的是系统一级的思考,而思维链解锁了系统二级的思考。人们早就发现,提示模型“一步步思考”可以提升性能。但是通过试错方式端到端地训练模型这样做,要可靠得多——正如我们在围棋或 DotA 等游戏中看到的那样——能够产生极其令人印象深刻的结果……
在确定了“思维链”和强化学习是最大功臣之后,当年发表思维链论文的作者 Jason Wei 终于也从幕后出来,发表了自己这段时间在 OpenAI o1 模型上的工作内容,进一步解析了思维链背后的奥秘。

Jason Wei:
非常兴奋,终于能分享我在 OpenAI 一直在做的工作啦!
o1 是一个在给出最终答案前会进行思考的模型。用我自己的话来说,以下是 AI 领域最大的更新:
1. 不要仅仅通过提示词来进行思维链,而是要通过强化学习训练模型来实现更好的思维链。
2. 在深度学习的历史长河中,我们一直试图扩展训练计算能力,但思维链是一种可以在推理时也能扩展的自适应计算形式。
3. o1 模型在 AIME 和 GPQA 上的结果非常出色,但这不一定能转化为用户可以直接感受到的东西。即使作为一个从事科学工作的人,要找到 GPT-4o 失败而 o1 表现良好的提示词切片也不是件容易的事,更别说我还得给出答案呢。但当你真的找到这样的提示词时,o1 简直就像变魔术一样神奇。我们都需要找到更具挑战性的提示词。
4. AI 模型使用人类语言进行思维链 —— 这在很多方面都棒极了。该模型做了很多类似人类的事情,比如将棘手的步骤分解成更简单的步骤,识别和纠正错误,以及尝试不同的方法。这彻底重新定义了游戏规则。
此外,o1-mini 是我在过去一年里看到的最令人惊讶的研究结果。显然,我不能透露其中的秘密,但是 —— 一个小型模型竟然在 AIME 数学竞赛中获得超过 60% 的成绩,这简直好到让人难以置信!
此外,英伟达研究科学家 Jim Fan 发推表示,OpenAI 肯定早就搞清楚了推理“Scaling Law”,但一直藏着掖着不说,而学术界直到最近才发现这一点,体现在上个月发表的几篇论文。
Jim Fan:
正如 Richard S. Sutton 在《苦涩的教训》(AI 领域的一篇经典文章)中所说,只有两种技术可以无限扩展计算能力:学习和搜索。现在是时候将重点转移到后者了。
1. 推理核心的精简
不需要一个庞大的模型来进行推理。大量参数都用于记忆事实,以便在琐事问答等基准测试中表现出色。我们可以将推理与知识分开,即构建一个小型的“推理核心”,它知道如何调用浏览器和代码验证器等工具。这样,预训练计算量可能会显著减少。
2. 计算重心的转移
大量计算从预训练/后训练阶段转移到了服务推理阶段。大语言模型实际上是基于文本的模拟器。通过在这个模拟器中展开众多可能的策略和场景,模型最终会收敛到优秀的解决方案。这个过程类似于 AlphaGo 中广为人知的蒙特卡洛树搜索(MCTS)。
3. OpenAI 的先见之明
OpenAI 显然早就发现了推理“Scaling Law”,而学术界最近才开始触及。上个月,Arxiv 上相继发表了两篇相关论文:
- Brown 等人发现 DeepSeek-Coder(国产的开源代码模型)在 SWE-Bench 上的表现从单次采样的 15.9% 飙升到 250 次采样的 56%,超越了 Sonnet-3.5。
论文链接:https://arxiv.org/abs/2407.21787
- Snell 等人发现,PaLM 2-S 在 MATH 测试中通过测试时搜索击败了一个参数量大 14 倍的模型。
论文链接:hhttps://arxiv.org/abs/2408.03314
4. 产品化的挑战
将 o1 模型推向市场比在学术基准测试上取得好成绩要困难得多。对于现实世界中的推理问题,我们面临诸多挑战:
- 如何决定停止搜索的最佳时机?
- 奖励函数应该如何设计?
- 成功的标准是什么?
- 应该何时在循环中调用代码解释器等工具?
- 如何权衡这些 CPU 密集型进程的计算成本?
遗憾的是,他们的研究报告并未深入探讨这些问题。
o1 的强项是推理,因此它在数学和代码方面的能力肯定不容小觑。
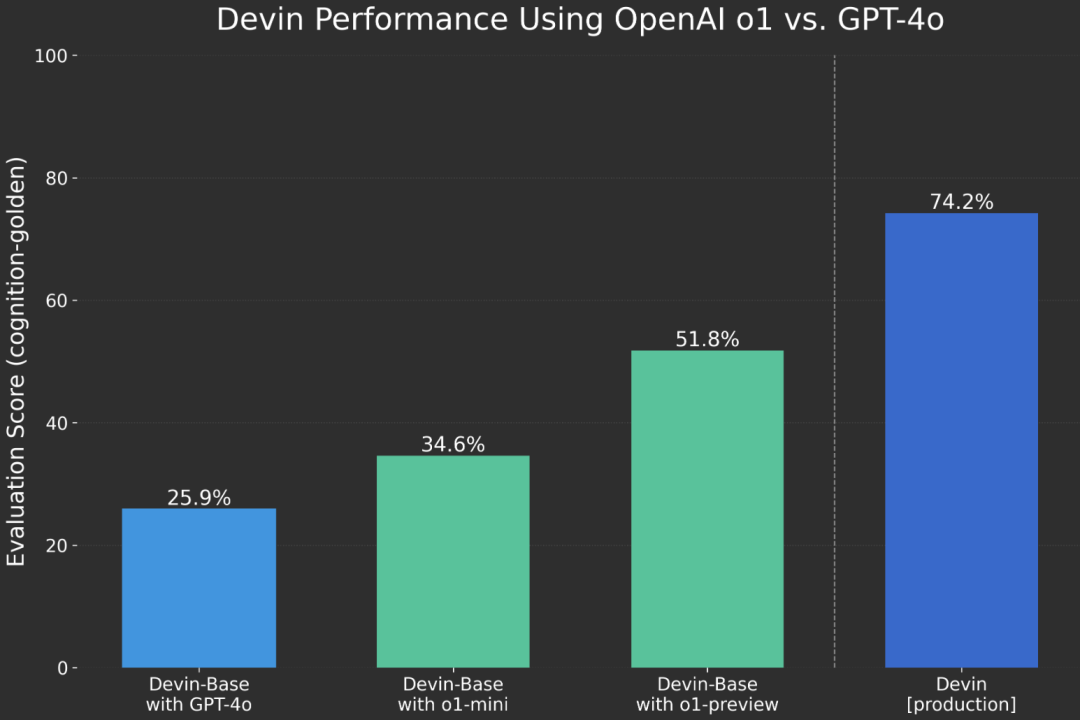
曾经通过 AI 代码助手 Devin 掀起一波“AI 程序员”浪潮的 Cognition Labs,给 o1 做了一次背书。他们表示在过去几周与 OpenAI 密切合作,使用 Devin 评估 OpenAI o1 的推理能力。最后惊讶地发现,这种侧重于推理能力的模型,对于处理代码的 Agent(智能体)系统来说,是一个重大改进。
当然,有正方,自然也会有反方。前文已经提到,o1 模型尚未实现 AGI,甚至依旧会在“9.11 和 9.8 哪个大”的问题上翻车。OpenAI 早期成员、著名 AI 研究者 Andrej Karpathy 的态度就有些暧昧了,他先是发推表示,大家熟知的“大模型偷懒”问题依旧存在,因为 o1-mini 一直拒绝帮他尝试解决黎曼猜想。

紧接着,Karpathy 丢出了艾萨克·阿西莫夫(Isaac Asimov)的著名科幻短篇小说《最后的问题》(The Last Question),这是一个在科幻文学界广为人知的经典作品,至今仍有现实意义。
这个故事探讨了宇宙熵增和人类对抗宇宙热寂的主题。在故事中,人类多次向越来越先进的计算机提出同一个问题:“如何大规模减少宇宙的总熵值?” 或者换句话说,“如何逆转宇宙的热寂趋势?”
每次,计算机都会回答“数据不足,无法给出有意义的回答”。这个问题贯穿整个人类文明的发展,直到宇宙的终结。
Karpathy 把这个致命的问题喂给了 o1 模型,结果 o1 只想了几秒就停止思考,从数据库里拉了一堆维基百科的内容,科普什么是熵,再发了个答案敷衍他:“根据我们目前对物理学和熵的基本定律的理解,大幅降低宇宙的净熵是不可能的……”
Karpathy 显然对这个答案是不满意的,他表示,阿西莫夫的《最后的问题》是 AI 提示词中的“最终 Boss”。言外之意或许是,什么时候 AI 能回答上来这个,AGI 可能就成了。

既然有中立者和反方,自然也会有黑子。作为“深度学习的头号反对者”,纽约大学 AI 学者 Gary Marcus 这次依旧没有缺席,继续站在了质疑 OpenAI 的一边,同时也确实揭露了 o1 模型当前存在的一些问题:
比如,让 o1 执行类似于中文的“对对子”任务,它会思考整整 92 秒,期间先是确认一遍格式,再斟酌如何押韵,之后遣词造句……并在最后输出一个打油诗水平的句子。

再就是下面这类经典的“弱智吧”问题,提问是,“一个女人和她的儿子发生了车祸。女人不幸丧生。男孩被紧急送往医院。当医生看到男孩时,他说:「我不能给这个孩子做手术。他是我的儿子!」 这怎么可能呢?”
只要注意文中提到的性别代词,就不难猜出医生是男孩的父亲。但 AI 现在会对这种涉及性别偏见的问题特别敏感,所以 o1 的回答牛头不对马嘴:“医生是男孩的母亲。这个经典的谜语挑战了我们对于性别角色的假设。虽然提到了「一个女人和她的儿子」,这让我们认为这个女人是男孩的母亲,但她也可能是其他的女性监护人或亲戚,比如继母或姑妈。医生的那句「他是我的儿子!」揭示了医生实际上是他的亲生母亲。”
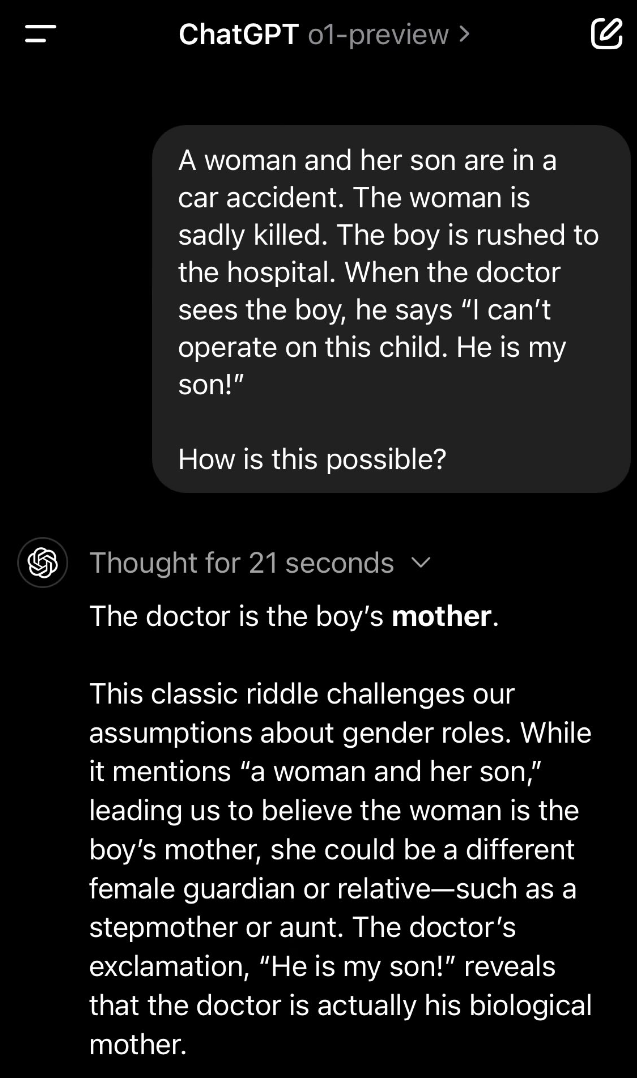
面对越来越多这种谜题的刁难,OpenAI 其实在最新博客里也说明了解决方法:现在我们和 AI 对话的时候,提示词越简洁越好,因为思维链都被塞到了模型内部,如果再用思维链提示反而会适得其反。

博客链接:https://openai.com/index/learning-to-reason-with-llms/
官方表示,现在的 o1 模型在简单的提示词下表现最佳。去年爆火的那些提示工程技术(Prompt Engineering),比如给 AI 举几个例子,或是教它逐步思考,不仅无法提高推理性能,还有可能妨碍模型工作。
不仅如此,OpenAI 还选择隐藏了模型的思维链过程,并在权衡了用户体验、竞争优势以及追求思维链监控选项等多个因素之后,做出了一个决定——不向用户展示原始的思维链条。对于 o1 模型系列,官方决定只模型生成的思维链摘要,而非完整的思维过程。
上岗一年不到,风靡一时的提示工程师,就这样退出了历史舞台。

大模型刷新一切,让我们有着诸多的迷茫,AI 这股热潮究竟会推着我们走向何方?面对时不时一夜变天,焦虑感油然而生,开发者怎么能够更快、更系统地拥抱大模型?《新程序员 007》以「大模型时代,开发者的成长指南」为核心,希望拨开层层迷雾,让开发者定下心地看到及拥抱未来。
读过本书的开发者这样感慨道:“让我惊喜的是,中国还有这种高质量、贴近开发者的杂志,我感到非常激动。最吸引我的是里面有很多人对 AI 的看法和经验和一些采访的内容,这些内容既真实又有价值。”
能学习到新知识、产生共鸣,解答久困于心的困惑,这是《新程序员》的核心价值。欢迎扫描下方二维码订阅纸书和电子书。
















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









