代价敏感错误率与代价曲线
https://www.bilibili.com/video/BV17J411C7zZ?p=21 视频
import torch
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
output_score = list(range(12)) ## 定义一个列表里面的数字是0-11
print(output_score)
y = [0,0,0,0,1,0,1,1,0,1,1,1] ## 其中0表示的是5,1表示的不是5,这里是来对应的标签信息的
print(len(y))
print(y)
# 设定p,集合中正例比列,这里范围是0-100,所以还要除以100
p = list(range(0,101,10)) ## 数字是从0开始,然后所对应步长是10,所以是对应的10个数
p = [i/100 for i in p] ## 然后这里是转换为0-1之间所对应的数的。
print(p)
# 设定代价
c01 = 3
c02 = 2
#设置判断阈值
theta = 6.5
# 定义函数输出判断
# 我们是来判断是5还是不是5,我们是把打分输入后,和对应界限值theta
def calculate_output_result(output_score,theta):
output_result = []
for i in range(len(output_score)): ## 侧量输出分数所对应的长度的为0 -11
if output_score[i] < theta: ## 如果小于6.5 则就是0
output_result.append(0)
else:
output_result.append(1) ## 如果是大于6.5则就是1
return output_result
output_result = calculate_output_result(output_score,theta) ## 然后是我们调用这个函数来进行测试
print(output_result)
# 要来统计正例和反例的个数 也就是说其中m+有多少个m-有多少个
import pandas as pd
def calculate_m_positive_negative(y):
result = pd.value_counts(y)
m_positive = result[1] ## 其中结果是等于1的值是对应的正比例
m_nagative = result[0] ## 其中对应的0是对应的负的比列的过程
return m_nagative,m_positive
m_positive,m_negative = calculate_m_positive_negative(y)
print(m_positive,m_negative)
# 计算混淆矩阵圈1,圈2,圈3,圈4
def calculate_confusion(y,output_result):
con1 = 0 ## 这里是开始来对混淆矩阵进行初始化的过程的。
con2 = 0
con3 = 0
con4 = 0
for i in range(len(y)):
if y [i] == 1:
if y[i] == output_result[i]:
con1 += 1 ## 其中本来是正例,预测也为正例时所对应的情况的
else:
con2 += 1 ###本来是为正例,但是预测为反例时所对应的情况的
else:
if y[i] == output_result[i]:
con4 += 1 ## 本来是为反列预测也是为反例所对应的情况
else:
con3 += 1 ## 本来为反列,但是预测为正列所对应的情况
return con1,con2,con3,con4
con1,con2,con3,con4 = calculate_confusion(y,output_result)
print(con1,con2,con3,con4)

# 求几个数所对应的比列,保留四位小数
def calculate_FNR_FPR(con1,con2,con3,con4):
FNR = round(con2/(con1+con2),4) ## FNR:表示正例中有多少被预测错了,变成了负例
FPR = round(con3/(con3+con4),4) ## FPR:表示负列中有多少被预测错了,变成了正例
return FNR,FPR
FNR,FPR = calculate_FNR_FPR(con1,con2,con3,con4)
print(FNR,FPR)
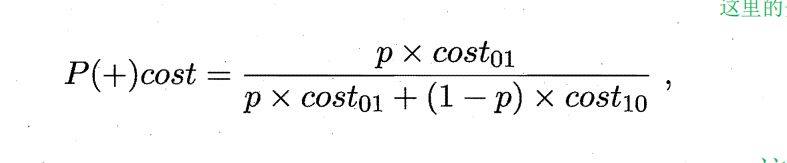
# 正概率代价
def calculate_Pcost(p,c01,c02):
Pcosts = []
for i in range(len(p)): ## 其中我们p是对应的10个不同的值,也就是对应的正样本和负样本所对应的概率的不同,其中每个都会是对应一个层本函数
Pcost = round((p[i]*c01)/(p[i]*c01+(1-p[i])*c02),4) ## (p[i]*c01+(1-p[i])*c02)这里是来对应的归一化的过程的
Pcosts.append(Pcost)
return Pcosts
Pcosts = calculate_Pcost(p,c01,c02)
print(Pcosts)
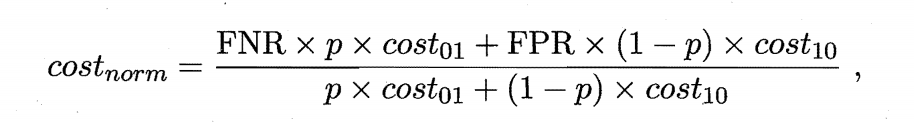
# 归一化总概率 其中p是对应的不同的正负样本所对应的概率的。
def calculate_cost_norm(p,c01,c02,FNR,FPR):
costs_norm = []
for i in range(len(p)):
cost_norm = round((FNR*(p[i]*c01)+FPR*(1-p[i])*c02)/(p[i]*c01+(1-p[i])*c02),4)
costs_norm.append(cost_norm)
return costs_norm
costs_norm = calculate_cost_norm(p,c01,c02,FNR,FPR)
print(costs_norm) ## 是在p不断的变化的时候每一个p所对应的总的归一化的所对应的概率的。
## 我们来画出图像
import matplotlib.pyplot as plt
def plot_lines(X,Y,color): ## 首先是来定义的函数的,然后再来进行相应的调用的过程的。
plt.plot(X,Y,color)
return
plot_lines(Pcosts,costs_norm,'r')
plot_lines(p,costs_norm,"b:")
plt.show()
## 这里前面的是对应的一个theta所对应的情况的
## 后面我们是对应的多个theta所对应的情况的
# 生成多个theta
thetas = list(range(12))
thetas = [i+0.5 for i in thetas] ## 这里的thetas值是从0.5开始的
print(thetas) ## 这里是来的到多个theta的是,也就是是所对应的权限的值的过程的。
#定义计算每个theta对应的点的函数,并且存放在列表中
# output_score是输出相应的分数的值,
# y是对应的真是的标签
# calculate_Pcost 正概率所对应的代价
# calculate_cost_norm:归一化总的概率
def calculate_Pcost_cost_norm(thetas,output_socre,y,calculate_Pcost,calculate_cost_norm):
Pcosts_n = []
costs_norm_n = []
theta_FPR_FNR = []
for i in range(len(thetas)):
theta = thetas[i] ## 这里是来得到每个theta所对应的值
# 计算输出结果,通过theta来对应的边界,这样就是能够通过相应输入分来标签进行预测
output_result = calculate_output_result(output_score,theta)
# print(output_result) ## 这个预测值是不止一个值的
# 统计正反例个数 通过样本的标签来统计正例和反列所对应的个数的。
m_positive,m_negative = calculate_m_positive_negative(y)
# 计算混淆矩阵
con1,con2,con3,con4 = calculate_confusion(y,output_result)
# print(con1,con2,con3,con4)
# 求FNR,FPR,其中FNR有多少正样本被预测错了,变成了反例,FPR是表示负例样本中有多少被预测错了,变成了正例
FNR,FPR = calculate_FNR_FPR(con1,con2,con3,con4)
theta_FPR_FNR[theta]:[FNR,FPR] ## 通过列表的形式把这这些给存储起来,其中每一个theta都是对应一对[FNR,FRP]所
## 对应的值过程的。
#正概率代价 # 这里是来对应的不同的概率的过程
Pcosts = calculate_Pcost(p,c01,c02)
Pcosts_n.append(Pcosts)
# 归一化总概率 # 这里也是对应的不同的概率的过程的。
costs_norm = calculate_cost_norm(p,c01,c02,FNR,FPR)
costs_norm_n.append(costs_norm)
return Pcosts_n,costs_norm_n,theta_FPR_FNR ## 其中是每一个theta都是对应一条线,(FNR,FPR)就是对应一条线,
## 然后又是对应的不同的概率的,
# 调用这个函数来进行计算
Pcosts_n,costs_norm_n,theta_FPR_FNR = calculate_Pcost_cost_norm(thetas,output_score,y,calculate_Pcost,calculate_cost_norm)
## 这里是来画出线段的过程的。
for i in range(len(Pcosts_n)): ## 这里总共是可以得到12条线段的。
plot_lines(Pcosts_n[i],costs_norm_n[i],'r')
plt.show()























 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









