





mapr 如何与ad认证
PredictionIO是一种开源机器学习服务器,是Apache系列的最新成员。 PredictionIO允许您:
- 使用可自定义的模板在生产中快速构建和部署引擎作为Web服务
- 部署为Web服务后实时响应动态查询
- 系统地评估和调整多种发动机变体
- 批量或实时统一来自多个平台的数据,以进行全面的预测分析
- 通过系统的流程和预先建立的评估措施来加速机器学习建模
- 支持机器学习和数据处理库,例如Spark MLlib和OpenNLP
- 实施您自己的机器学习模型并将其无缝整合到您的引擎中
- 简化数据基础架构管理
PredictionIO与HBase捆绑在一起,并用作事件数据存储来管理机器学习模型的数据基础结构。 在此集成任务中,我们将在MapR融合数据平台内使用MapR-DB替换HBase。 MapR-DB直接在MapR文件系统中实现。 由此产生的优点是,在对数据执行操作时,MapR-DB没有中间层。 MapR-DB在MapR-FS进程中运行,并直接读取/写入磁盘。 HBase主要在HDFS上运行,它需要通过JVM和HDFS进行通信,并且还与Linux文件系统进行通信以执行读/写操作。 在MapR文档中可以找到更多优点。
要在MapR-DB中使用,需要在PredictionIO中修改几行代码。 我创建了一个与MapR 5.1和Spark 1.6.1兼容的分支版本。 Github链接在这里 。
制备
前提条件是您正在运行MapR 5.1集群,其中已安装Spark 1.6.1和ElasticSearch服务器。 我们将MapR-DB(1.1.1)用于事件数据存储,将ElasticSearch用于元数据存储,将MapR-FS用于模型数据存储。 在MapR-DB中,没有HBase命名空间概念,因此表层次结构基于MapR文件系统的层次结构。 但是MapR支持HBase的名称空间映射(详细链接在此处 )。 请注意,从MapR 5.1开始,core-site.xml位于“ /opt/mapr/hadoop/hadoop-2.7.0/etc/hadoop/”,您应该修改core-site.xml并添加如下配置。 另外,请在您选择的路径上创建专用的MapR卷。
<property>
<name>hbase.table.namespace.mappings</name>
<value>*:/hbase_tables</value>
</property>然后我们下载并编译PredictionIO:
git clone https://github.com/mengdong/mapr-predictionio.git
cd mapr-predictionio
git checkout mapr
./make-distribution.sh编译后,应该创建了一个文件“ PredictionIO-0.10.0-SNAPSHOT.tar.gz”。 将其复制到临时路径并将其解压缩,然后将jar文件“ pio-assembly-0.10.0-SNAPSHOT.jar”复制回“ mapr-predictionio”文件夹下的“ lib”目录。
由于我们要使用MapR 5.1,因此我们要确保包含正确的类路径。 我在回购中编辑了“ bin / pio-class”以包含必要的更改,但是您的环境可能会有所不同,因此请进行相应的编辑。 还需要创建“ conf / pio-env.sh”。 我有一个模板供参考:
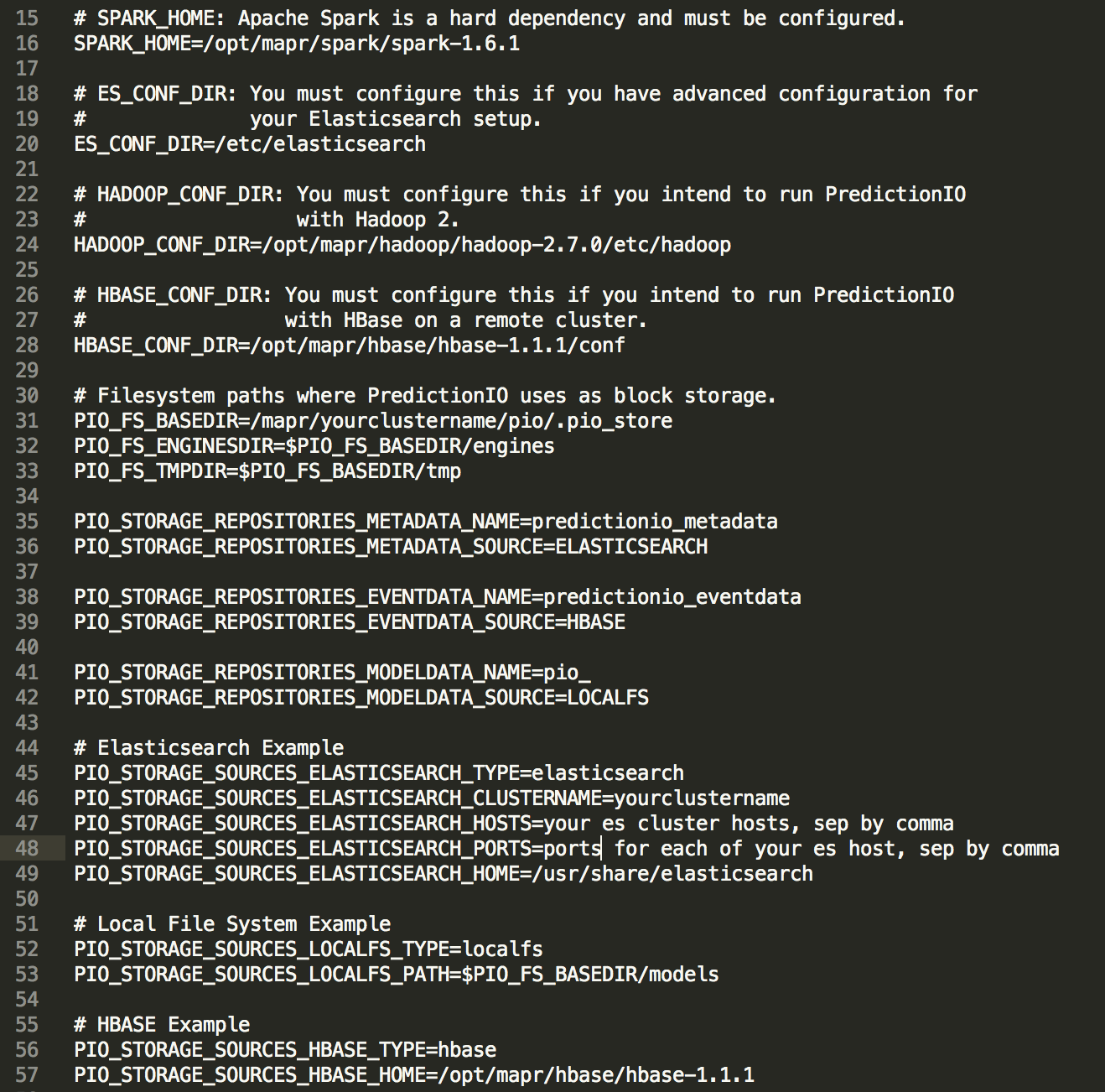
至此,准备工作基本完成。 我们应该将PredictionIO的“ bin”文件夹添加到路径中。 只需运行“ pio status”,即可查看设置是否成功。 如果一切顺利,则应观察以下日志:
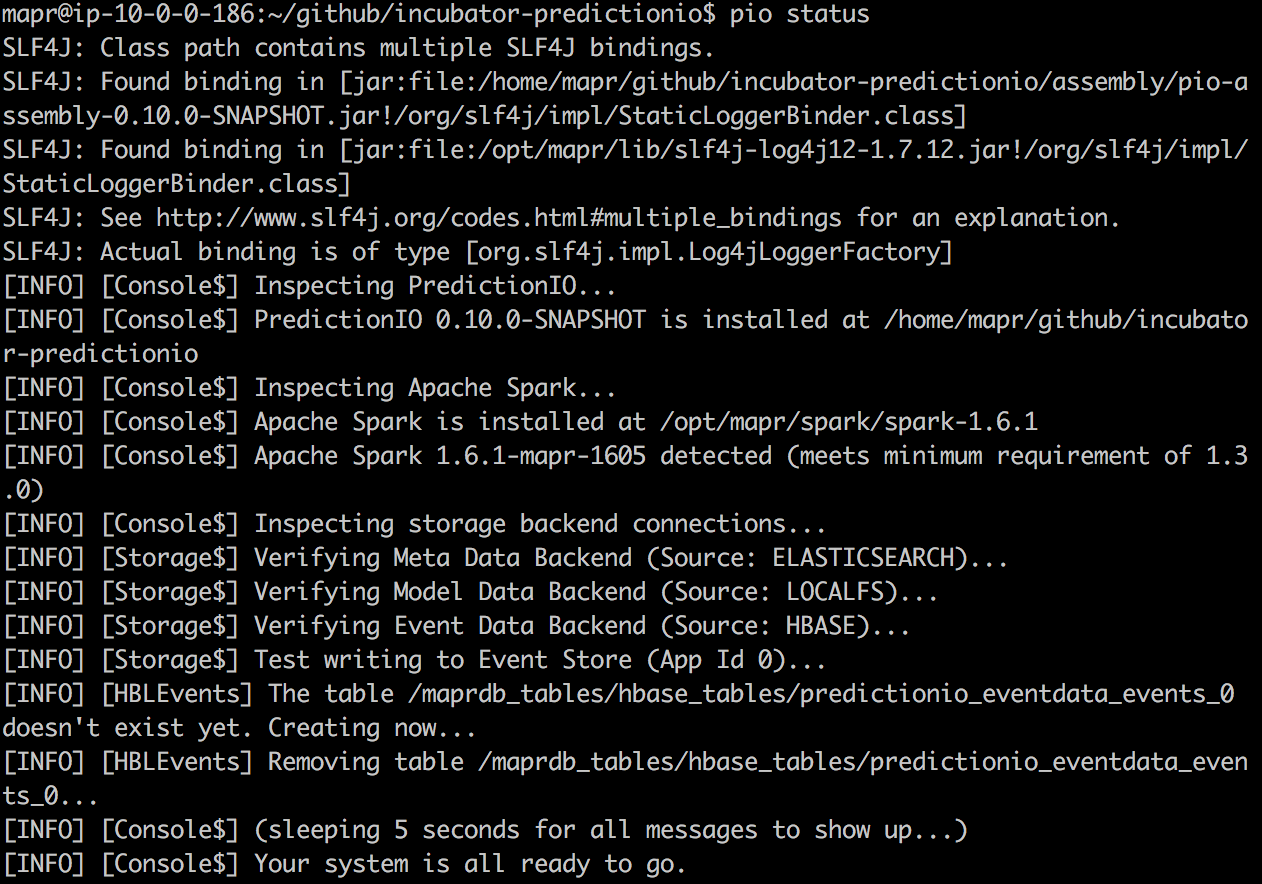
这意味着可以运行“ bin / pio-start-all”来启动PredictionIO控制台。 如果成功运行,则可以只运行“ jps”,并且应该观察到“控制台” jvm。
部署机器学习
PredictionIO的一项出色功能是易于开发/培训/部署机器学习应用程序以及执行模型更新和模型管理。 有许多模板可供演示; 例如: http : //predictionio.incubator.apache.org/demo/textclassification/ 。
但是,由于最近迁移到Apache家族,这些链接已断开。 我创建了一个分叉的仓库,以使几个模板正常工作。 一个https://github.com/mengdong/template-scala-parallel-classification用于http://predictionio.incubator.apache.org/demo/textclassification/ ,这是一种经过逻辑回归的训练,可以对垃圾邮件进行二进制分类。
另一个https://github.com/mengdong/template-scala-parallel-similarproduct用于http://predictionio.incubator.apache.org/templates/similarproduct/quickstart/ ,它是针对用户和物品的推荐引擎。 您可以克隆我的分叉存储库,而不使用“ pio template get”,也可以将“ src”文件夹和“ build.sbt”复制到“ pio template get”位置。 如果进行复制,请修改Scala代码中的软件包名称,以使其与模板获取期间的输入相匹配。
其他所有内容都可以在ForecastIO教程中使用。 我相信这些链接也会很快修复。 只需按照教程将引擎注册到PredictionIO应用程序即可。 然后训练机器学习模型,并进一步部署该模型并通过REST服务或SDK(当前支持python / java / php / ruby)使用它。 您还可以使用Spark和PredictionIO来开发自己的模型,以使用MapR-DB作为后端。 ![]()
mapr 如何与ad认证















 3450
3450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









