








Markdown *.MD 文件 技术文档 在SDL Trados Studio中翻译
Markdown 是一种最新主流的技术文档写作格式,广泛用于API编写,在技术领域十分流行,本篇文档也是在CSDN的Markdown编辑器中撰写的。
SDL Trados 2019 SR2中新添加了Markdown解析器,对外宣布正式支持Markdown文件格式。
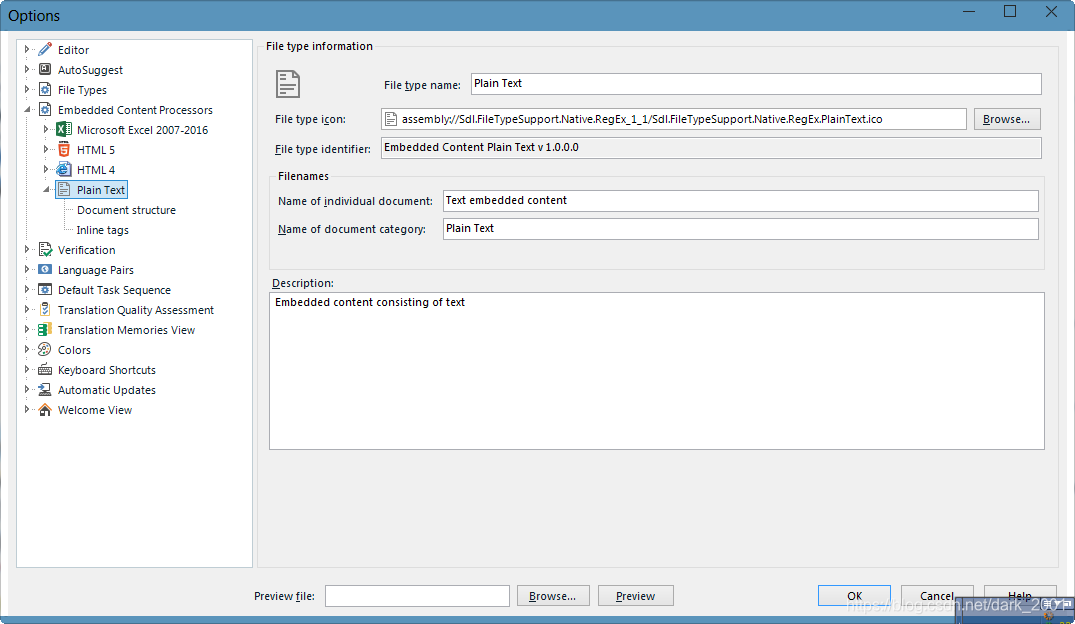
来看一下这个解析器,打开SDL Trados Studio>File>Option>File Types从树中打开markdown解析器
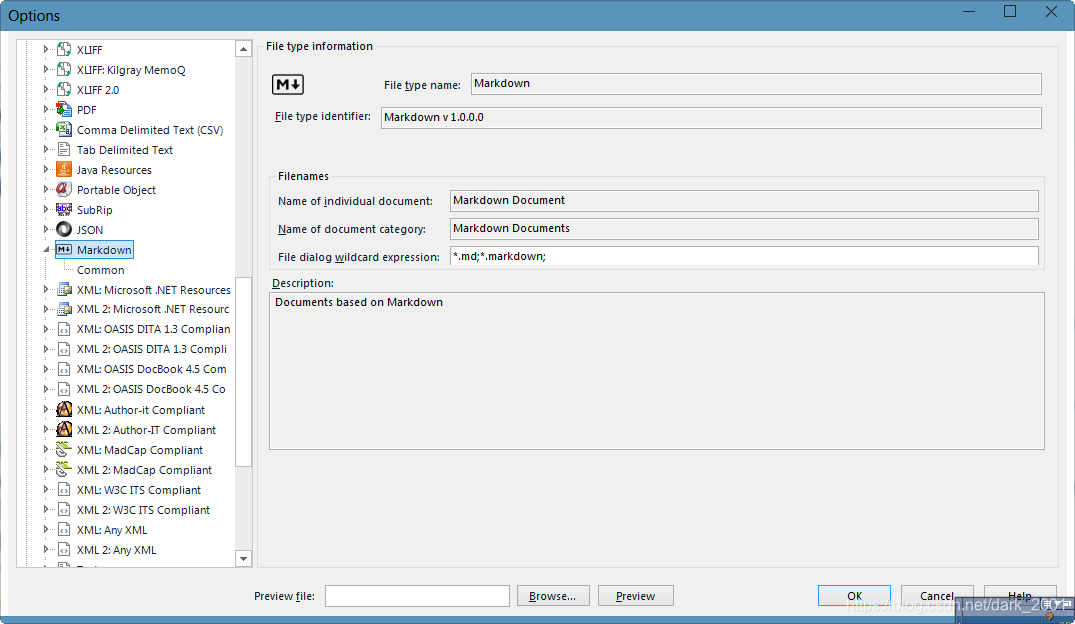 可以看到这个是SDL官方的带有SDL签名的解析器
可以看到这个是SDL官方的带有SDL签名的解析器
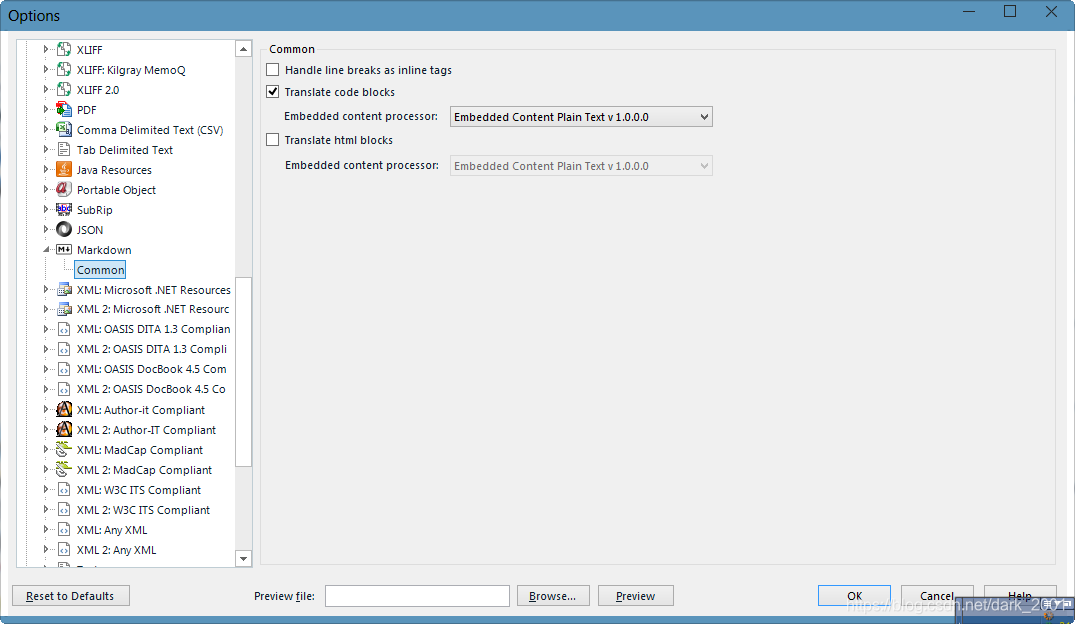
提供了一个设置界面
 提供了
提供了
-
断行的设置
标准的Markdown语法规定了2个空格表示换行。
但是你也可以使用标签换行。 -
是否处理代码块
也就是下面这样的部分
```Print("Hello World!");```
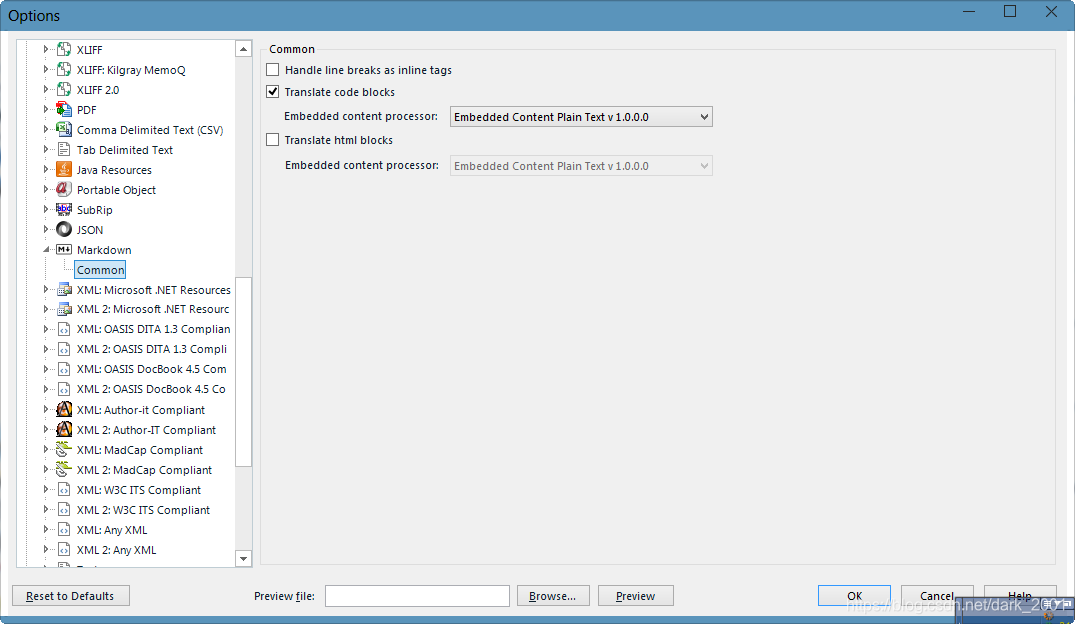
- 是否处理HTML块
Markdown里面是可以直接使用Html语法的还是只有2点限制:
- Html的块级元素必须用空行和Markdown的内容分隔开。
- Html标签前后没有空格。
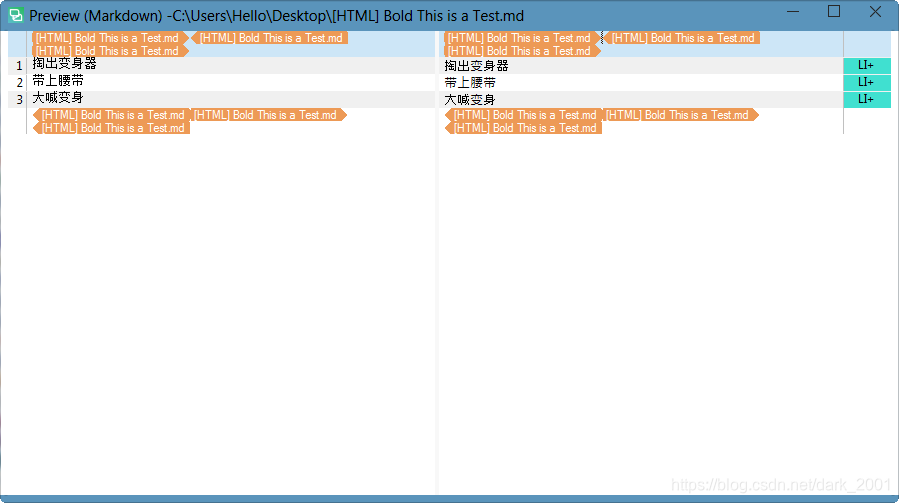
例如我的文件有这样的部分
<ul>
<li>掏出变身器
<li>带上腰带
<li>大喊变身
</ul>
如果没有打开这个选线的话里面的内容是不会被提取出来的
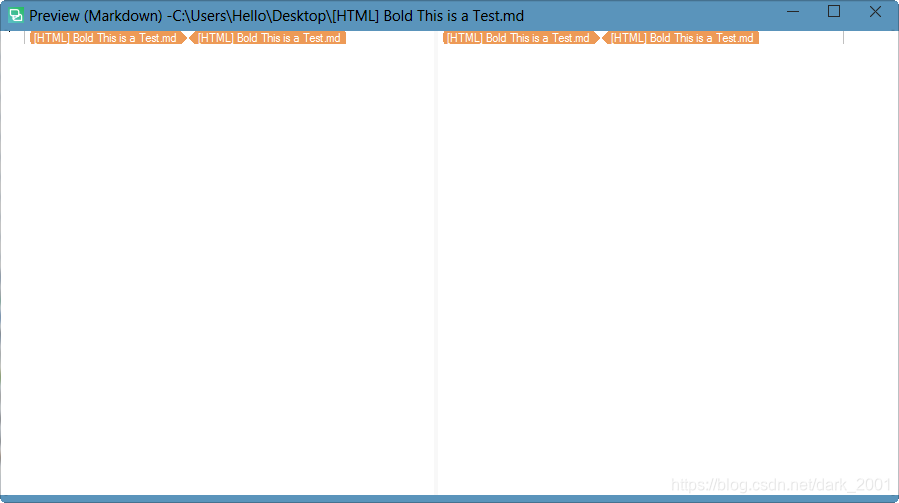 打开这个选项
打开这个选项
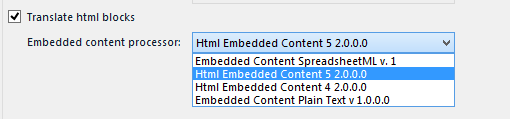
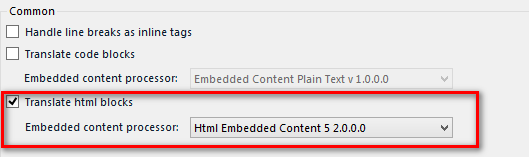 这里我要吐槽一下SDL的设计了,既然是HTML块我当然要用HTML解析器处理,Excel和TXT为什么要出现
这里我要吐槽一下SDL的设计了,既然是HTML块我当然要用HTML解析器处理,Excel和TXT为什么要出现
 从架构上来看之前SDL Trados 2014 2015的时候记得是没有嵌入式解析器的这样,解析将一个文件类型嵌入到另一个文件类型时非常困难,例如将HTML片段嵌入到XML
从架构上来看之前SDL Trados 2014 2015的时候记得是没有嵌入式解析器的这样,解析将一个文件类型嵌入到另一个文件类型时非常困难,例如将HTML片段嵌入到XML
后来SDL改进了设计引入了嵌入式解析器,这样解析器就有两种类型,嵌入式和非嵌入式,然后加了一个定义,非嵌入式解析器可以声明是否使用嵌入式解析器,并且如果是的话那么这个非嵌入式解析器将可以使用任何嵌入式解析器,也就是说嵌入式解析器没有进行分类,所有的都是一样的,当时这样似乎是合理的因为当时只有TXT和HTML两种解析器并且嵌入的情况并不多见,后来随着技术法阵,越来越得多的文件类型使用嵌入式,并且为了解决微软将Excel嵌入到Office文件中(Word, PPT)SDL设计了Excel嵌入式解析器,这时SDL只是简单沿用了之前的设计,因此Excel解析器地位等价于任何嵌入式解析器,可以被任何开启了允许使用嵌入式解析器的非嵌入解析器使用,但是除了微软,谁还能将Excel嵌入到自己的文件类型中??
SDL这里偷懒,没有设计改动架构,这里就问题就显现出来,可想而知未来可能会引起更奇葩的问题,如果现在不调整架构真正出问题时可能就会难上加难。
回归正题我们打开了HTML嵌入式处理得到以下结果
 (SDL的嵌入式解析器)
(SDL的嵌入式解析器)
目前官方提供四种,可以自己扩展,但是一旦开启允许使用,列表中所有的你可以被使用,即无法定义私有嵌入式解析器,嵌入式解析器都是公有的,或者嵌入式解析器没有类型定义
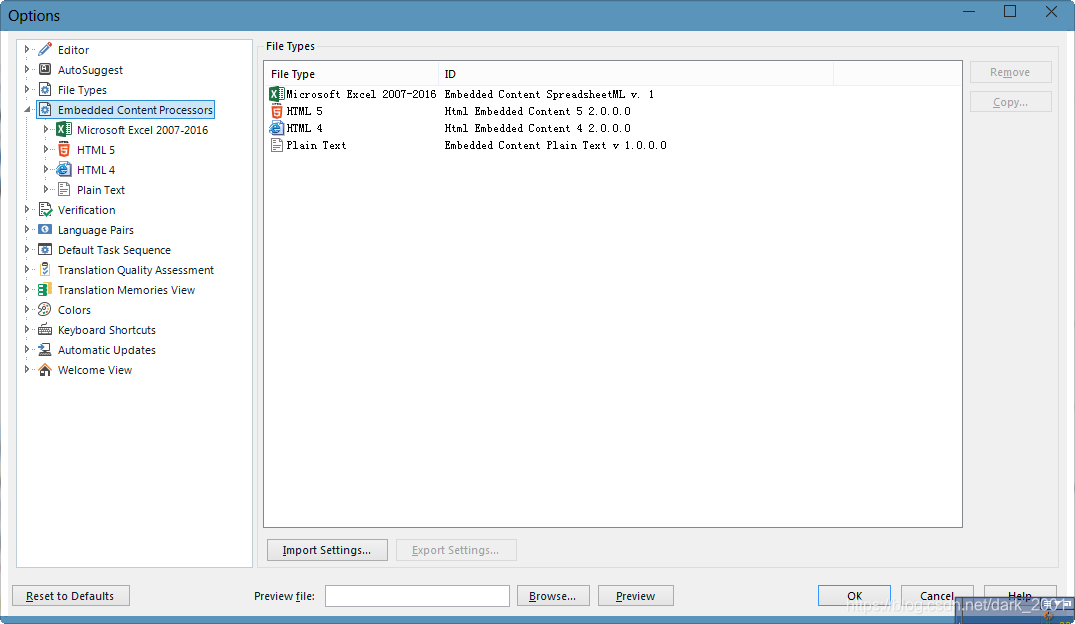 这是HTML嵌入式解析器
这是HTML嵌入式解析器
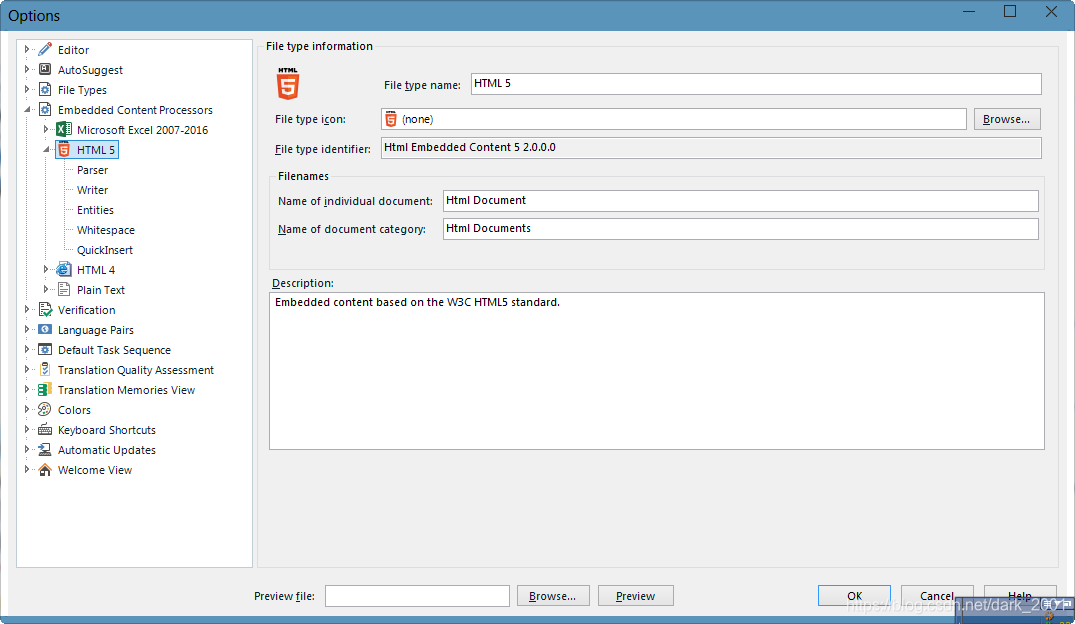
这是TXT嵌入式解析器, 下面还会用到
 ## HTML块的问题比较简单接下来我们来看代码块
## HTML块的问题比较简单接下来我们来看代码块
SDL提供了代码块翻译提取的接口支持,但是实际项目中代码块一般只有注释部分需要翻译,每一种语言注释的格式不尽相同,因此处理的方法也不同,下面以最常见的注释情况问题
//倚筝天波观浩渺
//苍音掀涛洗星辰
//白虹贯日荡魔寇
//明月当空照古今
/*
* 倚筝天波观浩渺
* 苍音掀涛洗星辰
* 白虹贯日荡魔寇
* 明月当空照古今
*/
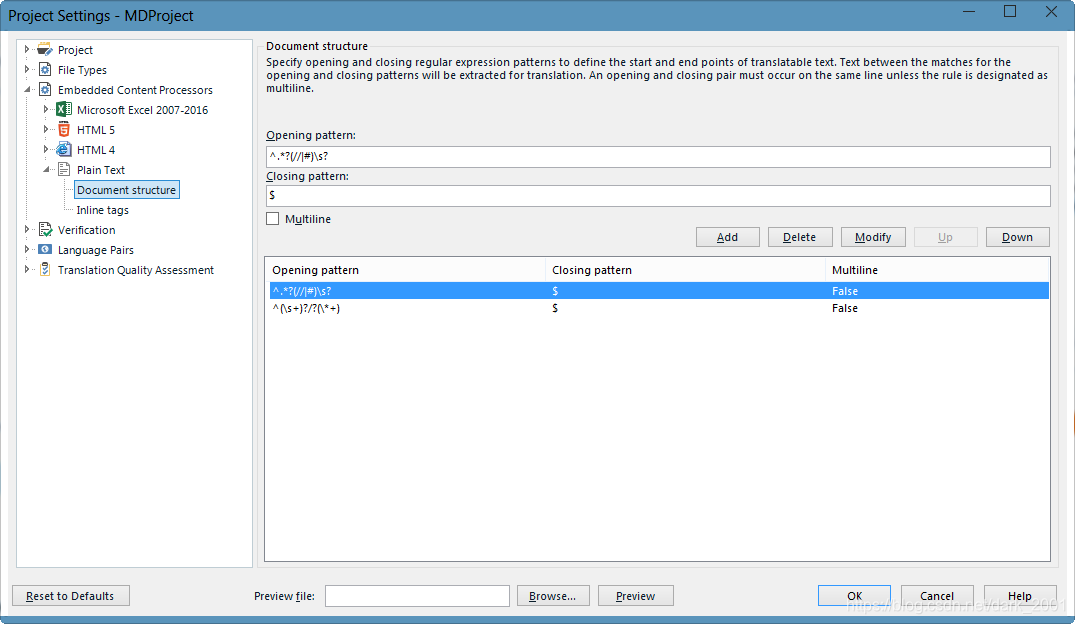
要处理这样的注释,首先打开允许处理代码块并切使用TXT嵌入式处理器处理
 在TXT嵌入式处理器中建立两条规则
在TXT嵌入式处理器中建立两条规则
开始规则
^.*?(//|#)\s?
结束规则
$
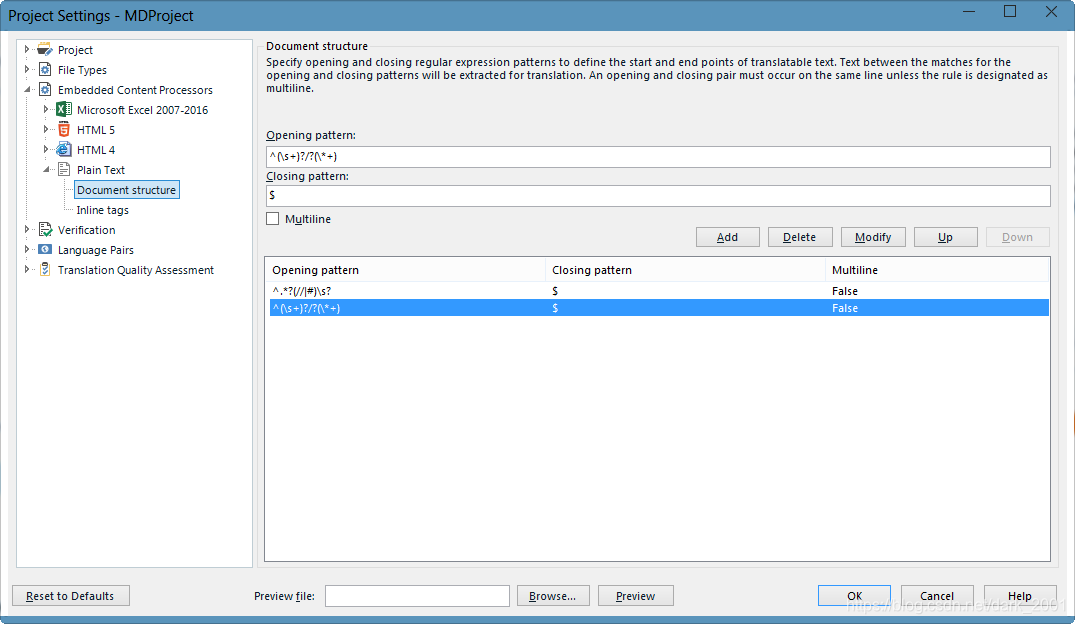
 这里我增加了一个# 来适应 Python语法注释
这里我增加了一个# 来适应 Python语法注释
#这是注释
开始规则
^(\s+)?/?(\*+)
结束规则
$
 然而这并没有结束,正如同HTML4的非严格模式,注释也不一定写的这么严格
然而这并没有结束,正如同HTML4的非严格模式,注释也不一定写的这么严格
/*
* 倚筝天波观浩渺
*苍音掀涛洗星辰
*白虹贯日荡魔寇
* 明月当空照古今
*/
*号后少写一个空格也是可以的,这怎么办呢?
为了兼容这种情况
可以考虑一下代码
while (sr.Peek() > -1)
{
line = sr.ReadLine();
if (line.TrimStart().StartsWith("/*"))
{
if (!CommentStart)
{
CommentStart = true;
sw.WriteLine(line);
}
else
{
if (!line.TrimStart().StartsWith("*"))
{
sw.WriteLine("* " + line);
}
else
{
sw.WriteLine(line);
}
}
}
else if (line.Contains("*/"))
{
CommentStart = false;
sw.WriteLine(line);
}
else
{
if (CommentStart)
{
if (!line.TrimStart().StartsWith("*"))
{
sw.WriteLine("* " + line);
}
else
{
sw.WriteLine(line);
}
}
else
{
sw.WriteLine(line);
}
}
}
这样注释处理完成,这样就完了吗?并没有
技术文档尤其是API SDK中最常见的就是表格形式:
| 参数 | 描述 |
|---|---|
| iDataLength | 频谱数据的长度 [12 - 256],默认是256 |
| timeInterval | 频谱回调的时间间隔,必须是10的倍数,默认是30MS |
往往表格中的一列或者几列都是不需要翻译的,如何来做,首先要了解表格的markdown语法格式
W3C Markdown二维文字表 说明如下
https://www.w3cschool.cn/lme/1i861srj.html
|表格标题|
|表头1|表头2|表头3|
|:-|:-:|-:|
|单元格1|单元格2|单元格3|
|单元格4|单元格5|单元格6|
:-- 表示左对齐,默认也是左对齐
–: 表示右对齐
:–: 表示居中
因此先定义对齐部分
Regex regHeader = new Regex(@"^[-\s:\|]+$", RegexOptions.Compiled); //@"^\|[-\s:\|]+\|$"
string headerRepl = "-->|<!--";
因为Markdown可以使用HTML语法,因此使用HTML注释
<!--
-->
来排除不需要翻译的部分
我们对表格先做几种定义
采用m数字_数字格式
m12_1 代表表格有两列,其中第一列不需要翻译
m12_12 代表表格有两列,其中第一和第二列都不需要翻译
以此类推
public enum mode
{
m0,
m12_1,
m12_2,
m12_12,
m123_12,
m123_23
...省略
}
然后是表格的替换规则
Regex regex12 = new Regex(@"^\|(.*?)\|(.*?)\|$", RegexOptions.Compiled);
string repl12_1 = @"|<!--$1-->|$2|";
string repl12_2 = @"|$1|<!--$2-->|";
string repl12_12 = @"|<!--$1-->|<!--$2-->|";
Regex regex123 = new Regex(@"^\|(.*?)\|(.*?)\|(.*?)\|$", RegexOptions.Compiled);
string repl123_12 = @"|<!--$1-->|<!--$2-->|$3|";
string repl123_23 = @"|$1|<!--$2-->|<!--$3-->|";
...省略
之后是表格的识别,我们通过表头文字来识别表格,对于技术文档,表格一般都是比较规范的,参数表,调用表等
Regex regex_a = new Regex(@"^\|\s+(回调|方法)\s+\|\s+功能\s+\|$", RegexOptions.Compiled); //12_1
Regex regex_b = new Regex(@"^\|\s+(枚举值|参数)\s+\|\s+含义\s+\|$", RegexOptions.Compiled); //12_1
Regex regex_c = new Regex(@"^\|\s+(.*?)函数\s+\|\s+(函数名|方法签名)\s+\|$", RegexOptions.Compiled); //12_12
Regex regex_d = new Regex(@"^\|\s+接口\s+\|\s+变化\s+\|$", RegexOptions.Compiled); //12_1
Regex regex_e = new Regex(@"^\|\s+错误码\s+\|\s+(含义|错误描述)\s+\|$", RegexOptions.Compiled); //12_1
Regex regex_f = new Regex(@"^\|\s+(参数|名称)\s+\|\s+描述\s+\|$", RegexOptions.Compiled); //12_1
...省略
接下来就是在MD文件中识别表格并按规则注释掉表格内容
string line = string.Empty;
bool tableStart = false;
mode m = mode.m0;
bool matched = false;
while (sr.Peek() > -1)
{
line = sr.ReadLine();
if (line.Trim().StartsWith("|") && line.Trim().EndsWith("|"))
{
if (!tableStart)
{
tableStart = true;
sw.WriteLine(line);
if (!matched)
{
if (regex_a.IsMatch(line))
{
m = mode.m12_1;
matched = true;
}
}
if (!matched)
{
if (regex_b.IsMatch(line))
{
m = mode.m12_1;
matched = true;
}
}
if (!matched)
{
if (regex_c.IsMatch(line))
{
m = mode.m12_12;
matched = true;
}
}
if (!matched)
{
if (regex_d.IsMatch(line))
{
m = mode.m12_1;
matched = true;
}
}
if (!matched)
{
if (regex_e.IsMatch(line))
{
m = mode.m12_1;
matched = true;
}
}
if (!matched)
{
if (regex_f.IsMatch(line))
{
m = mode.m12_1;
matched = true;
}
}
if (!matched)
{
if (regex_w.IsMatch(line))
{
m = mode.m123_23;
matched = true;
}
}
if (!matched)
{
if (regex_x.IsMatch(line))
{
m = mode.m123_12;
matched = true;
}
}
if (!matched)
{
if (regex_y.IsMatch(line))
{
m = mode.m1234_1;
matched = true;
}
}
if (!matched)
{
if (regex_z.IsMatch(line))
{
m = mode.m1234_12;
matched = true;
}
}
line = sr.ReadLine();
if (regHeader.IsMatch(line))
{
//line = regHeader.Replace(@"\|", headerRepl);
//line = line.Substring(3, line.Length - 7);
//line = "<!--" + line + "-->";
sw.WriteLine(line);
}
else
{
line = ProcressLine(line, m);
sw.WriteLine(line);
}
}
else
{
line = ProcressLine(line, m);
sw.WriteLine(line);
}
}
else
{
tableStart = false;
m = mode.m0;
matched = false;
sw.WriteLine(line);
}
}
if (sr != null)
sr.Close();
if (sw != null)
sw.Close();
}
处理工厂 以及子处理
private string ProcressLine(string line, mode m)
{
switch (m)
{
case mode.m0:
return line;
case mode.m12_1:
return ProcressLine12_1(line);
case mode.m12_2:
return ProcressLine12_2(line);
case mode.m12_12:
return ProcressLine12_12(line);
...省略
default:
return line;
}
}
private string ProcressLine12_1(string line)
{
line = regex12.Replace(line.Trim(), repl12_1);
return line;
}
private string ProcressLine12_2(string line)
{
line = regex12.Replace(line.Trim(), repl12_2);
return line;
}
private string ProcressLine12_12(string line)
{
line = regex12.Replace(line.Trim(), repl12_12);
return line;
}
...省略
这样经过处理我们得到以下结果
左侧是源文件,右侧是处理后
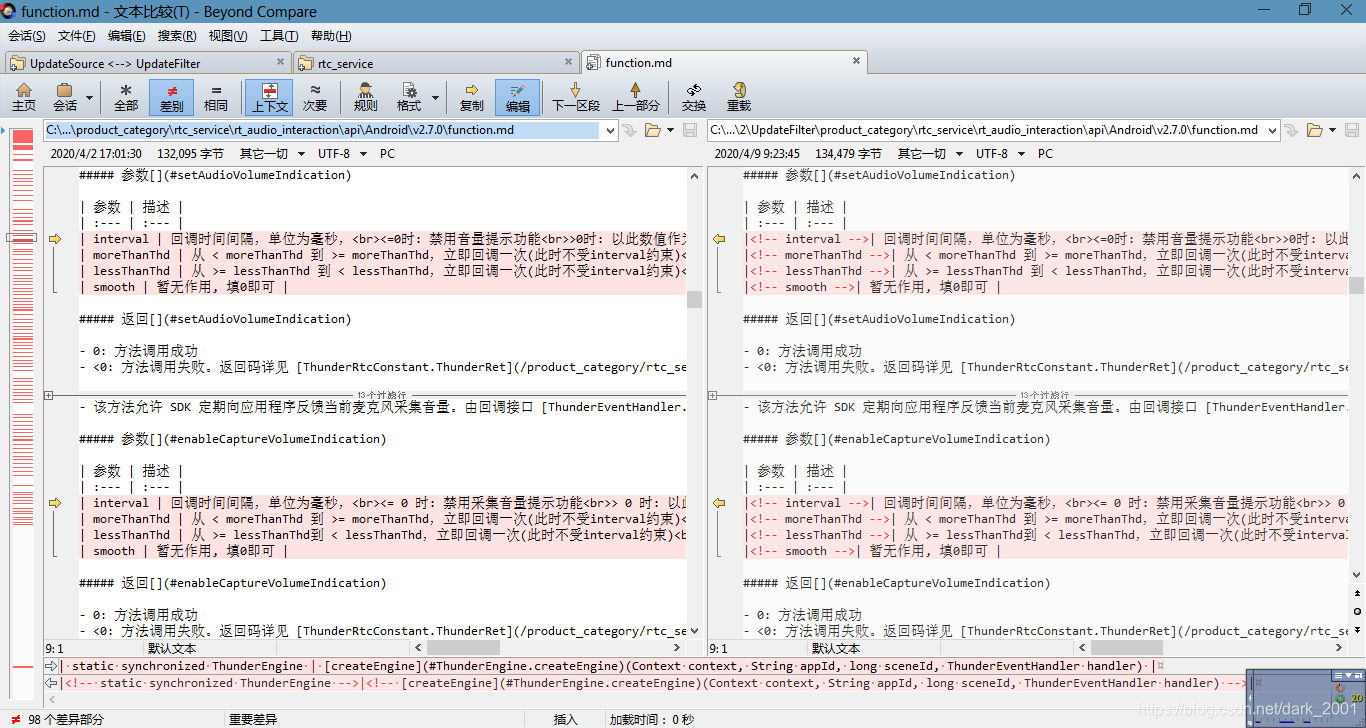 接下来这个文件就可以进入SDL Trados Studio中处理
接下来这个文件就可以进入SDL Trados Studio中处理
最后经过处理
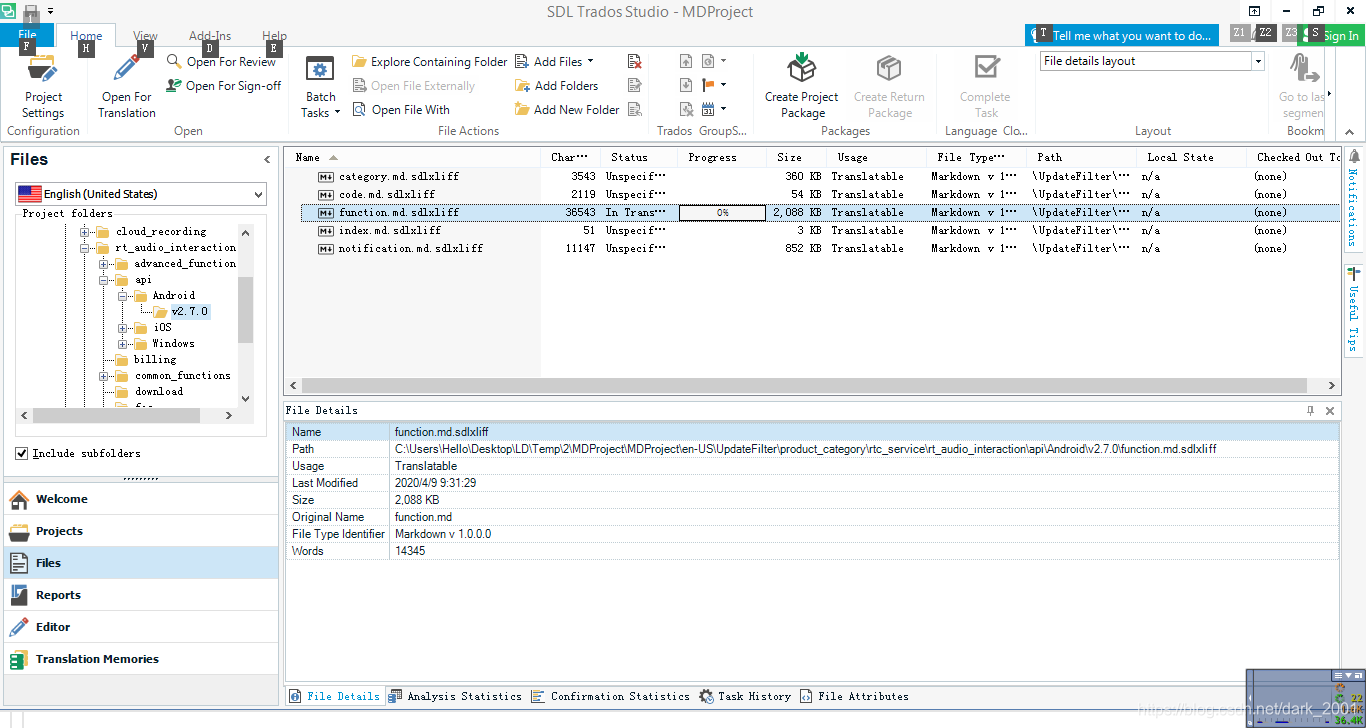
 最后生产加翻文件之后
最后生产加翻文件之后
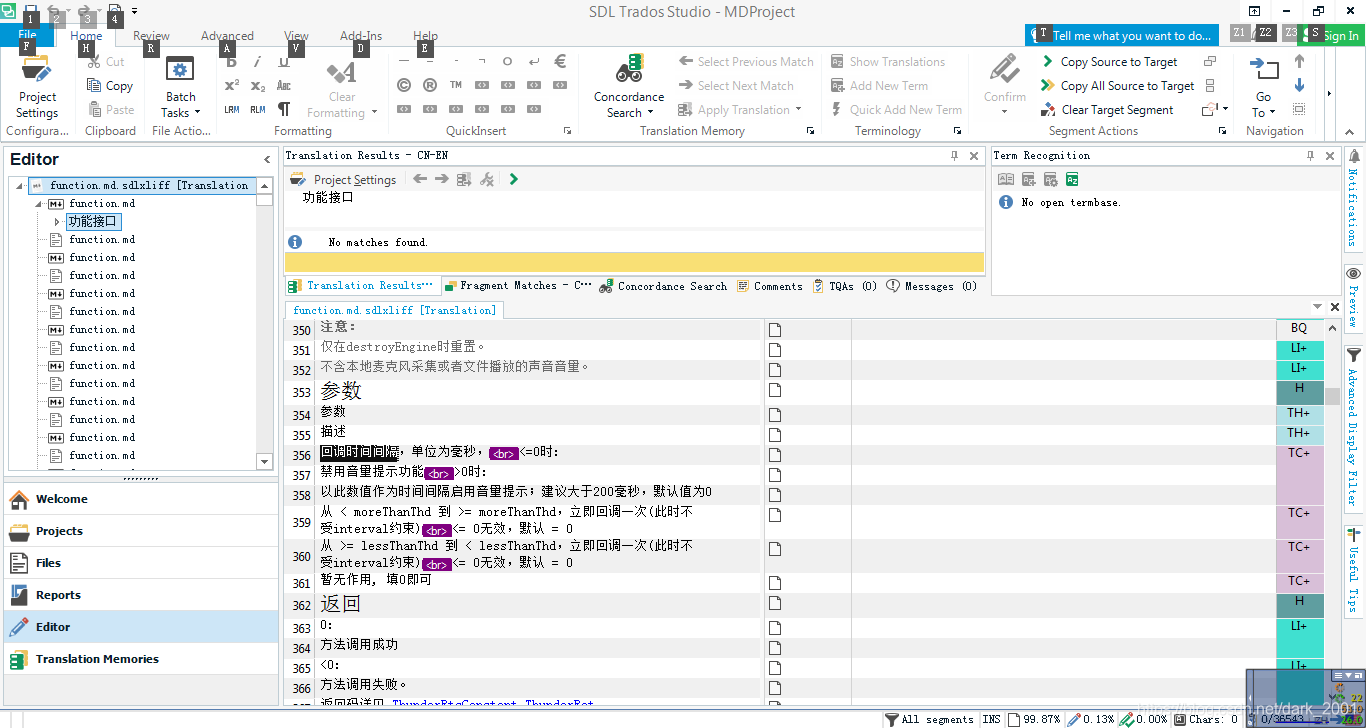
左侧是源文件,右侧是SDLTrados翻译处理后
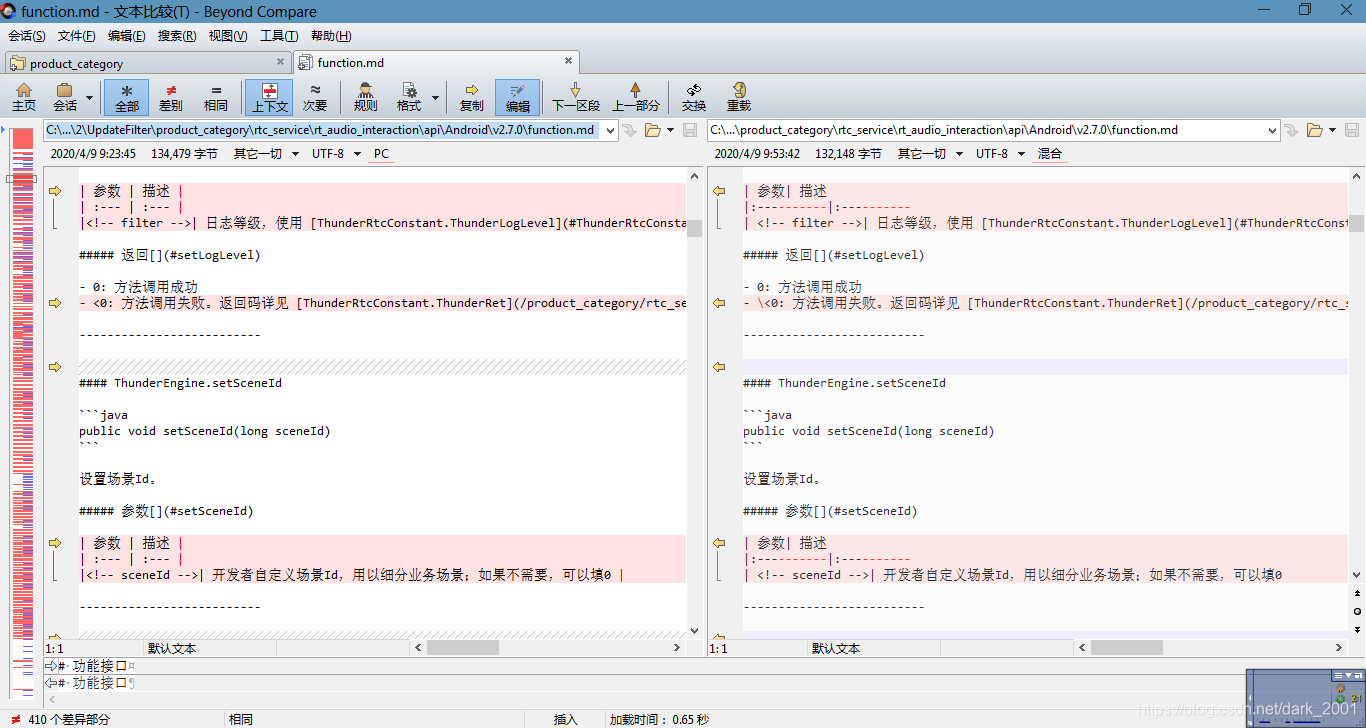 可以看到一个奇怪的问题表格生成后表格的结束符号 | 丢掉了,可能是这个解析器还是有BUG存在,我们只好来就付这个BUG
可以看到一个奇怪的问题表格生成后表格的结束符号 | 丢掉了,可能是这个解析器还是有BUG存在,我们只好来就付这个BUG
while (sr.Peek() > -1)
{
line = sr.ReadLine();
if (line.Trim().StartsWith("|"))
{
if (!tableStart)
{
tableStart = true;
sw.WriteLine(line+"|");
line = sr.ReadLine();
if (regHeader.IsMatch(line))
{
//line = regHeader.Replace(@"\|", headerRepl);
//line = line.Substring(3, line.Length - 7);
//line = "<!--" + line + "-->";
sw.WriteLine(line+"|");
}
else
{
line = line.Replace("<!--", "");
line = line.Replace("-->", "");
sw.WriteLine(line+"|");
}
}
else
{
line = line.Replace("<!--", "");
line = line.Replace("-->", "");
sw.WriteLine(line+"|");
}
}
else
{
tableStart = false;
sw.WriteLine(line);
}
}
这样就完成了MD文件的翻译
翻译完成后的文件和源文件还有几个不同点:
- SDL Trados 使用了严格的MD写法(Strict) 即任何元字符,也就是Markdown相关的指令字符前面都要加转义字符\
例如 < 变成了 < _变成了 _
Markdown其实和HTML是非常类似的,很多时候能够自识别和自使用非严格写法,不加转义字符也是可以的,但是加了转义字符也没有问题,只是看起来有些复杂 - 断行的处理,和其他文件类型以及HTML文件类型一样,技术撰写这有的时候在写作时并没有注意这个断行是一定要有的(硬回车)还是只是为了显示(软回车),并且混用回车,通常发生该用硬回车
的时候没有使用
如果这里设置不当可能会导致不改连在一行的内容连接在了一起
Markdown处理的源代码我已开源 欢迎Star和Fork https://github.com/Dark-20001/MarkdownTableProcessor/blob/master/Processor.cs
给自己挖个坑吧
下次写一下SDL Trados Studio 2019 SR2中第二代HTML/XML解析器和第一代的对比测试


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









