







参考《超标量处理器》姚永斌著
文章目录
超标量处理器设计——第九章_执行
9.1 概述
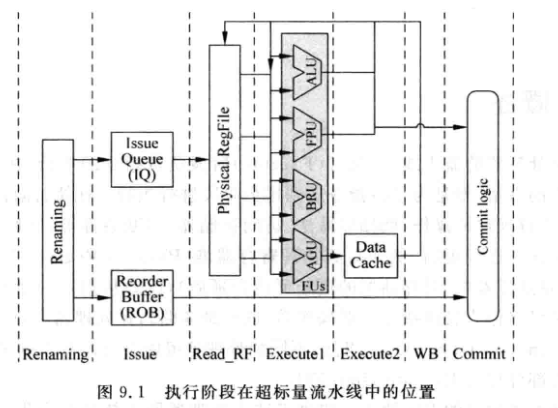
- 每个FU都有一个1-M仲裁器, 每个仲裁器和物理寄存器堆的读端口一一对应
-
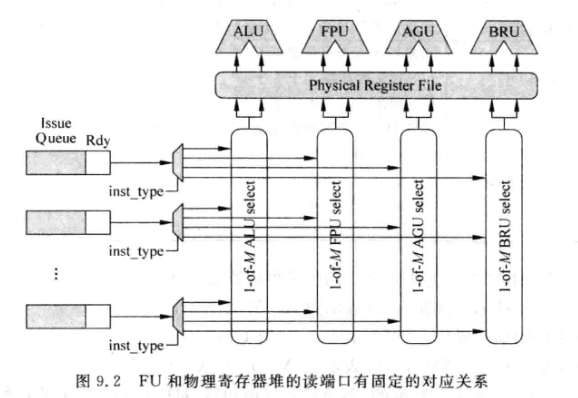
9.2 FU类型
9.2.1 ALU
-
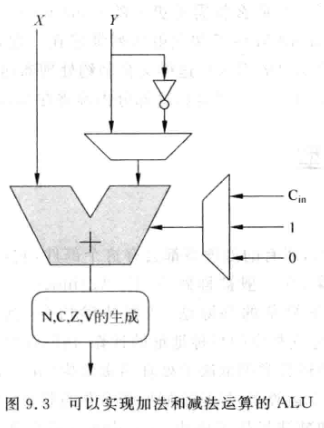
Arithmetic and Logic Unit
-
MIPS中如果加减法发生溢出, 需要产生异常
-
ARM中, 直接定义了状态寄存器CPSR:
-

-
ARM中定义了四种加减法操作:
- 不带进位加: X + Y = X+Y+0
- 带进位加: X + Y + Cin
- 不带借位减: X-Y = X + (~Y + 1) , 实际就是补码运算
- 带借位减: X-Y-1 = X + (~Y+1)-1 = X + (~Y)
-
-
-
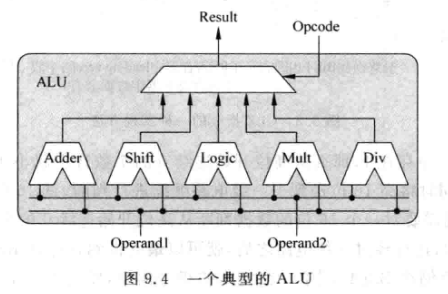
一些ALU可能还会包含简单的乘除法, 而这些操作周期数较多,对bypass功能引入了一些复杂度:
-
-
MIPS和ARM都集成了CLZ (Counting Leading Zero),用来判断32位寄存器从高位开始连续0的个数, 用来做优先级判断:
-
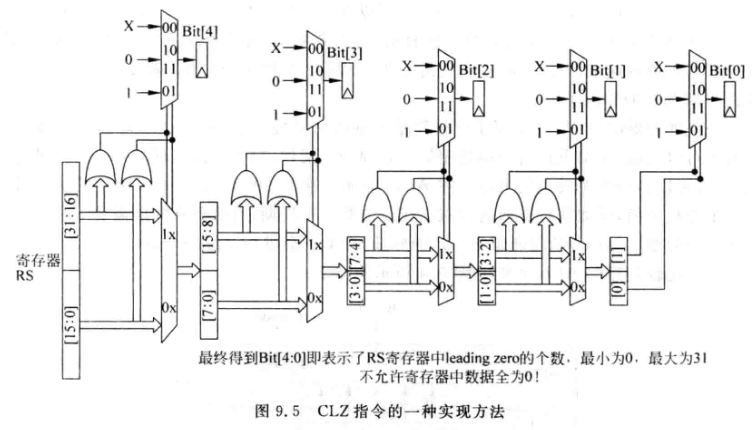
-
一些处理器使用单独的乘法器FU获得高并行度, 还会自带乘累加功能(MADD)
-
一些处理器为了节省面积,将整数转换成浮点数,放入浮点FU中计算乘法
9.2.2 AGU
- Address Generate Unit
- Load/Store携带的存储器地址通过AGU处理
- 普通流水线处理器中一般这个工作交给ALU处理, 但是超标量处理器为了并行执行,单独使用一个FU来计算地址
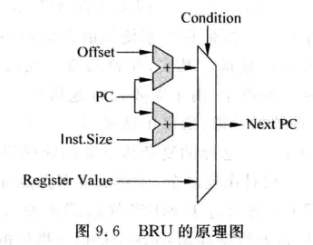
9.2.3 BRU
- Branch Unit
- 负责分支指令: branch, jump, Call, Return等
- 将指令携带的目标地址计算出来,根据条件决定是否使用
- 还存在分支预测正确性检查
-
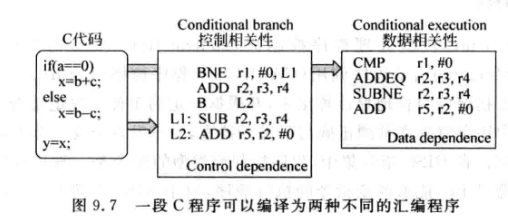
条件码
-
ARM和PowerPC采用与MIPS不同的分支方法, 即条件码:
-
-
条件码的优点:
- 条件码降低分支指令使用频率, 对超标量处理器来说能获得更好的性能.
-
缺点:
-
条件码占据了指令编码的一部分,导致可分配给寄存器的部分变少了,例如ARM加入了4位条件码后, 实际可用的指令编码空间就只有32-4=28位了. 简介导致其只支持16个通用寄存器.
-
此外,条件码会使得所有指令都进入流水线, 会存在大量无效指令, 效率不高
-
另外, 条件码的可能导致寄存器重命名时的额外麻烦:
-
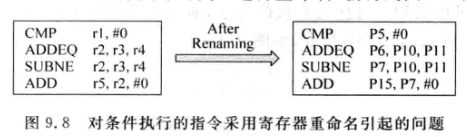
-
该图中,如果SUBNE不执行, 那么ADD就会使用错误的物理寄存器P7, 而实际上应该用的是P6
-
x86对该问题的一个解决方案是硬件插入额外的指令:
-
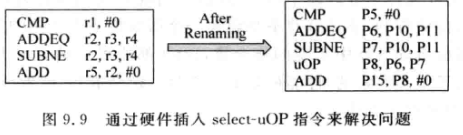
-
uOP指令根据两个条件执行的结果对物理寄存器进行选择, 但是必须保证条件执行指令成对出现
-
分支正确性检查
- 在流水线的取指阶段会将预测跳转的分支指令保存在一个缓存中, 称为分支缓存(branch stack)
- BRU的到一条分支的结果时, 会在分支缓存中进行查找, 有四种情况:
- BRU的结果是跳转, 且分支缓存中能找到他, 跳转地址也相同 ---- 预测正确
- BRU的结果是跳转, 但是分支缓存中找不到他 ---- 预测失败
- BRU的结果是不跳转, 且分支缓存中找不到他 ---- 预测正确
- BRU的结果是不跳转, 但是分支缓存中能找到他 ---- 预测失败
- 如果预测正确, 释放该分支占用的资源, 如checkpoint或分支缓存
9.3 旁路网络
-
目的: 为了使存在相关性的指令能背靠背执行
-

-
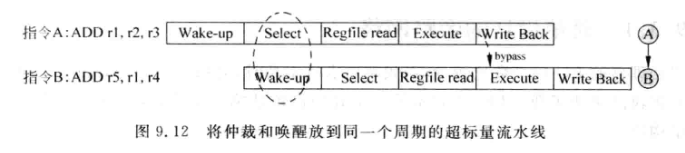
-
源操作数从物理寄存器读出,还需要经过一段时间才能到FU输入口, 这些周期称为Source Drive阶段
-
FU将一条指令结果计算出来后, 还需要经过复杂的旁路网络才能到达所以FU的输入(或PRF输入), 这个阶段称为Result Drive阶段.
-

9.3.1 简单设计的旁路网络
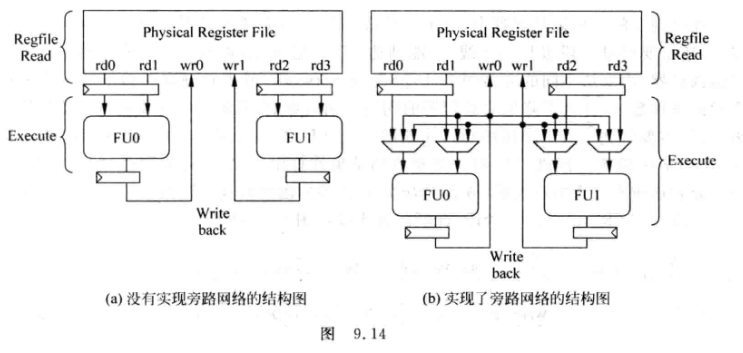
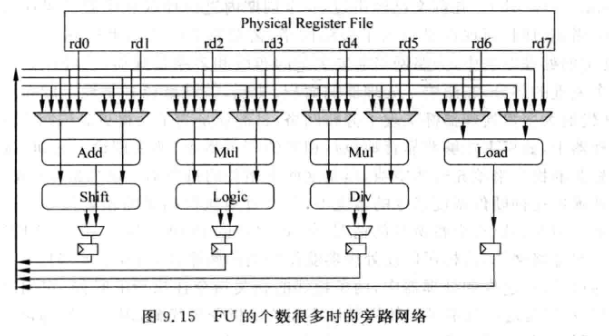
-
当一个FU中有多个功能, 例如ALU可以计算移位,也可以计算加减法. 对这样的FU需要用多路选择器, 从不同的计算电路中选择一个结果放到旁路网络, 这种做法称为 bypass sharing
-
如果一个FU中所有计算单元周期数不等, 可能会导致某一个周期FU中的两个计算单元竞争旁路网络的情况:
-

-
一种解决方法是借鉴推测唤醒的做法, 一条指令在到达FU之前,先检查FU是否可以被自己使用. 例如上个周期FU执行了latency = 3的指令, 那么本周期就不能执行latency=2的指令了.
-
具体实现:
-
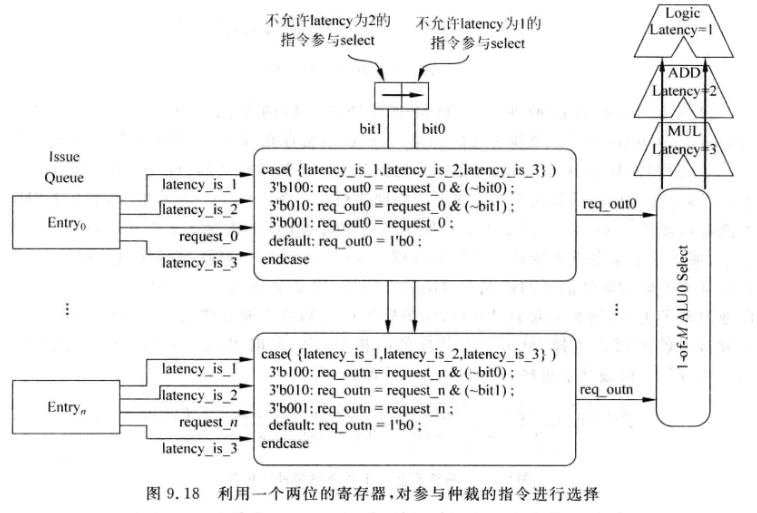
-
用一个两bit的控制寄存器, 每周期会逻辑右移一位.
-
当本周期被仲裁电路选中的是latency=3的指令, 就在下一周期将控制寄存器设置为2’b10. 表示下周期不允许latency=2的指令参与仲裁. 下下周期控制寄存器变为2’b01, 表示下下周期不允许latency =1的指令参与仲裁
-
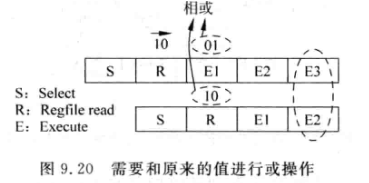
假设本周期仲裁电路选中latency=3的指令, 下周期仍然选中latency=3的指令, 此时的处理是将两次的控制寄存器相或:
-
-
9.3.2 复杂设计的旁路网络
-
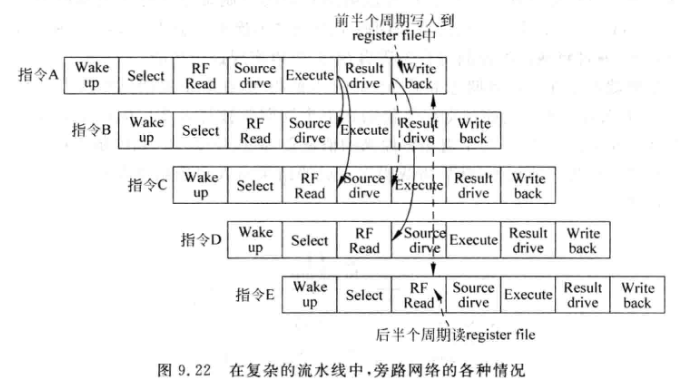
-
指令B可以在Execute阶段从A的Result drive阶段获得操作数
-
指令C可以在Source drive阶段从A的Result drive阶段获得操作数, 或者C也可以在Execute阶段, 从A的Write Back阶段获得操作数
-
指令D可以在Source drive 阶段从A的write back阶段或的操作数
-
指令E在流水线RF read阶段读取物理寄存器堆(PRF)时, 可以的到指令A的结果, 所以其不需要从旁路网络获得操作数
-
旁路网络会使得流水线变得很复杂:
-
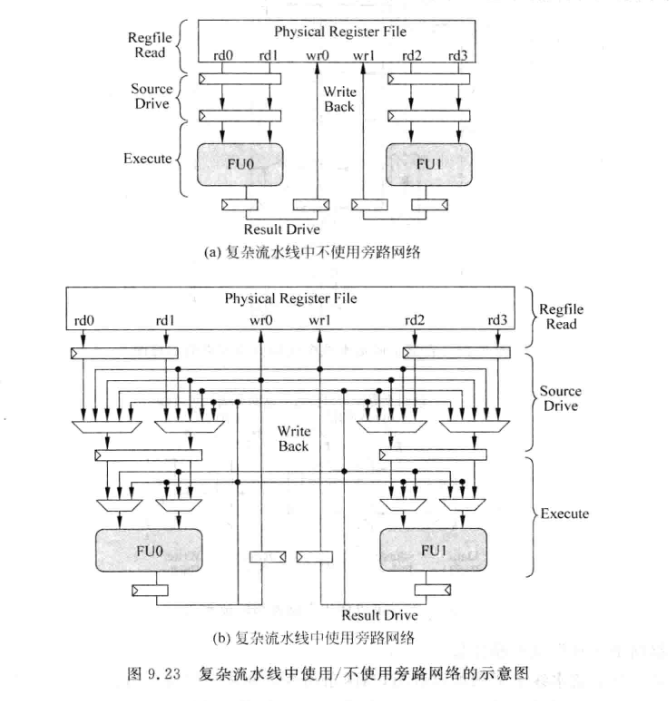
-
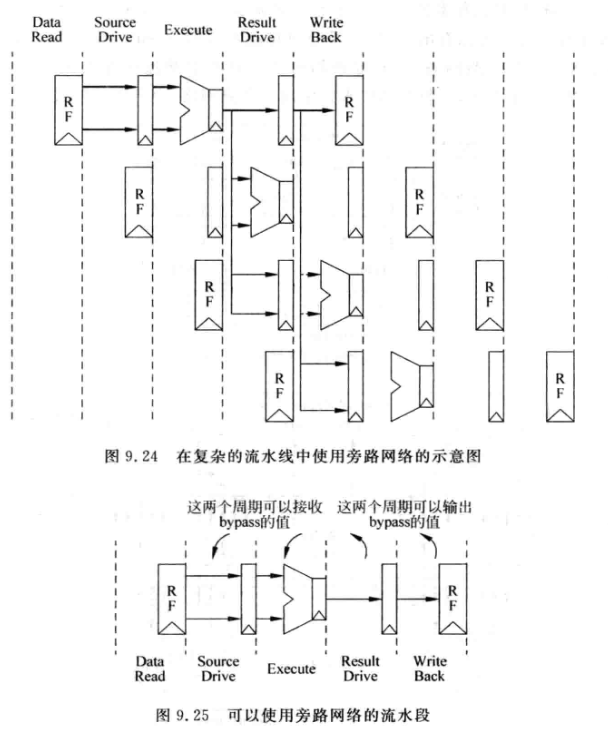
-
可以发现, 在上述流水线中, 当两条指令间隔的指令超过两条时, 就不需要通过旁路网络或的操作数了
-
增大流水线级数会导致更复杂的旁路网络
-
不需要在所有FU之间都设置旁路网络, 例如AGU会用到ALU结果, 但是ALU不会用到AGU的结果
-
9.4 操作数的选择
-
FU 的输入端需要从物理寄存器的输出或所有旁路网络中进行选择.
-
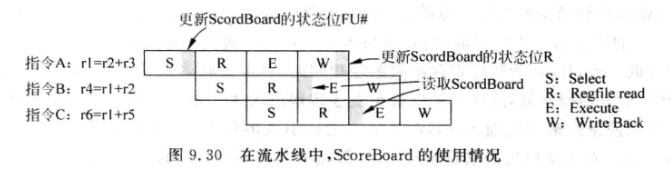
一个物理寄存器在生命周期内会有多种状态, 他可能被写到PRF, 还可能需要在指令顺利离开流水线时写到ARF中. 这些信息都可以保存在一个表格内,称为 ScoreBoard
-

-
FU# : 从旁路网络取出某个物理寄存器时,需要知道来自哪个FU, Scoreboard的FU#记录了该信息. 当一条指令被仲裁器选中时, 如果指令有目的寄存器, 那么就将该指令在哪个FU中执行的信息写到该表中
-
R : 表示该寄存器已经被FU计算完毕, 并写到了PRF中, 后续指令如果要使用该寄存器器, 可以直接从PRF中读取. 如果该位为1, 就不需要关注FU#信息了.
-
在流水线中加入该表格:
-
-
会影响Select阶段(写入FU#)和Write Back阶段(更新R)
-
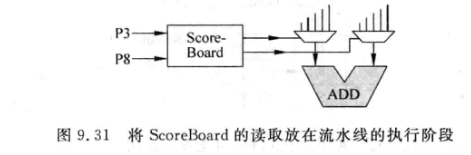
上图中指令C可以在EX阶段读取Scoreboard, 因为A已经将结果写到PRF了, 所以此时C读取SB后知道应该去PRF中取操作数, 但是这样会导致EX阶段延时变长. 对应的电路如下:
-
-
C指令其实在RF read阶段就开始读取SB, 打一拍后进入EX:
-
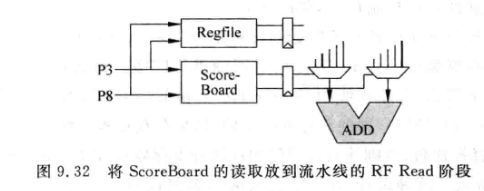
-
这种方法能缓解EX延时过长的问题, 但是会导致C读SB时, R位还没有置1, C会错误的认为自己应该从旁路网络去获得操作数
-
可以简单地打个补丁, 也就是如果发现写入SB时(更新R)与读取SB时(RF阶段读取FU#)所用的物理寄存器相同(一个地址), 就将EX的多路选择器切到PRF上, 而不是实际读出的FU#
-
-
-
如果处理器每周期可以执行N条指令, 那就需要SB有2N个读端口, 而SB需要分两次写如FU#和R, 所以又需要2N个写端口!
-
除了使用SB, 另一个方案是使用比较器产生MUX的控制信号:
-
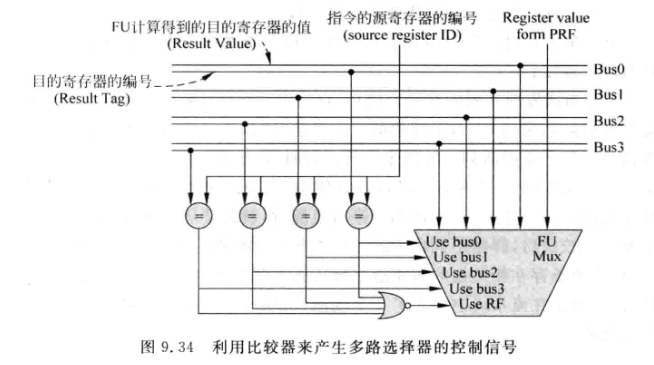
- FU在将计算结果广播到bus上时, 同时也将该指令的目的寄存器编号也一起广播
- 每条指令在从旁路网络选择操作数的两个周期内, 也就是Source Drive和Ex阶段将源操作寄存器编号和FU送来的目的寄存器编号进行比较, 如果相等, 说明此时需要从旁路网络获得操作数, 否则就是从PRF获取.
- 代价是更大的面积和功耗, 但是很简单.
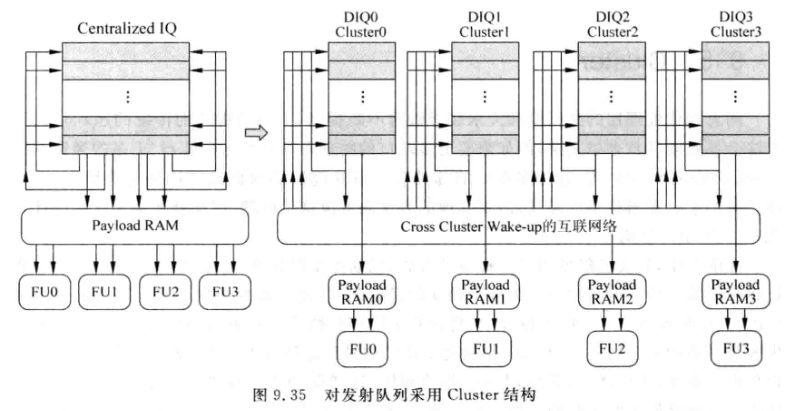
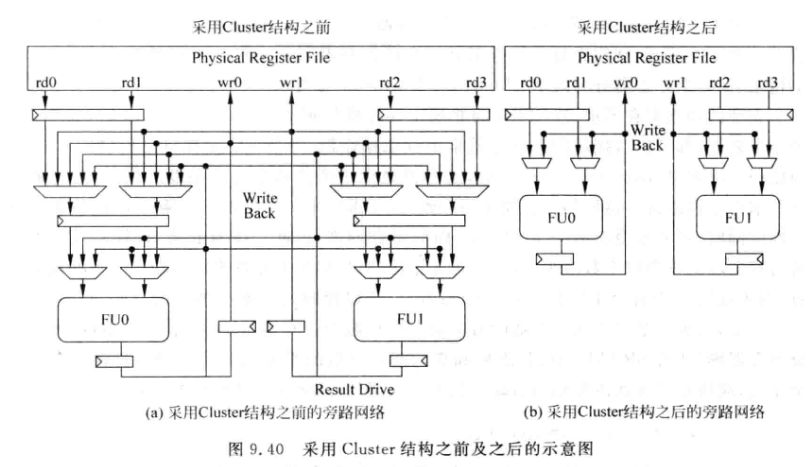
9.5 Cluster
- Cluster是一种结构实现的思路, 例如将浮点FU和整数FU的旁路网络分开, 或者将一个IQ分为多个独立的IQ
9.5.1 Cluster IQ
-
集中式的IQ往往需要更多的读写端口和更大的容量, 导致面积和延时都很大
-
可以使用Cluster的结构, 将集中IQ拆分成多个小的分布式IQ, 每个IQ只对应一个或几个仲裁电路和FU
-
带来的优点:
- 可以减少每个分布式IQ的端口个数
- 每个分布式IQ的仲裁电路只需要负责很小一部分的指令, 可以加快仲裁电路的速度
- 分布式IQ的容量较小, 其中的指令被唤醒的速度也较快
-
缺点:
- 被仲裁电路选中的指令对其他IQ中的指令进行唤醒时, 走线会更长, 延迟会增大, 甚至需要增加一级流水, 此时原来有相关性的两条指令就不能背靠背了, 会引入一个bubble.
-
- 被仲裁电路选中的指令对其他IQ中的指令进行唤醒时, 走线会更长, 延迟会增大, 甚至需要增加一级流水, 此时原来有相关性的两条指令就不能背靠背了, 会引入一个bubble.
-
解决办法:
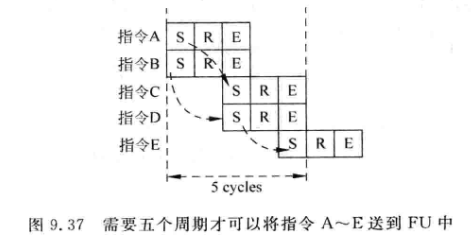
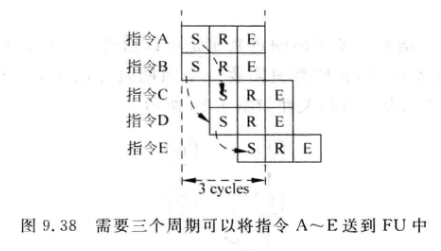
- 例如:下图中的五条指令,只需要一个周期就可以从FU中得到结果,相关性如图:
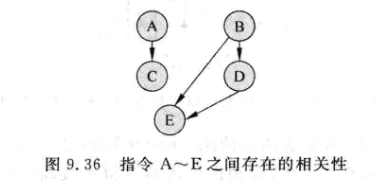
-
正常情况下: 第一个周期A,B被仲裁选中, 第二周期CD选中,第三周期E选中
-
采用了分布式的IQ之后,假设跨越Cluster唤醒需要消耗一个周期,此时有两种情况:
-
ABE在一个cluster,指令CD在另一个Cluster中。AB在被选中后,要等一个周期才能唤醒C和D, D被选中后也要等一个周期才能唤醒E:
-
-
AC分到同一个Cluster中, BDE分到另一个Cluster中:
-
- 可见执行效率跟在不在一个Cluster有关,需要仔细规划分配算法
-
-
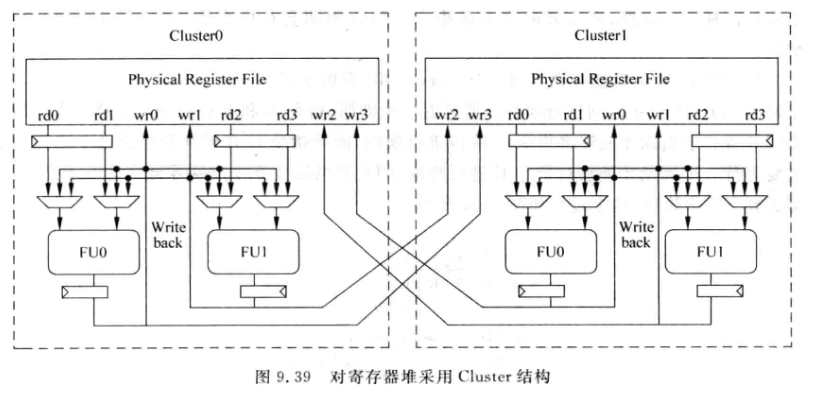
对于非数据捕捉结构的超标量处理器, 指令在被仲裁电路选中后会先读取PRF, 因此需要PRF支持多个读端口,可以对寄存器堆也使用Cluster结构:
-
-
这种做法可以减少读端口,但是无法减少写端口
-
SRAM的面积近似跟端口个数的平方成正比,因为布线资源随端口数平方增长,所以减少读端口仍然可以减少面积。
-
9.5.2 Cluster Bypass
-
对旁路网络使用Cluster之后, 旁路网络只分布在每个Cluster内部:
-
-
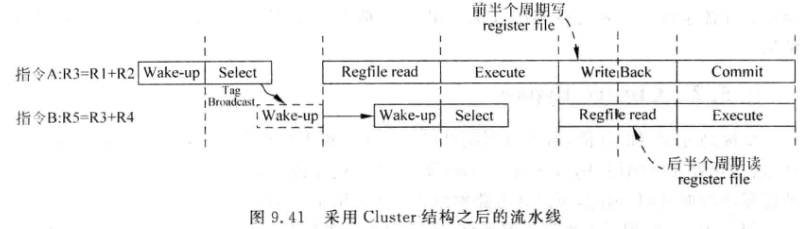
因为旁路网络大幅度简化了,所以可以去掉Source Drive和Result Drive两个阶段,节省了两级流水,这一同一个Cluster的指令仍然可以背靠背,不同Cluster的指令只需要间隔1个周期:
-
-
将一个FU的结果送到其他Cluster的FU输入往往延时较大, 所以可能需要为此加一级流水:
-
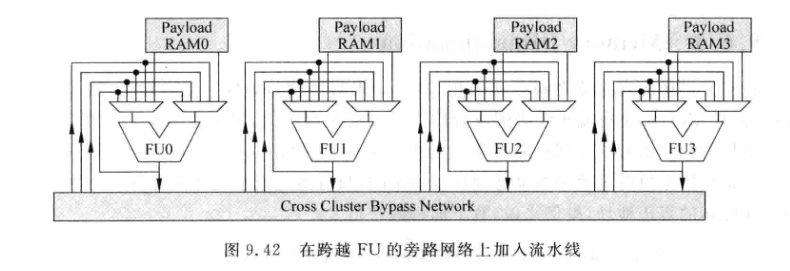
-
跨Cluster进行唤醒会引入一个周期延迟, 跨FU的旁路网络也需要一个周期延时,但是实际上这两级延时不是叠加的,而是合并的:
-
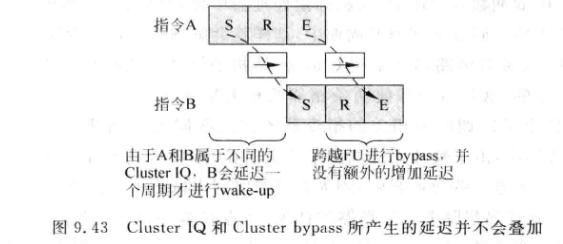
9.6 存储器指令的加速
9.6.1 Memory Disambiguation
-
LOAD, STORE指令之间也有相关性:
-
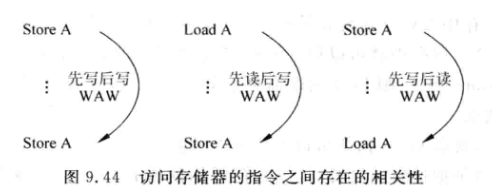
-
一般store指令都是顺序执行的,这样可以避免WAW相关性,但load可以有不同的实现方式:
-
完全的顺序执行:
- 最保守,不能将load提前执行,导致所有相关指令执行都偏晚
-
部分的乱序执行:
-
每当一条store指令的地址被计算出来后,这条store和它后面的store指令之间的所有load都可以乱序
-
两条stroe指令之间的load可以乱序, 避免了WAR相关性
-
当一条store被仲裁电路选中,位于其后的load就可以参与仲裁了,且这些load可以乱序地被选中
-
但是被选中的load还是需要和前面所有已经执行的store指令携带的地址进行比较,以判断RAW相关性
-
需要一个缓存来保存被仲裁电路选中但还没顺利离开流水线的store指令,该缓存称为Store Buffer
-
如果load在store buffer中发现了地址相等的store指令, 说明发现了RAW相关性,直接从该缓存中就可以得到load所需的数据
-
store就像一扇门, 当其被仲裁电路选中之后,就可以开门,放行之后的load指令进入仲裁器:
-
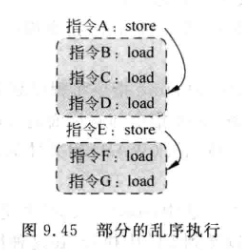
-
实际上,这种方式只保证store指令是顺序的,例如A先执行,A唤醒了C,但是B,D还没进入仲裁;此时指令E又被仲裁电路选中,它使得F和G也有资格参与仲裁;因此这时B,D,F,G都可以被仲裁电路乱序选中
-
新的问题:E指令先于B,D被仲裁选中时,指令B和D被选中时查找Store buffer会有两条store指令,但是B,D与E实际没有相关性,因此需要鉴别Store Buffer中哪些store在本条load的前面,哪些在后面。有如下方法:
-
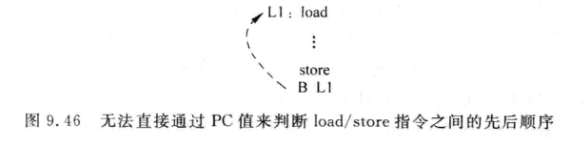
用PC值标记先后顺序。实际不可靠,因为如果store之后有向前跳转的指令,该方法就失效了:
-
-
用ROB编号。ROB记录了指令进入流水线的先后顺序,ROB中的地址可以表示先后。但是实际ROB不止存放load和store,导致这个标号非常稀疏,比较大小时浪费比较器面积
-
在解码阶段,为load和store分配一个编号,编号宽度根据流水线最多支持的load/store来决定
-
-
这些记录load,store顺序的标号固然可以解决问题,但是带来了复杂度,实际上可以要求B,C,D都被仲裁电路选中之后,才能让E进入仲裁。当然代价是牺牲性能,因为如果store指令A发生缺失,E就不能被选中:
-

- 完全的乱序执行:
- store仍然是顺序执行,但load将不再受限于它前面的store指令,只要其操作数准备好,可以立即参与仲裁
- load的仲裁,可以按照oldest-first的策略,乱序进入仲裁器(这里的乱序指的是不需要关store在前还是在后)
- 可以这么做是基于一个观察:RISC处理器中,ARF的数量实际是较多的,很多变量可以直接放到寄存器中。程序中store/load指令间的RAW相关性不会很多,可以通过提前执行load来尽快唤醒更多指令,以获得更大的并行性
- CISC处理器中由于可用的通用寄存器较少,需要经常跟mem进行通信。Store/load存在RAW的情况就较多:
-

-
Store/Load指令违例: 如上图, 本来在Store下方的Load提前到store之前执行, 如果r5=r9, 将导致违例
-
Load/Store相关性预测: 预测load指令和前面的store指令存在RAW相关性而不能被提前执行
-
硬件处理store/load违例不多见, 通常在比较新的指令集会考虑,例如VLIW处理器领域的intel Itanium:
-
对一条提前到store指令之前的load指令进行标记:
-

-
load.a就是做了标记的指令, 该指令除了load数据外, 还会将load计算出来的地址放到一个表格ALAT(Advanced Load Address Table)中:
-

-
Size表示存储word, halfword 或byte
-
没当store指令计算出来地址,都会据此来查找ALAT, 因此需要Address表项支持内容寻址功能(CAM)
-
如果发现携带地址想他的load指令,会将该load踢出ALAT, 让store指令占据这个位置, 表示发现了load指令违例
-
load指令被提前调度到store之前时, 会在调度后的load加上.a标记, 同时也会在load原来所在的位置加上一条新的指令 load.c
-
load.c指令会检查ALAT,如果发现自己不在ALAT中(被store踢出), 表示发生了违例, 需要进行修复. 修复通常是一段fixup code固定代码
-
顺带提一句,虽然intel Itanium开发了新的指令集,但是失败了…
-
-
-
-
9.6.2 非阻塞Cache
- 在RISC中, 只有像load和store这样的访存指令才可以访问mem
- 对于load指令, 如果发生D-Cache缺失,需要找到一个Cache line放入内存中的数据, 如果Cache line是脏的,还要把line的数据块先写回物理内存
- 对Store指令来说, 如果他的地址不在D-Cache中,那么对于write back+ write allocate类型的Cache来说, 要先从内存中找到地址对应的数据块, 将其取出, 和store的数据进行合并, 再从D-Cache中按照某种算法找到一个Cache line放入.如果被替换的line是脏的, 那在写入之前还要把这个数据协会内存
- 如果在某个访存指令处理D-Cache miss期间, 又有新的访存指令发生了miss, 该如何?
-
一种方法是miss之后, 阻塞其他load store指令, 这种就是阻塞(Blocking)Cache:
-
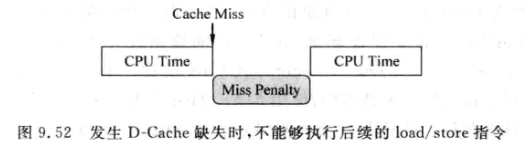
-
性能很低, 因为一般load在数据相关性的顶端
-
非阻塞(Non-blocking)Cache: 也叫lookup-free Cache, 允许D-Cache miss 的时候继续执行新的访存指令:
-
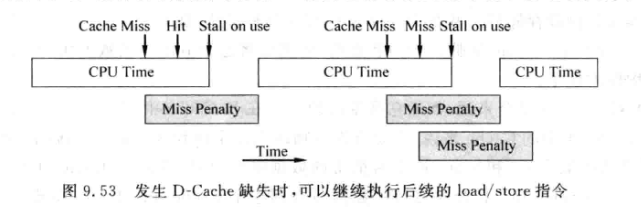
-
需要在scoreboard中将发生D-Cache缺失的load指令的目的寄存器标记为不可获得的状态.
-
带来的问题: load.store指令的Cache miss处理完的时间可能和原始指令顺序不一样. 例如load1需要从内存中导入数据, load2只需要从L2 Cache中导入
-
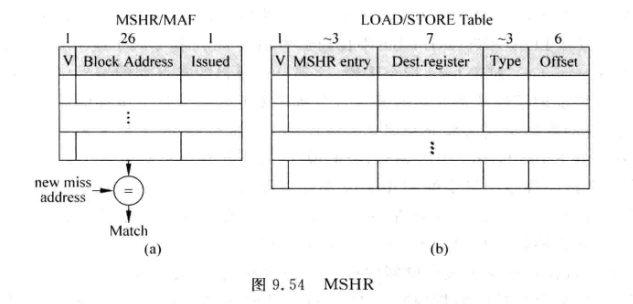
处理器需要将产生D-Cache miss 的load/store指令保存到一个部件中, 该部件就是MSHR(Miss Status/information Holding Register), 也叫做 MAF(Miss Address File):
-
-
先了解几个概念:
- 首次缺失(Primary Miss): 访问D-Cache时第一次产生的缺失
- 再次缺失(Secondary Miss): 发生首次缺失且没有被解决完之前, 后续的访存指令再次访问这个发生缺失的Cache line
-
MSHR中:
- V: Valid位, 表示表项是否被占用, 首次缺失发生时, 会占用一个表项, 当Cache line从下级存储器被取回时, 会释放表项, valid清除
- Block Address: Cache line中数据块的公共地址. 假设Cache line数据块大小是64byte, 则需要6位来索引. 对于一个32位的物理地址, 其余的26位就是数据块的公共地址. 每次load/store发生缺失时都会在MSHR查找所需数据块是否正在被取回
- Issued: 发生首次缺失的访存指令是否开始处理. 因为存储器带宽有限, 所以占用MSHR本体的首次缺失不一定马上被处理, 而是得等到条件满足时才会向下一级存储发出读数据请求.
-
LOAD/STORE Table: 记录首次缺失和再次缺失的访存指令
- V: valid位, 表示是否被占用
- MSHR entry: 表示一条发生缺失的访存指令属于MSHR本体中的哪个表项. 由于产生miss的很多访存指令可能对应同一个Cache line, 他们只占用一个MSHR表项, 但是需要占用LOAD/STORE TABLE中的不同表项. 如此, 当缺失数据块从下级存储取回时, 可以根据block address定位到MSHR中的位置, 并据此在LOAD/STORE TABLE中找到哪些指令属于该cache line
- Dest.register:
- 对load指令来说, 这部分记录目的寄存器(物理)编号, 当数据块取回时, 就可以将对应数据送到这部分记录的寄存器中.
- 对store指令来说, 这部分记录store指令在store buffer 中的编号. 当store指令发生缺失, 它的数据不会立即写到cache ,而是停留在store buffer. 当下级存储器取回数据后, 才将要存储的数据合并到数据块, 再将合并后的数据写到D-Cache, 此时才能从Store Buffer中释放该store占据的空间. 所以LOAD/STORE TABLE中的这个表项一是为了找到store指令携带的数据, 二是释放store占据的store buffer空间.
- Type: 记录访存指令的类型., 例如Load Word, Load Half word等
- Offset: 访存指令所需数据在数据块中的Byte偏移
-
-
MSHR和LOAD/STORE TABLE的配合可以支持非阻塞Cache的操作方式:
- 当访存指令发生Miss时, 查找MSHR, 将发生Miss的地址与MSHR的所有block address进行比较.
- 如果发现想等的表项存在, 表示缺失数据块正在被处理,这次是再次缺失, 此时只需要将这条访存指令写到LOAD/STORE TABLE即可
- 如果没有发现想等表项, 表示此时是首次缺失, 需要将该指令写到MSHR和LOAD/STORE TABLE
-
如果MSHR或LOAD/STORE TABLE任意一个满了, 表示不能在处理新的访存指令, 应该让流水线暂停选择新的访存指令
-
MSHR容量不会很大, 多为4-8个 ^737697
-
非阻塞Cache虽然性能较高,但是会占用较大的面积:
- 以8个表项MSHR和16个表项的LOAD/STORE Table为例:
-
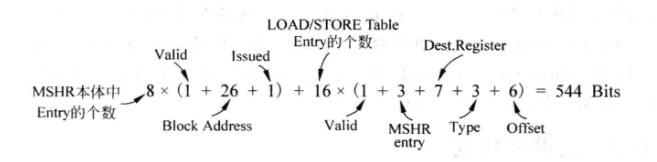
-
为了解决MSHR占用面积大的问题, in-Cache MSHR的方法被提出:
- D-Cache miss时, 从下一级存储器中提取数据, 此时D-Cache中的这一个cache line是空闲的, 没起任何作用.
- 可以将这个cache line作为存储MSHR的地方, 不过需要在cache line中再加一位, 称为transient bit, 表示这个Cache line中的数据正在从下一级存储器中被取回
- 当Cache line处于该模式, 其tag用来存储block address, 其他部分保持MSHR信息
-
in-cache的缺点是:
- Cache的读端口宽度一般远小于Cache line中数据块大小. 例如每周期可以执行4条指令的处理器, D-Cache的读端口一般小于4个, 每个读端口宽度都是32位, 则读带宽最多就4*4=16byte, 远小于Cache line中数据块大小, 导致需要多个周期才能从Cache line中将MSHR的信息读出来
-
- 超标量处理器中, 非阻塞Cache实现会更复杂一些, 由于采用分支预测和乱序执行, 一些引发Cache miss的load/store指令可能处于预测失败的路径上, 因此需要一种机制来选择性地放弃一些正在处理的D-Cache miss:
- 如果一条load在分支预测失败的路径上, 则该指令需要从流水线中抹除, 且还需将LOAD/STORE Table中相应表项删除
- 如果某个发生缺失的数据块正在从下一级取回, 此时发现访问该数据块的所有load/store都处在分支预测失败的路径上, 那么这个数据块不应该被写入D-Cache
9.6.3 关键字优先
-
当发生D-Cache缺失时, 要将该指令所要的整数个数据块从下级存储取出, 如果考虑预取(prefetching), 还要将相邻的下个数据块也取出:
-
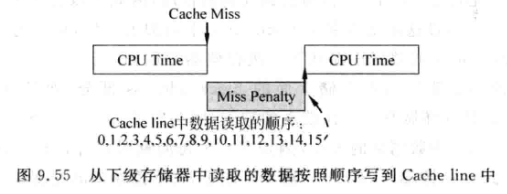
-
如果等到所有数据都写到D-Cache之后才将所需要的数据送给CPU, 这会让CPU等待一段时间. 可以对D-Cache进行改造来加快执行速度:
-
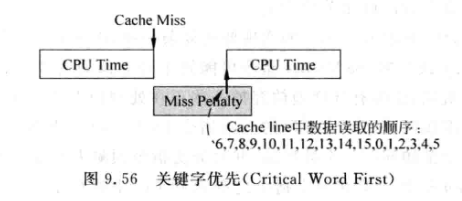
-
关键字优先(Critical Word First): 如果访存指令需要的数据位于数据块中的第6个字, 则此时可使下一级存储器的读取从第6个字开始, 读到数据块结束后,再回过来读前面0-5个字. 这样CPU可以在第6个字读出后就继续执行. 代价是下级存储器需要为支持这样的特性增加硬件逻辑.
9.6.4 提前开始
-
关键字优先需要在下级存储中增加额外的硬件支持, 如果不想付出这些成本, 可以采用 提前开始(Early Restart) 的方法:
-
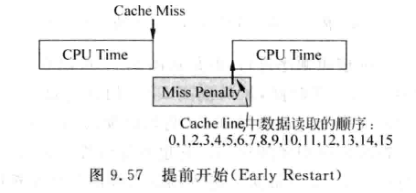
-
提前开始的思路是: 第六个字读出后, CPU开始继续执行
-
与关键字优先的区别是, 这种方法不会改变数据读取的顺序
9.6.5 I-Cache的处理
-
目前位置的非阻塞Cache, 关键字优先, 提前开始三种方法, 都可以应用到D-Cache, 也可以应用到I-Cache
-
由于超标量处理器一般都有分支预测, 会根据当前指令地址对下一条指令的地址进行预测. 如果某次读取I-Cache时发生缺失, 并且预测器预测这条指令正好是分支跳转指令, 则大概率会引发两次miss, 因为预测跳转的分支所用的指令大概率不在I-Cache中:
-
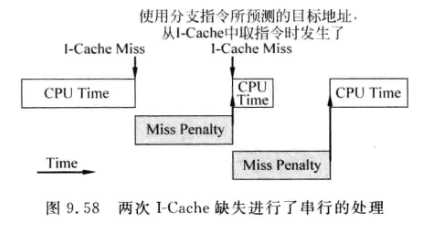
-
因此I-Cache也可使用非阻塞结构:
-
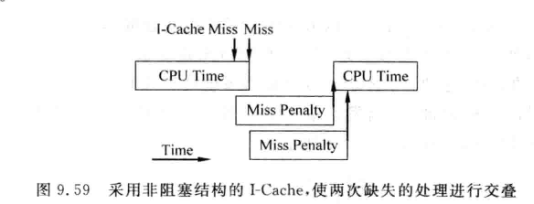
-
I-Cache不需要使用太大的MSHR容量, 有时用1个MSHR表项就够了(MIPS R10000)
-
I-Cache使用这些方法与D-Cache的区别是, I-Cache需要保证指令的原始顺序, 即使后面的指令先被取出, 也要等待前面的指令取出
















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











