






Infinity 已于 2023 年冬至前开源,项目地址:https://github.com/infiniflow/infinity。截至目前已在两周多的时间内从社区收获了不错的反响和 700+ 的 star。来自社区的问题和反馈大多围绕以下几点:
- ”Infinity 也是个向量数据库吧?既然已经有了这么多向量数据库,为何要重新再实现一个?”
- “传统型数据库可以轻松具备向量搜索能力,为什么还要重复造轮子?”
- “Elasticsearch 就有你们所说的多路召回,Infinity 又有什么不同?”
今天,我们就来围绕这些问题谈一谈为什么大模型时代需要一款新的 AI 原生数据库。Infinity 之所以被定义为 AI 原生,主要因为它是为 RAG(Retrieval-Augmented Generation)应用服务的。早几个月前,RAG 这个词还并不流行,当时的说法还是“外挂知识库”,给人一种临时方案的感觉。随着 LLM(Large Language Model)大语言模型自身能力的增强,比如提供更高的 Token 上限等,不少人认为这类方案将被 LLM 强大的能力替代。最近,RAG 这个词又重新火热起来,甚至已经有说法认为 2024 年是 RAG 元年。撇开趋势,我们单从技术的角度来看看随着大模型能力的持续增强,RAG 究竟会长期存在还是仅仅是个临时方案。
我们在之前已经反复讨论了这样的事实:
- 能力再强大的 LLM 也只能取代人的学习和推理能力,无法取代存储和访问数据的能力;参数再多的 LLM 也不能仅凭基于通用数据的训练就能精确表达企业内部海量且丰富的数据。而处理这类数据,才是服务企业或者私有场景的主要需求。
- 无论 LLM 能力发展到何种地步,只要它服务于企业,就必然需要接入企业的各类数据,包括各种文档、日志、数据库;就要面临各种跟这些数据源打通的各类问题:权限、数据清洗、数据入库、跨数据源查询。这些问题都不是 LLM 本身能够解决的。
因此,答案显而易见:RAG 将长期存在。而 RAG 搭载的核心数据库也需要不断升级迭代,以适应 RAG 未来的演进趋势,满足 RAG 长期进化的要求。这正是我们开始研发 Infinity 的主要原因。
RAG 架构
我们认为 RAG 将围绕 AI 原生数据库构建,架构图如下:
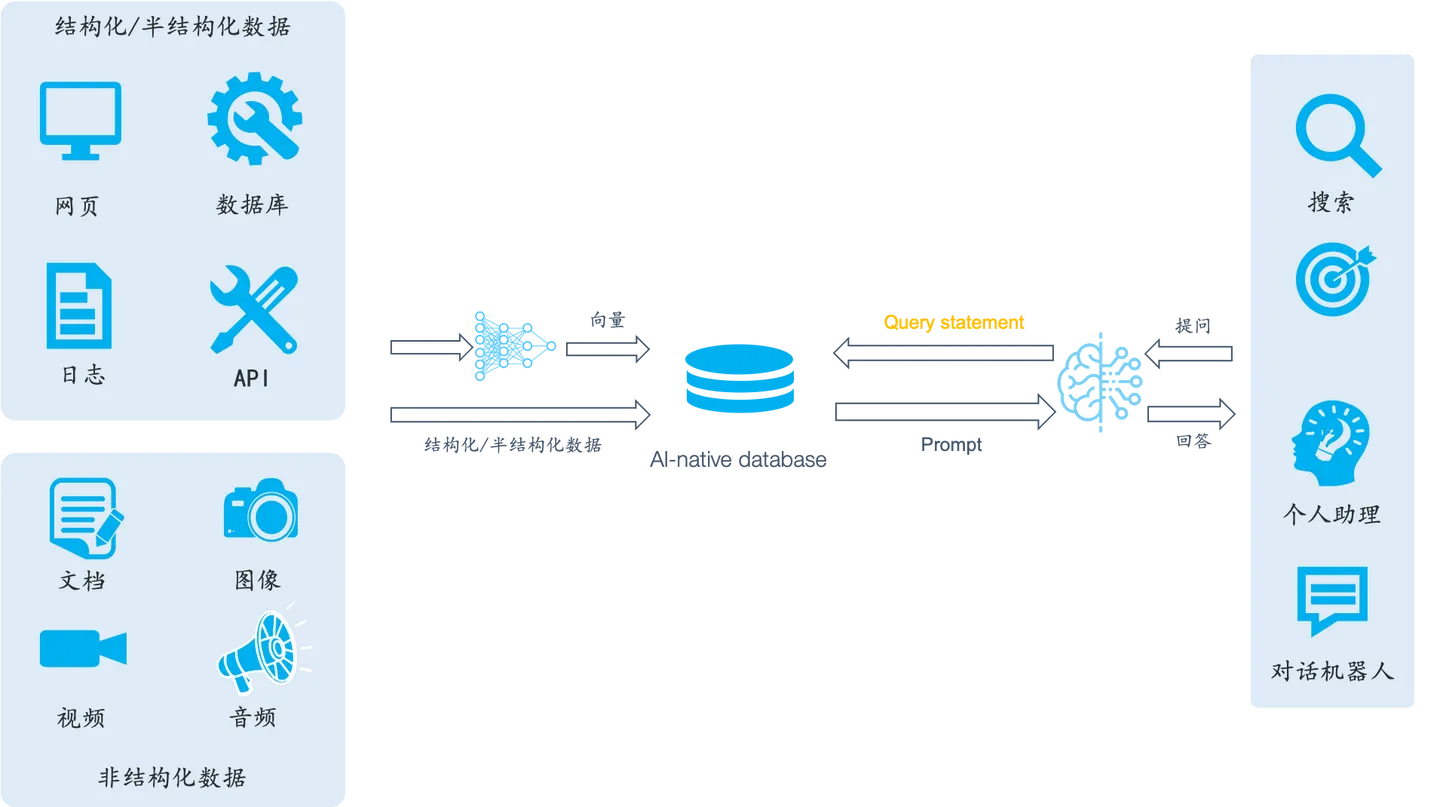
- 适合用向量表达的数据,将会转化为向量。
- 不适合变为向量的数据(如各类结构化和半结构化数据),以原方式保存。
- 查询也不是用一条向量去查出相似的多条向量,而是在一条查询语句中包含多种查询条件:有向量搜索(包含多向量搜索)、全文检索、对各类结构化数据的查询,还有针对多种搜索后的多路召回。
因此,RAG 需要的是一款具备上述能力的数据库,而不是只能搜索向量的数据库。所以这就回到之前第二个问题:在已有数据库上加向量就好了,开发数据库的周期又长,为什么还要再开发一款新的数据库?
RAG 核心需求
RAG 这个词火热之后,出现了很多介绍如何提升 RAG 性能的文章。如何能够更好地回答问题,恐怕是当前每个在做 RAG 项目最关心的问题。这其中大多数提到的技巧是以开源向量库或自带向量能力的数据库,搭配 Langchain 中间件以及类似 LLMOps 的工具,来搭建一套简易的 RAG 系统。虽然在大多数场景下,这些“简易搭建”还只能作为玩具或者简单的原型演示,我们还是能看到所有的这些技巧都围绕着解决 RAG 的三大核心需求:
- 用更好的 embedding 模型获取更好的向量:在把文字送进数据库之前,需要对文字做足够好的预加工,文字分片切也需要做得足够好,才能确保获得的向量是恰当的。
- 多路召回!多路召回!多路召回!重要的事情说三遍:没有多路召回的 RAG 没有未来!
- 排序(cross-attentional re-ranking)。所谓“跨注意力”指的是多路召回:多路召回的结果还需要经过良好的重排序(fused ranking)才能把最适当的结果交给 LLM。
RAG 需要的多路召回与排序还未被很好地解决
RAG 的三大核心需求中除了第一点的向量转化是在数据库以外完成,其余两点都可以在数据库内部完成。那为什么不用具备向量能力的数据库?这是因为这两点始终很难做好。搜索引擎从开始至今已有二十多年,不论是面向 C 端的互联网搜索、垂直搜索,还是面向 B 端的企业搜索领域,没有一家公司用数据库来做搜索引擎,就是因为这两点解决不好。RAG 做得好的公司必须具备良好的搜索引擎基因,因为 RAG 正是搜索引擎的进化。我们来看几个例子:
- Vespa:开源多年的搜索引擎。Vespa 的历史可以追溯到上世纪九十年代。Yahoo 于 2003 年收购的搜索引擎 Overture 就是 Vespa 的前身。2023 年 10 月,Vespa 从 Yahoo 独立出来并获得 Blossom 的 3100 万美元融资。它的重要融资项目就是一个基于互联网数据向 C 端用户提供高质量问答服务的大型 RAG。
- 百川:百川近期开放了基于 RAG 的 Turbo API 。其中后台就采用了增强 RAG 效果的技术。包括查询扩展、多路召回、排序在内,无一不是搜索引擎强大技术能力的体现。而百川的前身搜狗就是一个互联网搜索引擎,搜索引擎转型提供 RAG 可以说是水到渠成。
- perplexity.ai:面向 C 端最成功的 RAG 应用。本质也是搜索引擎的进化,只是比搜索引擎多做了以下几件事:
- 用 LLM 重新理解用户的提问,并解析为更清晰的搜索语句。
- 调用搜索引擎,比如 Google、Bing 的 API,创建了自己的索引库,来构建特定领域的索引库,保证搜索质量。
- 采用自研排序算法对所有的搜索结果重排序,筛选出数量不等、质量不错的网页。
- 用 LLM 来阅读排序返回网页中的内容,并输出与问题相关的答案。
总的来说,传统的数据库无法服务好 RAG ,是因为缺乏以下这些搜索引擎必备的组件:
- 高效率的全文索引
- 多样化的排序手段
- 无处不在的自然语言处理
而以上这些正是 Infinity 从一开始就着眼解决的问题。不同于以上这些大型 RAG 所面对的场景,Infinity 面向的是企业内部场景。正如互联网搜索/垂直搜索进化成为上面这些产品形态,企业搜索必然会进化成为企业 RAG 的形态——这不是传统数据库+向量搜索能够解决的 。
Infinity vs. Elasticsearch
最后一个问题:企业搜索大多采用 Elasticsearch,它也具备向量和多路召回的能力,Infinity 和它有什么区别?
我们先来回答这样一个问题:上面这些 RAG 应用可以用 Elasticsearch 吗? 这和十年前的“可以用 Elasticsearch 做垂直搜索创业吗”这样的问题几乎是类似的。答案当然是可以的,但是只能做雏形。搜索引擎时代的名言 Relevance Is Revenue 在 RAG 时代仍然适用。各种查询扩展和排序都需要根据业务定制,单纯依靠 Elasticsearch 是不够的。由于排序基本是围绕着 TF/IDF 这些规则进行的,过去的企业搜索在文档排序方面可以做的工作并不多:没有网页的 PageRank 等作为企业内部文档排序的权重,也没有用户反馈来不断改进搜索排序结果。而现在的 RAG 已经可以依赖各种 Embedding 模型提供 TF/IDF 以外的召回和排序,因此面向企业用户的 RAG 和面向互联网用户的 RAG 在需求关系上变得更加接近,两者的差异也不再像过去企业搜索和互联网搜索的差异那么大。一个良好的 RAG 需要一个数据库为核心,还要辅助以各类周边工具,尤其是融合排序模型,特别是针对垂直业务或者不同企业内部的各种排序模型,才能达到满意的效果。Infinity 从设计一开始就把 DB4AI 放在最高目标:随着数据库内核能力的逐步完善,围绕 RAG 的系列周边 AI 能力都会同步跟进。
其次,Infinity 从一开始就是按照一套完整的数据库架构来开发和设计的,着眼于三方面的能力:向量查询,全文搜索,结构化数据查询以及它们的融合排序。而 Elasticsearch 在十多年前就是企业搜索引擎。两者在技术层面的一个显著差异就是 Infinity 是有执行引擎的:一条查询请求进来之后会被编译成计算图,查询请求以流水线的方式在计算图流转,引擎会根据可用资源的数量决定计算图每个节点使用的并行度。而 Elasticsearch 这样的搜索引擎是没有执行引擎组件的:收到搜索请求以后,直接从倒排索引获取数据后排序返回,所有工作都在一个线程中完成。缺乏执行引擎在应用层面的表现就是无法为企业内的各类精确信息查找提供足够的访问能力。一个常见的企业搜索场景是权限访问,需要涉及到访问权限表、业务表、维度表,最后才是多路召回。 如果没有对结构化数据的多样化访问能力,哪怕是最简单的知识库也需要再搭载一个权限数据库进行联邦查询(federated query),甚至需要通过 ETL(Extract Transform Load) 制作成宽表才能完成最终业务的封装。 而对于一个提供高并发能力的在线服务场景,动辄引入宽表几乎是不可能完成的任务。 因此,Infinity 不是搜索引擎,而是一个完整的数据库。这不是面向 C 端用户的 RAG 所需要的,但却是企业级 RAG 必不可少的需求。
再其次,我们不愿过分强调但却绕不过去的就是性能。作为一款采用 C++ 20 标准开发的数据库,Infinity 从一开始就把性能放在重要层面考虑,它没有 GC(Garbage-collection)开发语言开发 Infra 组件带来的各种抖动和内存问题。Infinity 目前的开源版本在向量搜索部分的性能上已经超过了所有已知开源产品。
最后,2024 年 Infinity 将推出云原生架构,这也将显著区别于 Elasticsearch。
以上就是我们对于为什么要重新开发一款数据库的回答,感兴趣的读者,欢迎 Star、关注我们的项目:
https://github.com/infiniflow/infinity/

















 4151
4151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









