






前言:
博主在自主学习粒子滤波的过程中,看了很多文献或博客,不知道是看文献时粗心大意还是悟性太低,看着那么多公式,总是无法把握住粒子滤波的思路,也无法将理论和实践对应起来。比如:理论推导过程中那么多概率公式,概率怎么和系统的状态变量对应上了?状态粒子是怎么一步步采样出来的,为什么程序里面都是直接用状态方程来计算?粒子的权重是怎么来的?经过一段时间的理解,总算理清了它的脉络。同时也觉得,只有对理论的推导心中有数了,才能知道什么样的地方可以用这个算法,以及这个算法有什么不足。因此,本文将结合实际程序给出粒子滤波的详细推导,在推导过程中加入博主自己的理解,如有不妥,请指出,谢谢。
文章架构:
由最基础的贝叶斯估计开始介绍,再引出蒙特卡罗采样,重要性采样,SIS粒子滤波,重采样,基本粒子滤波Generic Particle Filter,SIR粒子滤波,这些概念的引进,都是为了解决上一个概念中出现的问题而环环相扣的。最后给出几个在matlab和python中的应用,例程包括图像跟踪,滤波,机器人定位。
再往下看之前,也可以看看《卡尔曼滤波:从推导到应用》,好对这种通过状态方程来滤波的思路有所了解。
一、贝叶斯滤波
假设有一个系统,我们知道它的状态方程,和测量方程如下:
如:
(1)
如:
(2)
其中x为系统状态,y为测量到的数据,f,h是状态转移函数和测量函数,v,n为过程噪声和测量噪声,噪声都是独立同分布的。上面对应的那个例子将会出现在程序中。
从贝叶斯理论的观点来看,状态估计问题(目标跟踪、信号滤波)就是根据之前一系列的已有数据(后验知识)递推的计算出当前状态
的可信度。这个可信度就是概率公式
,它需要通过预测和更新两个步奏来递推的计算。
预测过程是利用系统模型(状态方程1)预测状态的先验概率密度,也就是通过已有的先验知识对未来的状态进行猜测,即p( x(k)|x(k-1) )。更新过程则利用最新的测量值对先验概率密度进行修正,得到后验概率密度,也就是对之前的猜测进行修正。
在处理这些问题时,一般都先假设系统的状态转移服从一阶马尔科夫模型,即当前时刻的状态x(k)只与上一个时刻的状态x(k-1)有关。这是很自然的一种假设,就像小时候玩飞行棋,下一时刻的飞机跳到的位置只由当前时刻的位置和骰子决定。同时,假设k时刻测量到的数据y(k)只与当前的状态x(k)有关,如上面的状态方程2。
为了进行递推,不妨假设已知k-1时刻的概率密度函数
预测:由上一时刻的概率密度得到
,这个公式的含义是既然有了前面1:k-1时刻的测量数据,那就可以预测一下状态x(k)出现的概率。
计算推导如下:
等式的第一行到第二行纯粹是贝叶斯公式的应用。第二行得到第三行是由于一阶马尔科夫过程的假设,状态x(k)只由x(k-1)决定。
楼主看到这里的时候想到两个问题:
第一:既然 ,x(k)都只由x(k-1)决定了,即
,在这里弄一个
是什么意思?
这两个概率公式含义是不一样的,前一个是纯粹根据模型进行预测,x(k)实实在在的由x(k-1)决定,后一个是既然测到的数据和状态是有关系的,现在已经有了很多测量数据 y 了,那么我可以根据已有的经验对你进行预测,只是猜测x(k),而不能决定x(k)。
第二:上面公式的最后一行是假设已知的,但是
怎么得到呢?
其实它由系统状态方程决定,它的概率分布形状和系统的过程噪声
形状一模一样。如何理解呢?观察状态方程(1)式我们知道,x(k) = Constant( x(k-1) ) + v(k-1) 也就是x(k)由一个通过x(k-1)计算出的常数叠加一个噪声得到。看下面的图:
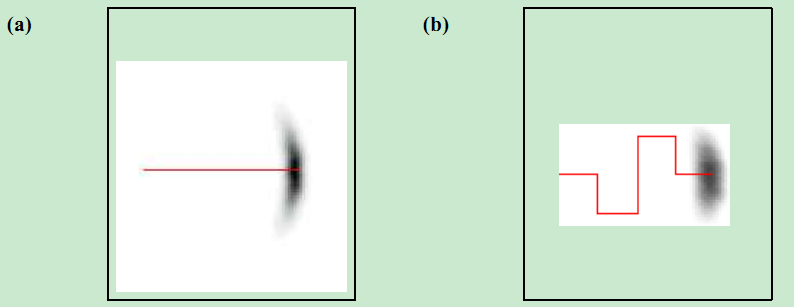
如果没有噪声,x(k)完全由x(k-1)计算得到,也就没由概率分布这个概念了,由于出现了噪声,所以x(k)不好确定,他的分布就如同图中的阴影部分,实际上形状和噪声是一样的,只是进行了一些平移。理解了这一点,对粒子滤波程序中,状态x(k)的采样的计算很有帮助,要采样x(k),直接采样一个过程噪声,再叠加上 f(x(k-1)) 这个常数就行了。
更新:由得到后验概率
。这个后验概率才是真正有用的东西,上一步还只是预测,这里又多了k时刻的测量,对上面的预测再进行修正,就是滤波了。这里的后验概率也将是代入到下次的预测,形成递推。
推导:
其中归一化常数:
等式第一行到第二行是因为测量方程知道, y(k)只与x(k)有关,也称之为似然函数,由量测方程决定。也和上面的推理一样,
, x(k)部分是常数,
也是只和量测噪声n(k)的概率分布有关,注意这个也将为SIR粒子滤波里权重的采样提供编程依据。
贝叶斯滤波到这里就告一段落了。但是,请注意上面的推导过程中需要用到积分,这对于一般的非线性,非高斯系统,很难得到后验概率的解析解。为了解决这个问题,就得引进蒙特卡洛采样。关于它的具体推导请见 下一篇博文。
(转载请注明作者和出处:http://blog.csdn.net/heyijia0327 未经允许请勿用于商业用途)
reference:
1.M. Sanjeev Arulampalam 《A Tutorial on Particle Filters for Online Nonlinear/Non-Gaussian Bayesian Tracking》
2.ZHE CHEN 《Bayesian Filtering: From Kalman Filters to Particle Filters, and Beyond》
3.Sebastian THRUN 《Probabilistic Robotics》
3.百度文库 《粒子滤波理论》
二、蒙特卡洛采样
假设我们能从一个目标概率分布p(x)中采样到一系列的样本(粒子),(至于怎么生成服从p(x)分布的样本,这个问题先放一放),那么就能利用这些样本去估计这个分布的某些函数的期望值。譬如:
上面的式子其实都是计算期望的问题,只是被积分的函数不同。
蒙特卡洛采样的思想就是用平均值来代替积分,求期望:
这可以从大数定理的角度去理解它。我们用这种思想去指定不同的f(x)以便达到估计不同东西的目的。比如:要估计一批同龄人的体重,不分男女,在大样本中男的有100个,女的有20个,为了少做事,我们按比例抽取10个男的,2个女的,测算这12个人的体重求平均就完事了。注意这里的按比例抽取,就可以看成从概率分布p(x)中进行抽样。
下面再看一个稍微学术一点的例子:
假设有一粒质地均匀的骰子。规定在一次游戏中,连续四次抛掷骰子,至少出现一次6个点朝上就算赢。现在来估计赢的概率。我们用来表示在第n次游戏中,第k次投掷的结果,k=1...4。对于分布均匀的骰子,每次投掷服从均匀分布,即:
这里的区间是取整数,1,2,3,4,5,6,代表6个面。由于每次投掷都是独立同分布的,所以这里的目标分布p(x)也是一个均匀分布。一次游戏就是
空间中的一个随机点。
为了估计取胜的概率,在第n次游戏中定义一个指示函数:
其中,指示函数I{x }是指,若x的条件满足,则结果为1,不满足结果为0。回到这个问题,这里函数 f()的意义就是单次游戏中,若四次投掷中只要有一个6朝上,f()的结果就会是1。由此,就可以估计在这样的游戏中取胜的期望,也就是取胜的概率:
当抽样次数N足够大的时候,上式就逼近真实取胜概率了,看上面这种估计概率的方法,是通过蒙特卡洛方法的角度去求期望达到估计概率的目的。是不是就跟我们抛硬币的例子一样,抛的次数足够多就可以用来估计正面朝上或反面朝上的概率了。
当然可能有人会问,这样估计的误差有多大,对于这个问题,有兴趣的请去查看我最下面列出的参考文献2。(啰嗦一句:管的太多太宽,很容易让我们忽略主要问题。博主就是在看文献过程中,这个是啥那个是啥,都去查资料,到头来粒子滤波是干嘛完全不知道了,又重新看资料。个人感觉有问题还是先放一放,主要思路理顺了再关注细节。)
接下来,回到我们的主线上,在滤波中蒙特卡洛又是怎么用的呢?
由上面我们知道,它可以用来估计概率,而在上一节中,贝叶斯后验概率的计算里要用到积分,为了解决这个积分难的问题,可以用蒙特卡洛采样来代替计算后验概率。
假设可以从后验概率中采样到N个样本,那么后验概率的计算可表示为:
其中,在这个蒙特卡洛方法中,我们定义,是狄拉克函数(dirac delta function),跟上面的指示函数意思差不多。
看到这里,既然用蒙特卡洛方法能够用来直接估计后验概率,现在估计出了后验概率,那到底怎么用来做图像跟踪或者滤波呢?要做图像跟踪或者滤波,其实就是想知道当前状态的期望值:
(1)
也就是用这些采样的粒子的状态值直接平均就得到了期望值,也就是滤波后的值,这里的 f(x) 就是每个粒子的状态函数。这就是粒子滤波了,只要从后验概率中采样很多粒子,用它们的状态求平均就得到了滤波结果。
思路看似简单,但是要命的是,后验概率不知道啊,怎么从后验概率分布中采样!所以这样直接去应用是行不通的,这时候得引入重要性采样这个方法来解决这个问题。
三、重要性采样
无法从目标分布中采样,就从一个已知的可以采样的分布里去采样如 q(x|y),这样上面的求期望问题就变成了:
(2)式
其中
由于:
所以(2)式可以进一步写成:
(3)式
上面的期望计算都可以通过蒙特卡洛方法来解决它,也就是说,通过采样N个样本,用样本的平均来求它们的期望,所以上面的(3)式可以近似为:
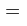
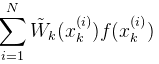
其中:
这就是归一化以后的权重,而之前在(2)式中的那个权重是没有归一化的。
注意上面的(4)式,它不再是(1)式中所有的粒子状态直接相加求平均了,而是一种加权和的形式。不同的粒子都有它们相应的权重,如果粒子权重大,说明信任该粒子比较多。
到这里已经解决了不能从后验概率直接采样的问题,但是上面这种每个粒子的权重都直接计算的方法,效率低,因为每增加一个采样,p( x(k) |y(1:k))都得重新计算,并且还不好计算这个式子。所以求权重时能否避开计算p(x(k)|y(1:k))?而最佳的形式是能够以递推的方式去计算权重,这就是所谓的序贯重要性采样(SIS),粒子滤波的原型。
下面开始权重w递推形式的推导:
假设重要性概率密度函数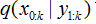
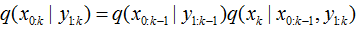
后验概率密度函数的递归形式可以表示为:
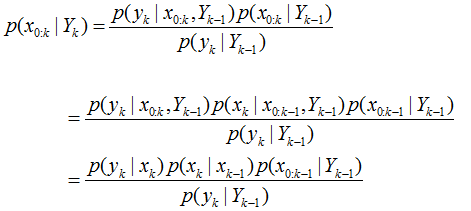
其中,为了表示方便,将 y(1:k) 用 Y(k) 来表示,注意 Y 与 y 的区别。同时,上面这个式子和上一节贝叶斯滤波中后验概率的推导是一样的,只是之前的x(k)变成了这里的x(0:k),就是这个不同,导致贝叶斯估计里需要积分,而这里后验概率的分解形式却不用积分。
粒子权值的递归形式可以表示为:
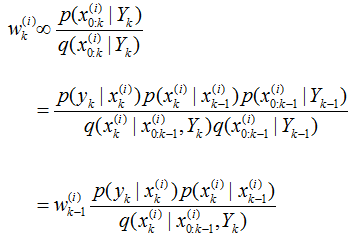 ( 5)式
( 5)式
注意,这种权重递推形式的推导是在前面(2)式的形式下进行推导的,也就是没有归一化。而在进行状态估计的公式为
四、Sequential Importance Sampling (SIS) Filter
在实际应用中我们可以假设重要性分布q()满足:
这个假设说明重要性分布只和前一时刻的状态x(k-1)以及测量y(k)有关了,那么(5)式就可以转化为:
在做了这么多假设和为了解决一个个问题以后,终于有了一个像样的粒子滤波算法了,他就是序贯重要性采样滤波。
下面用伪代码的形式给出这个算法:
----------------------pseudo code-----------------------------------
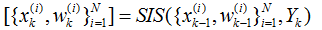
For i=1:N
(1)采样:;
(2)根据递推计算各个粒子的权重;
End For
粒子权值归一化。粒子有了,粒子的权重有了,就可以由(4)式,对每个粒子的状态进行加权去估计目标的状态了。
-----------------------end -----------------------------------------------
这个算法就是粒子滤波的前身了。只是在实际应用中,又发现了很多问题,如粒子权重退化的问题,因此就有了重采样( resample ),就有了基本的粒子滤波算法。还有就是重要性概率密度q()的选择问题,等等。都留到下一章 去解决。
在这一章中,我们是用的重要性采样这种方法去解决的后验概率无法采样的问题。实际上,关于如何从后验概率采样,也就是如何生成特定概率密度的样本,有很多经典的方法(如拒绝采样,Markov Chain Monte Carlo,Metropolis-Hastings 算法,Gibbs采样),这里面可以单独作为一个课题去学习了,有兴趣的可以去看看《统计之都 的一篇博文》,强烈推荐,参考文献里的前几个也都不错。
(转载请注明作者和出处:http://blog.csdn.net/heyijia0327 未经允许请勿用于商业用途)
reference:
1. Gabriel A. Terejanu 《Tutorial on Monte Carlo Techniques》
2. Taylan Cemgil 《A Tutorial Introduction to Monte Carlo methods, Markov Chain Monte Carlo and Particle Filtering》
3. M. Sanjeev Arulampalam 《A Tutorial on Particle Filters for Online Nonlinear/Non-Gaussian Bayesian Tracking》
4. ZHE CHEN 《Bayesian Filtering: From Kalman Filters to Particle Filters, and Beyond》
5.百度文库《粒子滤波理论》
6. Haykin 《Neural Networks and learning Machines 》Chapter 14
7. 统计之都 <LDA-math-MCMC 和 Gibbs Sampling>
===========================================MATLAB实现====================================================
粒子滤波是以贝叶斯推理和重要性采样为基本框架的。因此,想要掌握粒子滤波,对于上述两个基本内容必须有一个初步的了解。贝叶斯公式非常perfect,但是在实际问题中,由于变量维数很高,被积函数很难积分,常常会给粒子滤波带来很大的麻烦。为了克服这个问题,它引入了重要性采样。即先设计一个重要性密度,根据重要性密度与实际分布之间的关系,给采样得到的粒子分配权重。再利用时变贝叶斯公式,给出粒子权重的更新公式及重要性密度的演变形式。在实际问题中,由于直接从重要性密度中采样非常困难,因此做出了妥协,重要性密度选为状态转移分布,随之可得权值更新遵循的规律与量测方程有关。
粒子滤波算法源于Monte carlo思想,即以某事件出现的频率来指代该事件的概率。因此在滤波过程中,需要用到概率如P(x)的地方,一概对变量x采样,以大量采样及其相应的权值来近似表示P(x)。因此,采用此思想,在滤波过程中粒子滤波可以处理任意形式的概率,而不像Kalman滤波只能处理线性高斯分布的概率问题。粒子滤波的一大优势也在于此。
下来看看对任意如下的状态方程:
x(t)=f(x(t-1),u(t),w(t))
y(t)=h(x(t),e(t))
其中的x(t)为t时刻状态,u(t)为控制量,w(t) 和e(t)分别为状态噪声和观测噪声。前一个方程描述是状态转移,后一个是观测方程。对于这么一个问题粒子滤波怎么来从观测y(t),和x(t-1),u(t) 滤出真实状态x(t)呢?
预测阶段:粒子滤波首先根据x(t-1) 的概率分布生成大量的采样,这些采样就称之为粒子。那么这些采样在状态空间中的分布实际上就是x(t-1) 的概率分布了。好,接下来依据状态转移方程加上控制量可以对每一粒子得到一个预测粒子。
校正阶段:观测值y到达后,利用观测方程即条件概率P(y|xi ),对所有的粒子进行评价,直白的说,这个条件概率代表了假设真实状态x(t)取第i个粒子xi时获得观测y的概率。令这个条件概率为第i个粒子的权重。如此这般下来,对所有粒子都进行这么一个评价,那么越有可能获得观测y的粒子,当然获得的权重越高。
重采样算法:去除低权值的粒子,复制高权值的粒子。所得到的当然就是我们说需要的真实状态x(t)了,而这些重采样后的粒子,就代表了真实状态的概率分布了。下一轮滤波,再将重采样过后的粒子集输入到状态转移方程中,直接就能够获得预测粒子了。
初始状态的问题: 由于开始对x(0)一无所知,所有我们可以认为x(0)在全状态空间内平均分布。于是初始的采样就平均分布在整个状态空间中。然后将所有采样输入状态转移方程,得到预测粒子。然后再评价下所有预测粒子的权重,当然我们在整个状态空间中只有部分粒子能够获的高权值。最后进行重采样,去除低权值的,将下一轮滤波的考虑重点缩小到了高权值粒子附近。
具体过程:
1)初始化阶段-提取跟踪目标特征
该阶段要人工指定跟踪目标,程序计算跟踪目标的特征,比如可以采用目标的颜色特征。具体到Rob Hess的代码,开始时需要人工用鼠标拖动出一个跟踪区域,然后程序自动计算该区域色调(Hue)空间的直方图,即为目标的特征。直方图可以用一个向量来表示,所以目标特征就是一个N*1的向量V。
2)搜索阶段-放狗
好,我们已经掌握了目标的特征,下面放出很多条狗,去搜索目标对象,这里的狗就是粒子particle。狗有很多种放法。比如,a)均匀的放:即在整个图像平面均匀的撒粒子(uniform distribution);b)在上一帧得到的目标附近按照高斯分布来放,可以理解成,靠近目标的地方多放,远离目标的地方少放。Rob Hess的代码用的是后一种方法。狗放出去后,每条狗怎么搜索目标呢?就是按照初始化阶段得到的目标特征(色调直方图,向量V)。每条狗计算它所处的位置处图像的颜色特征,得到一个色调直方图,向量Vi,计算该直方图与目标直方图的相似性。相似性有多种度量,最简单的一种是计算sum(abs(Vi-V)).每条狗算出相似度后再做一次归一化,使得所有的狗得到的相似度加起来等于1.
3)决策阶段
我们放出去的一条条聪明的狗向我们发回报告,“一号狗处图像与目标的相似度是0.3”,“二号狗处图像与目标的相似度是0.02”,“三号狗处图像与目标的相似度是0.0003”,“N号狗处图像与目标的相似度是0.013”...那么目标究竟最可能在哪里呢?我们做次加权平均吧。设N号狗的图像像素坐标是(Xn,Yn),它报告的相似度是Wn,于是目标最可能的像素坐标X = sum(Xn*Wn),Y = sum(Yn*Wn).
4)重采样阶段Resampling
既然我们是在做目标跟踪,一般说来,目标是跑来跑去乱动的。在新的一帧图像里,目标可能在哪里呢?还是让我们放狗搜索吧。但现在应该怎样放狗呢?让我们重温下狗狗们的报告吧。“一号狗处图像与目标的相似度是0.3”,“二号狗处图像与目标的相似度是0.02”,“三号狗处图像与目标的相似度是0.0003”,“N号狗处图像与目标的相似度是0.013”...综合所有狗的报告,一号狗处的相似度最高,三号狗处的相似度最低,于是我们要重新分布警力,正所谓好钢用在刀刃上,我们在相似度最高的狗那里放更多条狗,在相似度最低的狗那里少放狗,甚至把原来那条狗也撤回来。这就是Sampling Importance Resampling,根据重要性重采样(更具重要性重新放狗)。
(2)->(3)->(4)->(2)如是反复循环,即完成了目标的动态跟踪。
粒子滤波简单实现
clc;
clear all;
close all;
x = 0; %初始值
R = 1;
Q = 1;
tf = 100; %跟踪时长
N = 100; %粒子个数
P = 2;
xhatPart = x;
for i = 1 : N
xpart(i) = x + sqrt(P) * randn;%初始状态服从0均值,方差为sqrt(P)的高斯分布
end
xArr = [x];
yArr = [x^2 / 20 + sqrt(R) * randn];
xhatArr = [x];
PArr = [P];
xhatPartArr = [xhatPart];
for k = 1 : tf
x = 0.5 * x + 25 * x / (1 + x^2) + 8 * cos(1.2*(k-1)) + sqrt(Q) * randn;
%k时刻真实值
y = x^2 / 20 + sqrt(R) * randn; %k时刻观测值
for i = 1 : N
xpartminus(i) = 0.5 * xpart(i) + 25 * xpart(i) / (1 + xpart(i)^2) ...
+ 8 * cos(1.2*(k-1)) + sqrt(Q) * randn;%采样获得N个粒子
ypart = xpartminus(i)^2 / 20;%每个粒子对应观测值
vhat = y - ypart;%与真实观测之间的似然
q(i) = (1 / sqrt(R) / sqrt(2*pi)) * exp(-vhat^2 / 2 / R);
%每个粒子的似然即相似度
end
qsum = sum(q);
for i = 1 : N
q(i) = q(i) / qsum;%权值归一化
end
for i = 1 : N %根据权值重新采样
u = rand;
qtempsum = 0;
for j = 1 : N
qtempsum = qtempsum + q(j);
if qtempsum >= u
xpart(i) = xpartminus(j);
break;
end
end
end
xhatPart = mean(xpart);
%最后的状态估计值即为N个粒子的平均值,这里经过重新采样后各个粒子的权值相同
xArr = [xArr x];
yArr = [yArr y];
% xhatArr = [xhatArr xhat];
PArr = [PArr P];
xhatPartArr = [xhatPartArr xhatPart];
end
t = 0 : tf;
figure;
plot(t, xArr, 'b-.', t, xhatPartArr, 'k-');
legend('Real Value','Estimated Value');
set(gca,'FontSize',10);
xlabel('time step');
ylabel('state');
title('Particle filter')
xhatRMS = sqrt((norm(xArr - xhatArr))^2 / tf);
xhatPartRMS = sqrt((norm(xArr - xhatPartArr))^2 / tf);
figure;
plot(t,abs(xArr-xhatPartArr),'b');
title('The error of PF')

















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









