






前言
本篇介绍KV Cache。
KV Cache(键-值缓存)是一种在大模型推理中广泛应用的优化技术,其核心思想是利用缓存 key 和 value 来避免重复计算,从而提高推理效率。代价是显存占用会增加。
核心思想
在自注意力层的计算中,对于给定的输入序列,模型会计算每个token的key和value向量。这些向量的值在序列生成过程中是不变的。因此,通过缓存这些向量,可以避免在每次生成新token时重复计算,只需计算新token的query向量,并使用缓存的key/value向量进行自注意力计算 。
具体来说,decoder一次推理只输出一个token,输出token会与输入tokens 拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终止符。
在上面的推理过程中,每 step 内,输入一个 token序列,经过Embedding层将输入token序列变为一个三维张量[b, s, h],经过一通计算,最后经logits层将计算结果映射至词表空间,输出张量维度为[b, s, vocab_size]。
当前轮输出token与输入tokens拼接,并作为下一轮的输入tokens,反复多次。可以看出第𝑖+1 轮输入数据只比第𝑖轮输入数据新增了一个token,其他全部相同!因此第𝑖+1轮推理时必然包含了第 𝑖 轮的部分计算。KV Cache的出发点就在这里,缓存当前轮可重复利用的计算结果,下一轮计算时直接读取缓存结果。
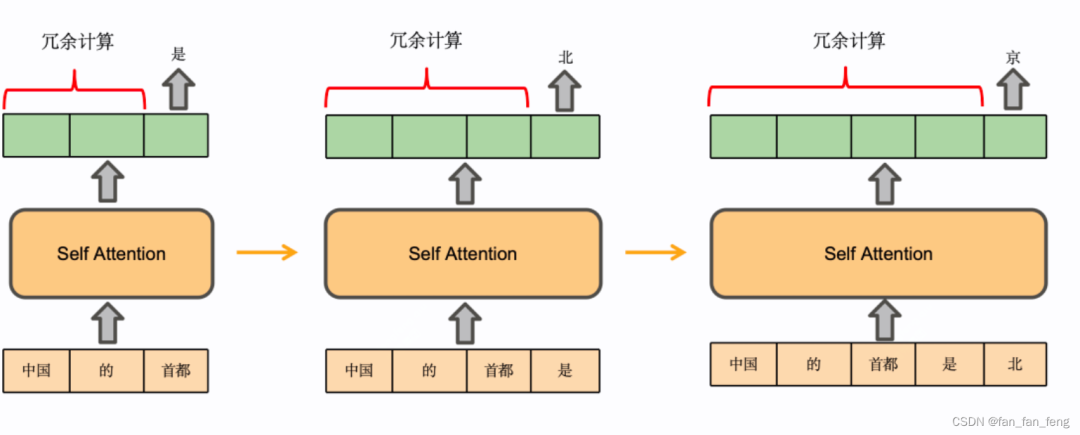
两阶段推理
推理过程的两个阶段:
-
第一阶段:在第一次迭代时,KV Cache为空,需要为所有输入的token计算key、value和query向量,并将key和value缓存起来。
-
第二阶段:在后续迭代中,只需要为新的token计算key、value和query,然后更新KV Cache
class Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: BaiChuanConfig):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.max_position_embeddings = config.max_position_embeddings
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {self.num_heads})."
)
# self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
# self.k_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
# self.v_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
self.W_pack = nn.Linear(self.hidden_size, 3 * self.hidden_size, bias=False)
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
self.rotary_emb = RotaryEmbedding(self.head_dim, max_position_embeddings=self.max_position_embeddings)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size() # 开启kv cache 解码阶段 q_len 为 1
proj = self.W_pack(hidden_states)
proj = proj.unflatten(-1, (3, self.hidden_size)).unsqueeze(0).transpose(0, -2).squeeze(-2)
query_states = proj[0].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1,
2) # batch_size x source_len x hidden_size
key_states = proj[1].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1,
2) # batch_size x target_len x head_size
value_states = proj[2].view(bsz, q_len, self.num_heads, self.head_dim).transpose(1,
2) # batch_size x source_len x hidden_size
# query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
# key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
# value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
kv_seq_len = key_states.shape[-2]
if past_key_value is not None:
kv_seq_len += past_key_value[0].shape[-2] # 更新 kv_seq_len
print("kv_seq_len += past_key_value[0].shape[-2]")
print(kv_seq_len)
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
# [bsz, nh, t, hd]
if past_key_value is not None: # 合并
# reuse k, v, self_attention
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
past_key_value = (key_states, value_states) if use_cache else None
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
raise ValueError(
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
f" {attn_weights.size()}"
)
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights + attention_mask
attn_weights = torch.max(attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min))
# upcast attention to fp32
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
显存占用
使用KV Cache的代价是显存占用会增加,因为它需要存储历史全量的KV信息。显存占用的计算公式为:2 * hidden_size * num_layers * decoder_length,而未使用KV Cache时的显存占用为:2 * hidden_size * 1 * decoder_length
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2907
2907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









