







时间:2022
paper:https://arxiv.org/pdf/2207.09666v1.pdf
code:https://github.com/davidnvq/grit
作者创新点
思考依据:
之前的很多图像描述方法都是通过fast-rcnn(作为物体探测器)来提取区域特征,这样的方法存在三个问题:①缺乏上下文信息 ②局部识别不准确 ③计算成本高
作者通过添加基于网格的特征提取以及采用Deformable DETR目标检测的区域特征提取方法解决上述前两个问题
!!!那怎么提取和融合局部物体特征和网格特征呢?
作者提出了一种仅基于transformer的神经网络架构,能够很好的利用这两个特征来生成描述:
- 用基于 DETR 的方法代替之前模型中基于cnn(比如fast-rcnn)的方法
- 该模型仅基于transformer并且是端到端训练的,相比于之前的方法取得了一个很好的提高
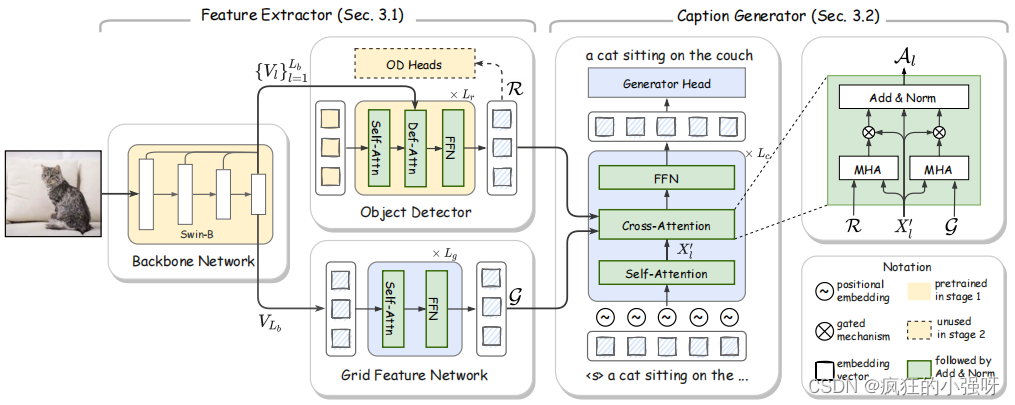
模型架构
整体架构包含两部分:①特征提取 ②文本生成
(1)根据输入图像提取两种特征
● 原始图像提取:
该部分使用的是swin transformer:为什么使用swin transformer???
作者这里给出解释:vit把图像分成小的patches,然后使用全局注意力,对于空间密集任务不适用;目标检测增加了二次计算的复杂度;而swin transformer通过整合支持局部注意力的滑动窗口和减少补丁在一定程度上解决了上述问题
● 局部特征提取:
使用的是 Deformable DETR 模型中的decoder,接受多尺度的图像特征和N个可学习的对象请求作为输入,最终输出一个N×d 维的区域特征
虽然该局部特征提取模型也会作为整个模型的一部分进行训练,但是作者在训练之前进行了预训练和微调,目的是获取更好的视觉语义信息
注: Deformable DETR结合可变形卷积的稀疏空间采样和Transformer的关系建模能力的优点,其注意力模块只关注参考周围的一小组关键采样点,该模块可以自然地扩展到聚合多尺度特征而无需FPN,利用(多尺度)可变形注意模块代替Transformer注意模块处理特征映射。Deformable DETR可以比DETR(尤其是在小物体上)获得更好的性能,训练时间减少了10倍。
● 网格特征提取
采用了具有L个层的标准自注意变压器来提取网格特征
(2)生成文本
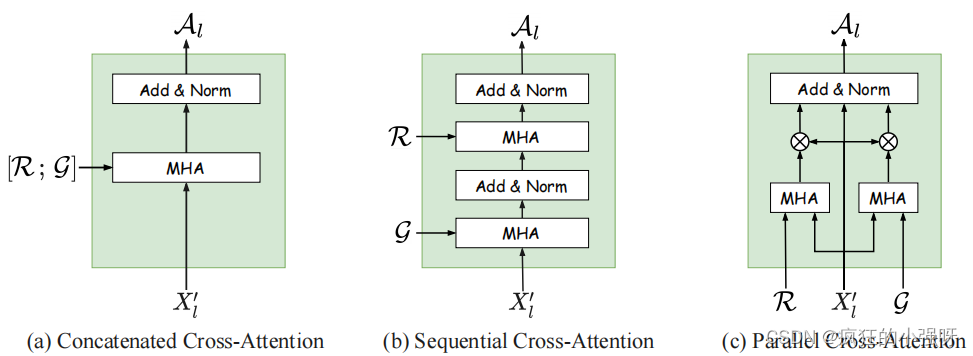
解码器用的是transformer解码器,但是在交叉注意力设计上作者尝试了三种方法:
消融实验证明最后一种方法结果最好!
(3)损失函数
交叉熵损失函数+CIDEr-D优化

















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











