







Image Captioning: Transforming Objects into Words
2019-NIPS
Simao Herdade, Armin Kappeler, Kofi Boakye, Joao Soares
问题
目前方法没有利用被检测对象之间的空间关系信息,如“相对位置”和“相对大小”。而这些信息通常对于理解图像中的内容至关重要。
思想
基于Transformer模型,并添加“对象关系”模块,通过几何注意将对象之间的空间关系信息整合在一起,用来生成更好的描述。
方法
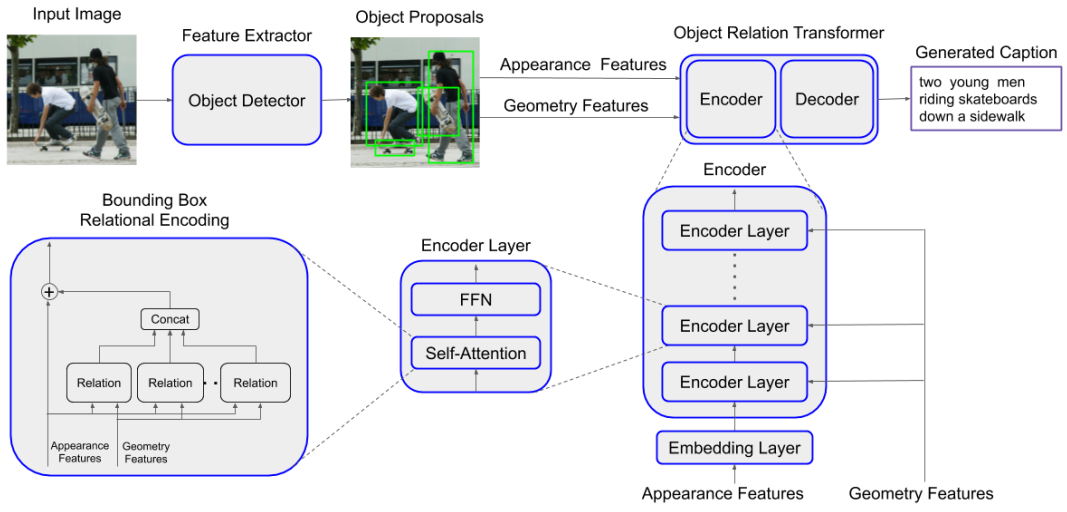
1.目标检测
使用基于Resnet101的Faster R-CNN进行目标检测和特征提取。为每个对象的包围盒生成一个2048维的特征向量,然后将这些特征向量用作Transformer模型的输入。
2.标准的transformer模型
包含encoders和decoders,(6层encoder或decoder堆成)。输入特征向量,输出预测词。
encoders:
①每个特征向量经过嵌入层处理,将维数从2048降至512;
②嵌入的特征向量作为Transformer模型的第1层encoder的输入;对于第2到6层,使用前一编码器层的输出作为输入;
③每个encoder层由一个多头自注意层和一个前馈神经网络组成。
自我注意层由8个相同的头组成;每个头先分别计算Q、K、V,
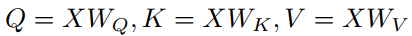
然后计算权重
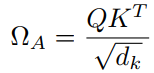
每个头输出向量
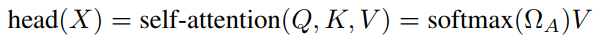
最终拼接8个头得到向量(乘以参数矩阵后使得大小不变)
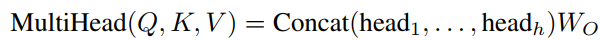
最后,送至前馈网络(FFN),
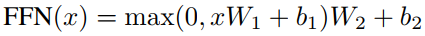
decoders:
每一层decoder使用最后一层encoder以及前一层decoder的输出作为输入来生成文本。
3.加入“对象关系”的transformer模型(在2的encoders部分有一些修改)
①对于物体m和物体n,利用几何特征计算位移矢量(x,y,w,h指包围盒的中心坐标,宽度,高度):

然后得到几何注意权重:
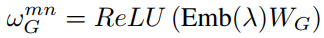
每个头将几何权重和2中提到的基于外观的权重结合,得到新的权重:
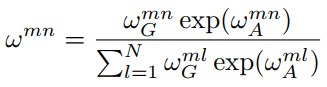
最后每个头输出(Ω是上面元素组成的N×N矩阵):
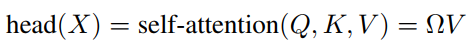
总结
在传统transformer上进行改进,推出Object Relation Transformer,特别适合于图像字幕的任务。目前,只考虑了编码器阶段的几何信息。下一步,作者打算在我们的解码器的对象和单词之间的交叉注意层中加入几何注意。















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









