






摘要
文章提出的动态卷积能够根据输入,动态地集成多个并行的卷积核为一个动态核,可以提升模型表达能力而无需提升网络深度与宽度。通过简单替换成动态卷积,MobileNetV3-small取得了2.3%的性能提升且仅增加了4%的FLOPS,在COCO关键点检测任务中取得了2.9MAP性能提升。
文章地址:Dynamic Convolution: Attention over Convolution Kernels
方法
动态卷积的目标是在在网络性能与计算负载中寻求均衡,主要是通过多卷积核融合提升模型表达能力。所得卷积核与输入相关,即不同数据具有不同的卷积。
对于传统感知器:
y
=
g
(
W
T
x
+
b
)
y=g(W^Tx+b)
y=g(WTx+b),其中
W
,
b
,
g
W,b,g
W,b,g分别表示权值、偏置以及激活函数。
对于文章提出的动态感知器:

其中
π
k
\pi_k
πk表示注意力权值。注意力权值并非固定的,而是随输入变化而变化。因而,相比静态卷积,动态卷积具有更强的特征表达能力。
动态感知的结构如图1。

图1
类似于动态感知器,动态卷积同样具有K个核。按照CNN中的经典设计,作者在动态卷积后接BatchNorm与ReLU。动态卷积层结构如图2。

图2
为了解决注意力的稀疏使得仅有部分核得到训练,使训练变得低效的问题,作者提出采用平滑注意力方式促使更多卷积核同时优化:
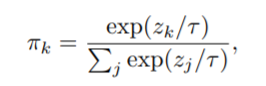
实验
作者在ImageNet数据集上对所提方法进行了验证。模型包含MobileNetV2/V3,ResNet等。动态卷积中的核数目K设置为4,注意力权值归一化因子为30。可以看到:动态卷积可以使模型得到性能提升,而计算量增加仅为4%。DY-ResNet可以得到2.3%的性能提升,DY-MobileNetV2可以得到2.4%的性能提升,DY-MobileNetV3-small可以得到2.3%的性能提升。

总结
作者提出的动态卷积可以根据输入自适应融合多个卷积核。且比起静态卷积,可以明显的提升模型表达能力与性能,这有助于高效CNN架构设计。该动态卷积具有“即插即用”特性,可以轻易嵌入到现有网络架构中。















 1814
1814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









