







介绍
- 用户一方面需要关系型操作,另一方面需要过程式的操作,shark只能进行关系型操作。Spark SQL可以将两者结合起来。
- Spark SQL由两个重要组成部分
- DataFrame API
- 将关系型的处理与过程型处理结合起来,可以对外部数据源和Spark内建的分布式集合进行关系型操作
- 压缩的列式存储,而不是Java/Scala对象
- Catalyst
- 提供了一整套性能分析、计划、运行时代码生成等的框架
- 非常容易的添加数据源、优化规则、数据类型(比如机器学习)、控制代码生成
- DataFrame API
- Spark SQL首次发布于2014年5月,是spark最活跃的组件。是spark核心API的重要演进,machine
learning已经(论文发表于2015年5月)使用DataFrame API,未来GraphX
和streaming也会使用DataFrame API
Background and Goals
- Spark概要
- RDD做为通用计算引擎基础
- 以血统(lineage)作为容错方式
- Spark延迟(lazily)执行,可以做查询优化
- Shark
- Shark只支持查询Hive支持的数据
- 只能通过SQL方式调用Shark
- Hive的优化器是为MapReduce量身定制的,难以支持新的方式,如机器学习
- 目标
- Support relational processing both within Spark programs (on native RDDs) and on external data sources using a programmer friendly API.
- Provide high performance using established DBMS techniques.
- Easily support new data sources, including semi-structured data and external databases amenable to query federation.
- Enable extension with advanced analytics algorithms such as graph processing and machine learning
Programming Interface
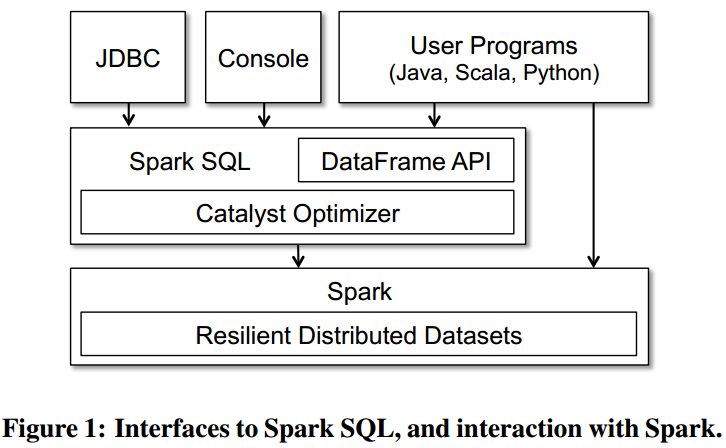
- DataFrame API
- DataFrame 支持从内部或者外部的数据源表、还有RDD,进行创建
- Data Model
- 支持Hive数据模型,支持所有主要的SQL数据类型,也支持structs, arrays,maps and unions复杂类型
- 首要(first-class)支持查询语言的类型和API,也支持用户自定义类型
- 现已支持Hive,RDBMS,JSON,Java/Scala/Python原生对象
- DataFrame Operations
- DataFrames support all common relational operators, including
projection (select), filter (where), join, and aggregations (groupBy)
- DataFrames support all common relational operators, including
- Querying Native Datasets
- 通过反射支持RDD
- Scala\Java通过系统类型、Python通过数据抽样推断出类型信息
- In-Memory Caching
- 可以将热数据以列存储的方式放到内存中,相对于JVM对象,列存储占用内存更少,因为可以用如字典编码(dictionary encoding)或者行程编码(run-length encoding)压缩方式压缩
- User-Defined Functions
- 自定义函数是内联的,可以直接使用,不用编译成包
- 一旦注册,可以通过JDBC/ODBC接口调用
#coding=utf-8
from pyspark import SparkContext, SparkConf
from pyspark.sql import HiveContext,SQLContext
import string
#HiveContext继承SQLContext, SQLContext支持的HiveContext都支持;
#HiveContext和SQLContext打开后属于两个不同的session,一个session看不到另一个session的临时表
sc = SparkContext(conf="")
hiveSql = HiveContext(sc)
hiveSql.registerFunction("get_family_name", lambda x:string.split(x, " ")[0]) #注册函数
student = hiveSql.table("tmp_dp.student") #读取HIVE数据
student.where(student.sex < 5).registerTempTable("stud") #注册成临时表
score_path = "/data/tmp/score/score.json"
score = hiveSql.jsonFile(score_path) #JSON数据
score.registerTempTable("score") #注册成临时表
sqls = """select get_family_name(st.name), avg(sc.performance.math)
from stud st, score sc
where st.stu_id = sc.stu_id
group by get_family_name(st.name)
"""
df = hiveSql.sql(sqls)
for col in df.collect(): #输出结果
print col[0:len(col)]
sc.stop()Catalyst Optimizer
- 目的
- 容易添加新的优化规则和特性
- 外部开发者可以扩展优化器
- 支持基于规则和基于成本的优化
- Catalyst
- 使用scala标准的特性,如pattern-matching,而不是DSL
- Catalyst核心包含了一个处理trees和rules的通用库,在此库基础之上,针对不同的阶段进行特殊处理。
- 执行阶段
- analysis, logical optimization, physical planning, and code
generation to compile parts of queries to Java bytecode
- analysis, logical optimization, physical planning, and code
- 执行阶段
- Scala quasiquotes使得代码生成非常容易
- Catalyst还提供了外部数据源和用户自定义类型
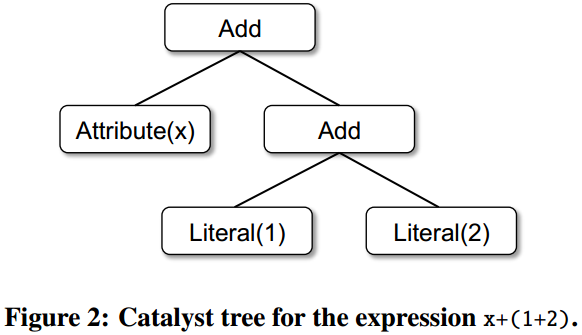
- Trees
- Calalyst核心数据类型是由若干个节点组成的树
- x+(1+2) Scala code 表达式Add(Attribute(x), Add(Literal(1), Literal(2)))
Rules
- Trees由Rules操作,是一个tree到其他tree的功能实现
- trees offer a transform method
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
}
- Catalyst groups rules into batches, and executes each batch until it
reaches a fixed point, that is, until the tree stops changing after
applying its rules.
- Catalyst groups rules into batches, and executes each batch until it
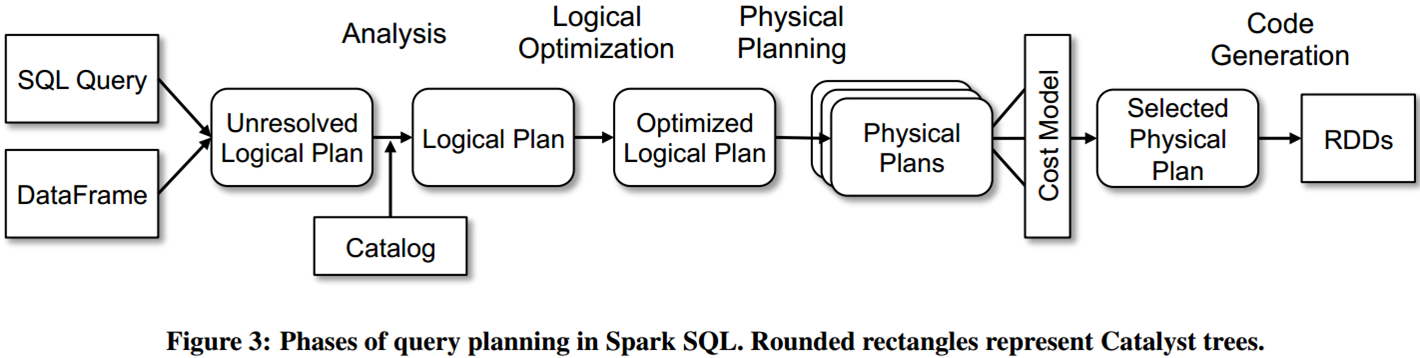
Using Catalyst in Spark SQL
在physical planning阶段,Catalyst生成多个计划并基于成本对他们进行比较;其他阶段都是基于规则的;
每个阶段都使用不同类型的树
Analysis
逻辑计划步骤
Looking up relations by name from the catalog.
Mapping named attributes, such as col, to the input provided given operator’s children.
Determining which attributes refer to the same value to give them a unique ID (which later allows optimization of expressions such as col = col).
Propagating and coercing types through expressions: for example, we cannot know the return type of 1 + col until we have resolved col and possibly casted its subexpressions to a compatible types.
Logical Optimization
- The logical optimization phase applies standard rule-based optimizations to the logical plan. These include constant folding, predicate pushdown, projection pruning, null propagation, Boolean expression simplification, and other rules.
Physical Planning
- 从逻辑计划生成一个或多个物理执行计划,基于成本模型从中选择一个。只会使用基于成本的优化选择JOIN算法。物理计划也支持基于规则的优化,如pipelining
projections or filters into one Spark map operation
- 从逻辑计划生成一个或多个物理执行计划,基于成本模型从中选择一个。只会使用基于成本的优化选择JOIN算法。物理计划也支持基于规则的优化,如pipelining
Code Generation
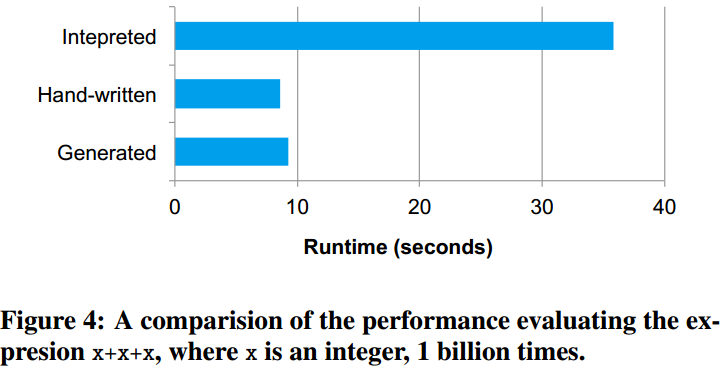
物理执行计划后,生成Java bytecode然后在每一台机器上执行。
(x+y)+1, Without code generation, such expressions would have to be interpreted for each row of data, by walking down a tree of Add, Attribute and Literal nodes. This introduces large amounts of branches and virtual function calls that slow down execution.
Extension Points
Data Sources
All data sources must implement a createRelation function thattakes
a set of key-value parameters and returns a BaseRelationobject for
that relationTo let Spark SQL read the data, a BaseRelation can implementone of
several interfaces that let them expose varying degrees
ofsophistication. 如:TableScan、PrunedScan、PrunedFilteredScan
User-Defined Types (UDTs)
- To register a Scala type as a UDT, users provide a mapping from an
object of their class to a Catalyst Row of built-in types, and an inverse mapping back.
- To register a Scala type as a UDT, users provide a mapping from an
Advanced Analytics Features
- Schema Inference for Semistructured Data
{
"text": "This is a tweet about #Spark",
"tags": ["#Spark"],
"loc": {"lat": 45.1, "long": 90}
}
{
"text": "This is another tweet",
"tags": [],
"loc": {"lat": 39, "long": 88.5}
}
{
"text": "A #tweet without #location",
"tags": ["#tweet", "#location"]
}以上数据可用以下SQL查询
SELECT loc.lat, loc.long FROM tweets WHERE text LIKE ’%Spark%’ AND tags IS NOT NULL - the algorithm attempts to infer a tree of STRUCT types, each of which
may contain atoms, arrays, or other STRUCTs类型转换成兼容类型
- use the same algorithm for inferring schemas of RDDs of Python
objects
- Integration with Spark’s Machine Learning Library
data = <DataFrame of (text , label) records >
tokenizer = Tokenizer().setInputCol("text").setOutputCol("words")
tf = HashingTF().setInputCol("words").setOutputCol("features")
lr = LogisticRegression().setInputCol("features")
pipeline = Pipeline().setStages([tokenizer , tf, lr])
model = pipeline.fit(data)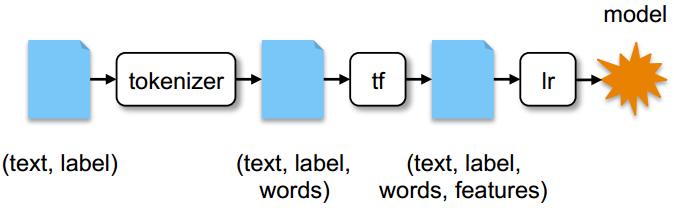
Figure 7: A short MLlib pipeline and the Python code to run it.We start with a DataFrame of (text, label) records, tokenize the text into words, run a term frequency featurizer (HashingTF) to get a feature vector, then train logistic regression.
- Query Federation to External Databases
CREATE TEMPORARY TABLE users USING jdbc OPTIONS(driver "mysql" url "jdbc:mysql://userDB/users");
CREATE TEMPORARY TABLE logsUSING json OPTIONS (path "logs.json");
SELECT users.id, users.name , logs.message FROM users, logs
WHERE users.id = logs.userId AND users.registrationDate > "2015-01-01“;在MySQL上的查询
SELECT users.id, users.name FROM usersWHERE users.registrationDate > "2015-01-01"Evaluation
- SQL Performance
spark官方测试
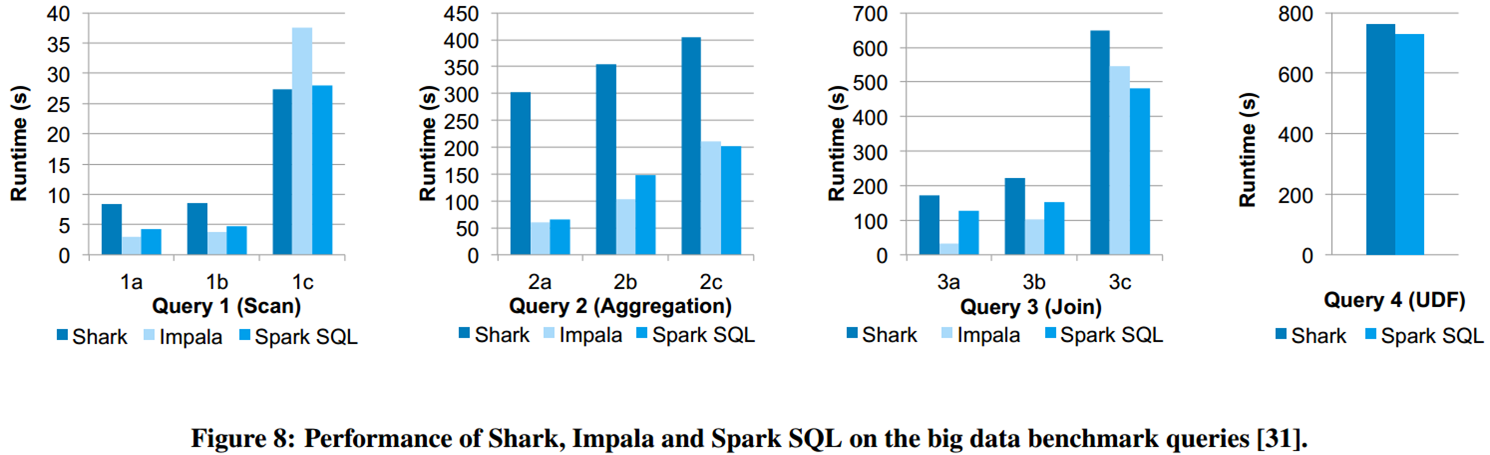
impala官方测试
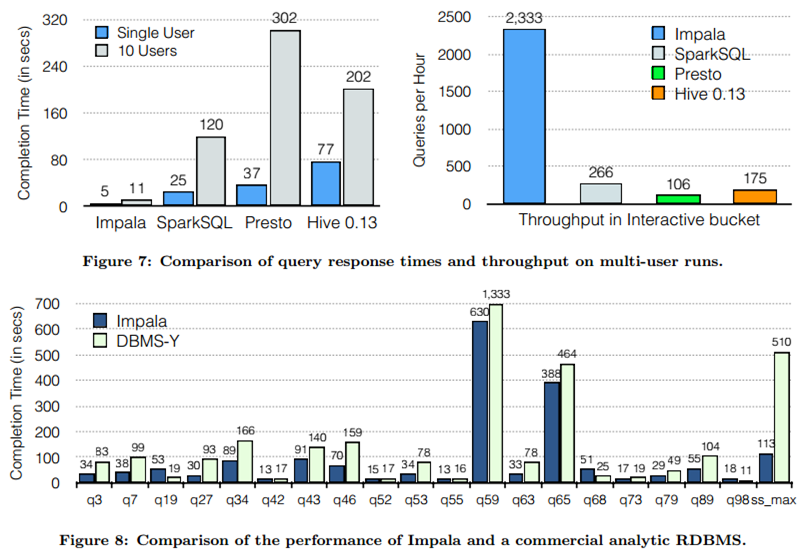
- used a cluster of six EC2 i2.xlarge machines (one master, five
workers) each with 4 cores, 30 GB memory and an 800 GB SSD, running
HDFS 2.4, Spark 1.3, Shark 0.9.1 and Impala 2.1.1. The dataset was
110 GB of data after compression using the columnar Parquet format
- The main reason for the difference with Shark is code generation in
Catalyst (Section 4.3.4), which reduces CPU overhead. This feature
makes Spark SQL competitive with the C++ and LLVM based Impala engine
in many of these queries. The largest gap from Impala is in query 3a
where Impala chooses a better join plan because the selectivity of
the queries makes one of the tables very small.
- DataFrames vs. Native Spark Code
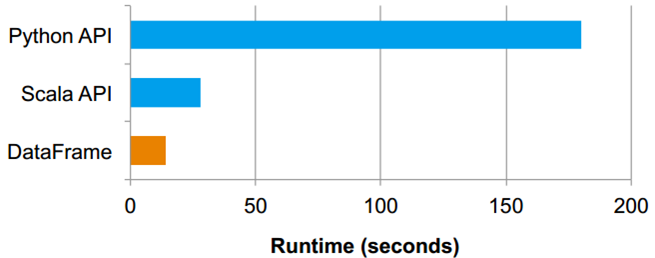
The dataset consists of 1 billion integer pairs, (a, b) with 100,000 distinct values of a, on the same five-worker i2.xlarge cluster as in the previous section.
- map and reduce functions in the Python API for Spark
sum_and_count = \
data.map(lambda x: (x.a, (x.b, 1))) \
.reduceByKey(lambda x, y: (x[0]+y[0], x[1]+y[1])) \
.collect()
[(x[0], x[1][0] / x[1][1]) for x in sum_and_count] - DataFrame API
df.groupBy("a").avg("b")This is because in the DataFrame API, only the logical plan is constructed in Python, and all physical execution is compiled down into native Spark code as JVM bytecode, resulting in more efficient execution. In fact, the DataFrame version also outperforms a Scala version of the Spark code above by 2⇥. This is mainly due to code generation: the code in the DataFrame version avoids expensive allocation of key-value pairs that occurs in hand-written Scala code.
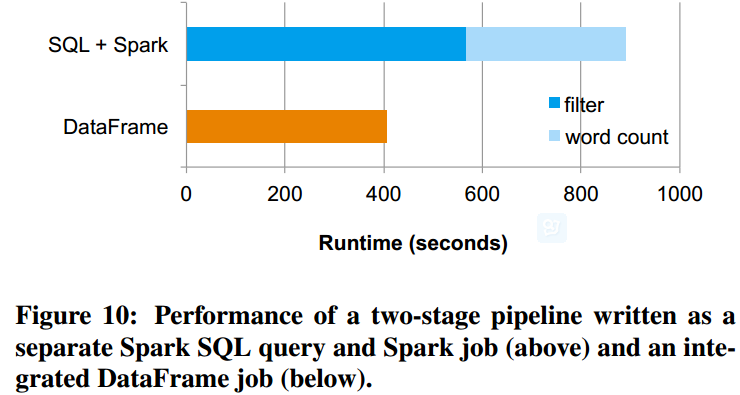
- Pipeline Performance
- a synthetic dataset of 10 billion messages in HDFS. Each message
contained on average 10 words drawn from an English dictionary. The
first stage of the pipeline uses a relational filter to select
roughly 90% of the messages. The second stage computes the word
count. - Compared with the first pipeline, the second pipeline avoids the cost
of saving the whole result of the SQL query to an HDFS file as an
intermediate dataset before passing it into the Spark job, because
SparkSQL pipelines the map for the word count with the relational
operators for the filtering.
- a synthetic dataset of 10 billion messages in HDFS. Each message
参考
原论文 https://amplab.cs.berkeley.edu/publication/spark-sql-relational-data-processing-in-spark/
利用In-Database Analytics技术在大规模数据上实现机器学习的SGD算法 http://www.infoq.com/cn/articles/in-database-analytics-sdg-arithmetic/
spark 大型集群上的快速和通用数据处理架构 https://code.csdn.net/CODE_Translation/spark_matei_phd
数据库系统实现 机械工业出版社
数据库系统概念 机械工业出版社















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









