






这篇文章主要介绍TF中张量,图,变量,会话以及神经网络模型。
张量(tensor)
Tensor可以说是Tensor flow中最重要的概念之一,毕竟Tensor flow翻译过来就是张量流。
张量是TF中管理数据的形式,可以理解为多维矩阵。TF中Tensor的维数被称为阶,数值是零阶张量,一阶张量是向量,也就是一维数组。n阶张量就是n维数组。
一个张量主要有三个属性:名字,维度,类型。在对张量的操作中,不同类型会引发错误。在张量中没有保存真正的数字,而是保存了如何得到这些数字的计算过程。
图(graph)
TF中把所有操作抽象为有向无环图,如下例子就是TF 中典型的例子。
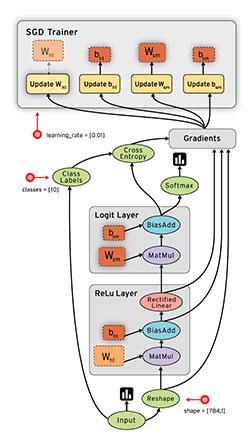
变量(variable)
变量是一种特殊的数据,在图中有固定的位置,不能流动。我们使用tf.Variable()来创造变量,函数的参数决定了变量的形状和类型。
会话(session)
会话管理TF程序运行中的所有资源,计算完成之后关闭会话来回收资源,否则就可能造成资源泄露。TF中一般使用如下语句生成会话函数
with tf.Session() as sess:
sess.run(…)
神经网络
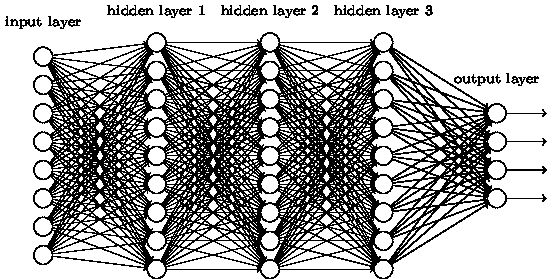
在介绍深层神经网络之前,先说下浅层神经网络,以其中的BP神经网络为例,神经网络通常由输入层、隐含层、和输出层构成,如果没有隐含层,只是将多个输入与不同的权重和再经过一个激活函数(activate function)作为输出,这种最简单的神经网络成为感知机。
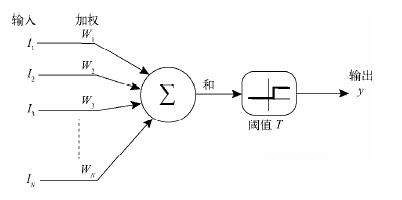
感知机可以理解为单层的神经网络,但是感知机能力有限,不能解决异或问题。而BP神经网络含有隐含层,功能也更为强大。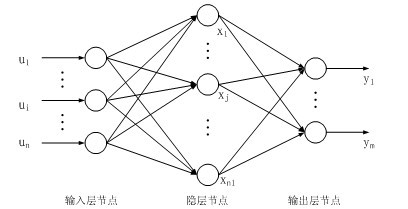
BP神经网络的输入层、隐含层和输出层都可以有数量不限个神经元,输入x与权重值进行运算后得到结果y,训练的过程就是不断调整权重的过程,使得输出尽可能的符合预期值。整个训练过程需要三个函数:损失函数(loss function)、优化函数(optimiz function)和激活函数(activate function)。
为什么需要损失函数?
在分类问题中,样本数据中有标签,程序随机初始化的权重也会得到一个输出,通过比较标签值与输出之间的距离来刻画权重值的优劣,距离就是损失函数。如果输出与标签值之间没有距离,换言之,损失函数为0,这时我们就找到了最佳的权重。这在实际中一般是不可能的,如果出现这种情况,很有可能是过拟合。虽然在训练集上表现很好,但是在测试集上却差强人意,这是要避免的一种情况。当然,我们的目标是在避免过拟合的情况下使损失函数尽可能的小。
分类问题通常采用交叉熵函数,交叉熵刻画的是两个概率分布之间的距离,通过softmax函数可以把标签和输出转化为概率分布,在TF中通常调用
loss=softmax_cross_entropy_with_logits(logits =pred, labels=y)其中pred为预测值,即程序 训练阶段的输出值,y就是标签值,loss就是损失值,如何找到最小的损失值,转化为数学问题就是就是找极小值。怎么更快的找到极小值,这就需要优化函数。
目前训练的方法大都是基于梯度下降法改进而来,优劣差异不大。下面说下梯度下降法
主要参考http://blog.csdn.net/walilk/article/details/50978864
在高数中我们已经知道,梯度是函数的方向导数的最大值,是一个向量。可以理解为函数在梯度的方向上的变化率最大,也就是说,梯度的方向就是函数增加最快的方向,所以我们要去找梯度的反方向,这个方向函数减小的最快。
但是梯度下降法也有一些缺点,第一:找到的极值点不一定是全局的最优解。虽然每一步都采取最佳的路线来走,但是也有可能陷在一个小坑里出不来。如图
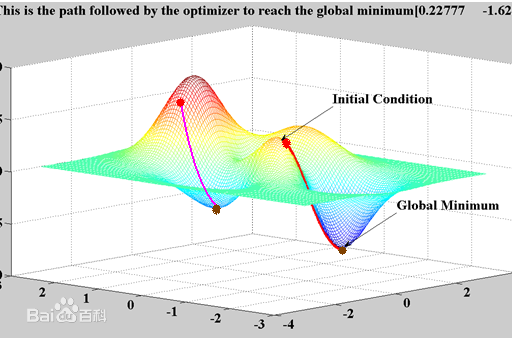
另外一个问题就是训练时间太长。
为了加速训练过程,可以使用随机梯度下降算法(SGD)
随机梯度下降算法优化的不是全部训练数据上的损失函数,而是在每一轮迭代中随机优化某条训练数据上的损失函数。但是SGD也有缺陷,这种方法甚至连局部最优都达不到,因此又有了批梯度下降法(BGD)
批梯度下降法利用现有参数对训练集中的每一个输入生成一个输出y_然后与实际的标签y进行比较,统计所有误差,求平均以后得到平均误差,以此作为更新参数的依据。优点是 使用所有训练数据,保证收敛。缺点是 每一步需要使用所有的训练数据,随着训练的进行,速度会越来越慢。
虽然优化函数不好实现,但是TF中已经提供了多个优化函数,使用时调用tf.train . 优化函数
如tf.train.RMSPropOptimizer()
激活函数
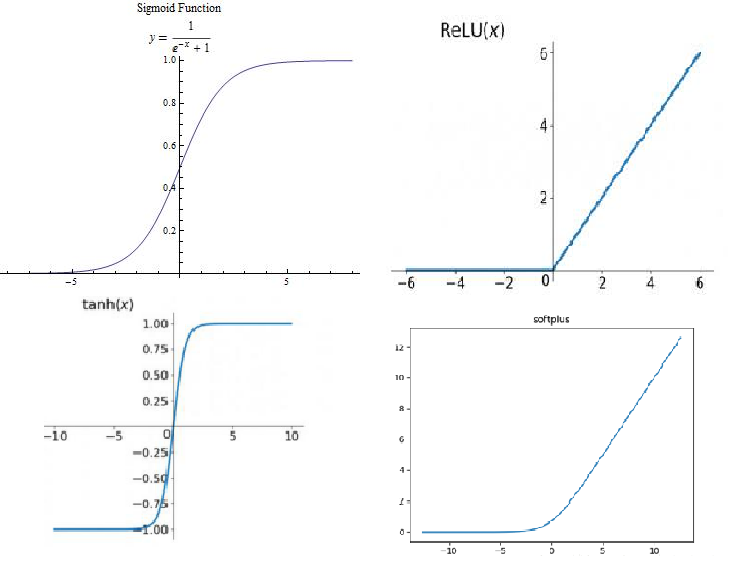
激活函数主要使神经元的输出非线性化,如果不用激活函数或者说是阈值函数,结果只能处理线性问题,为了解决非线性问题,就需要非线性的激活函数,常用的激活函数有sigmoid、tanh、relu、softplus以及随机正则化函数dropout这几种。
sigmoid是以往最常用的激活函数,优点在于输出映射在(0,1)内,单调 连续,求导容易,非常适合做输入层,但是在深层神经网络中,非常容易产生梯度消失。
tanh函数形状与sigmoid差不多,收敛速度比sigmoid函数快,但也会产生梯度消失。
relu函数是目前最流行的激活函数,定义为f(x)=max(x,0),在<0时值为0,在>0时导数为1,缓解梯度消失的问题。还能更快的收敛,但是,随着训练的进行,有些权重会无法更新,造成“神经元死亡”。
softplus可以看作是relu的平滑版本,定义为f(x)=log(1+exp(x)).
dropout函数,以keep_prop的概率来决定一个神经元是否抑制,如果抑制,神经元的输出为0,如果不抑制,输出为原来的1/keep_prop倍,一般用在最后几层。
总之,神经网络的训练过程可以概述为:输入数据,经过激活函数,构建损失函数,通过优化函数使损失函数变得最小,得到最佳权重值,然后在测试集上进行测验。
深层神经网络在浅层神经网络的基础上主要是增加了隐含层,隐含层越多,神经网络就越深。当然层与层之间的连接方式也有所改变,不再采用全连接的形式。避免参数过多训练时间过长,还容易导致过拟合的问题。
参考文章: TensorFlow实战Google深度学习框架 才云科技 郑泽宇
Tensor Flow技术解析与实践 李嘉璇

















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









