







1.采集京东读书
我们先梳理下操作流程
首先,在首页输入要爬取的书籍名称,输入后,搜索
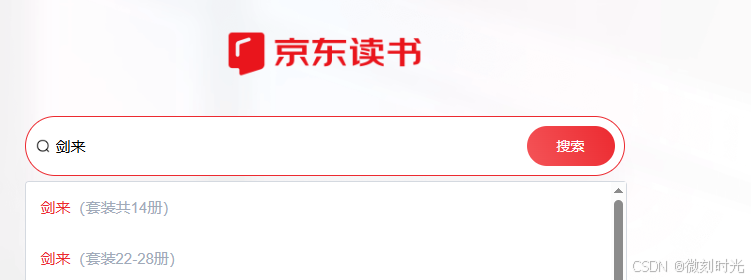
出现搜索结果后,会有很多版本的书籍
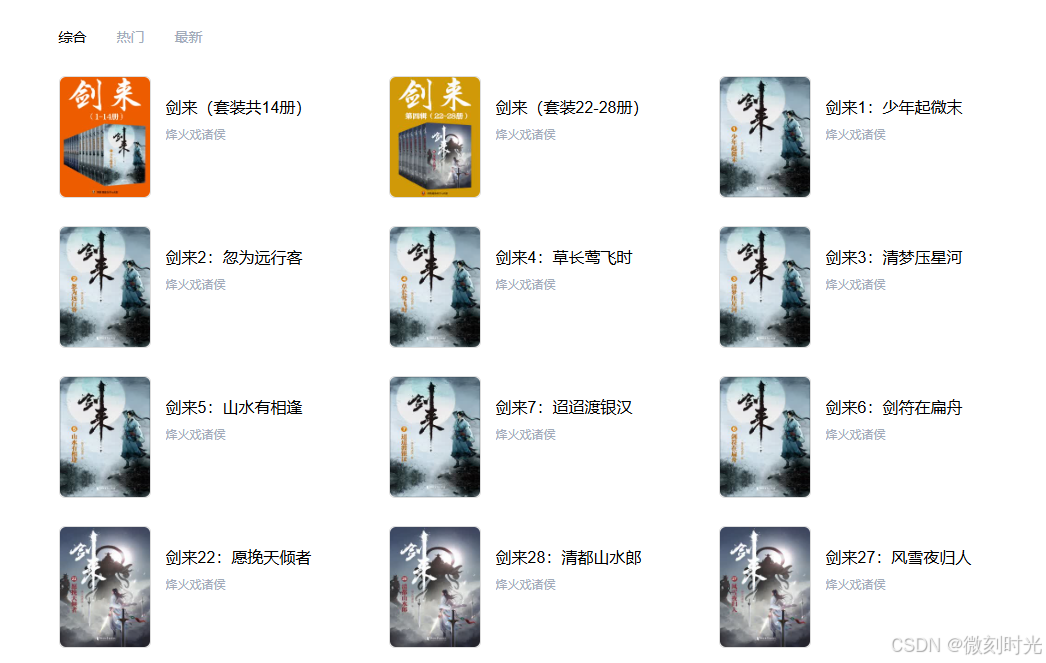
我们点击热门筛选,让书记排序,这样可以将最符合我们需求的书籍显示在第一位

点击第一本图书,点击立即阅读
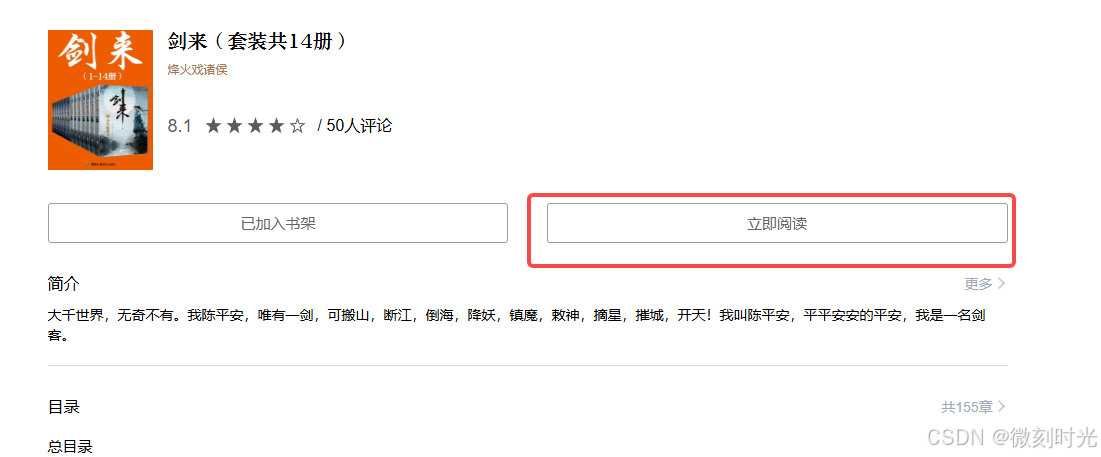
开始采集,
第一,我们采集书籍封面

第二,我们采集目录信息

第三 采集章节

2.实战代码
2.1 主体代码
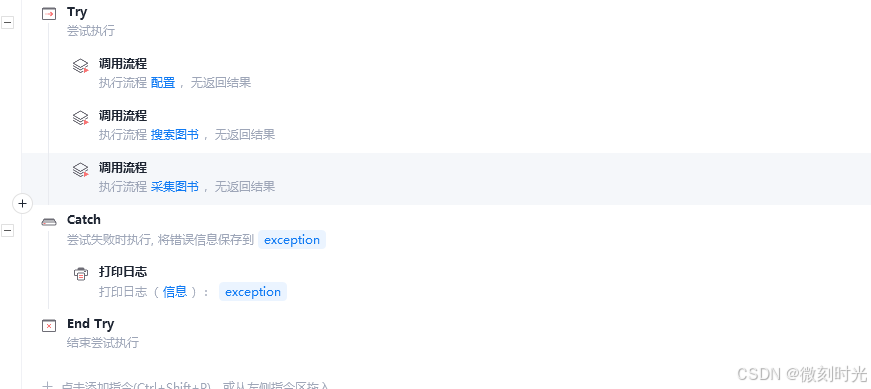
2.2 采集前的配置
通过对话框指令,设置采集的书籍名称

通过对话框指令,设置采集的书籍的保存路径

2.3 搜索图书
图书搜索,并点击阅读,进入采集环境
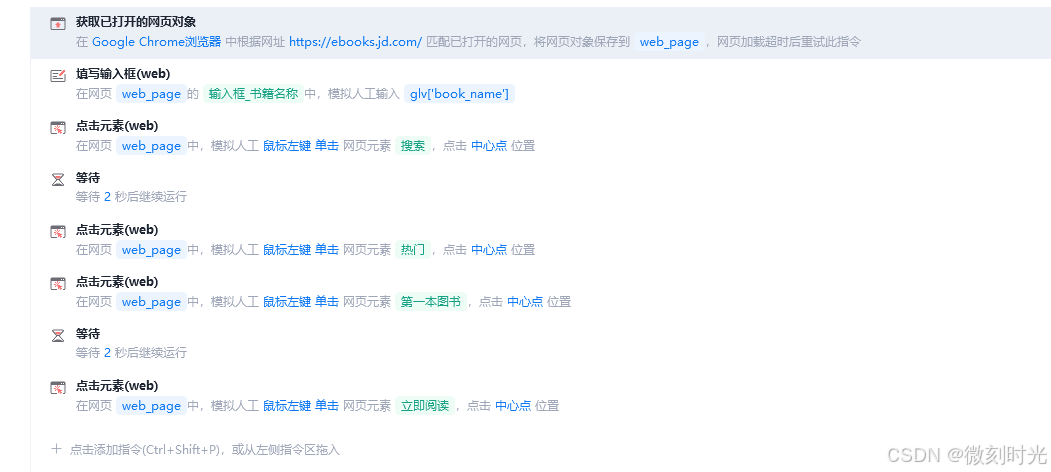
2.4 采集代码
采集书籍封面图片

采集目录或内容
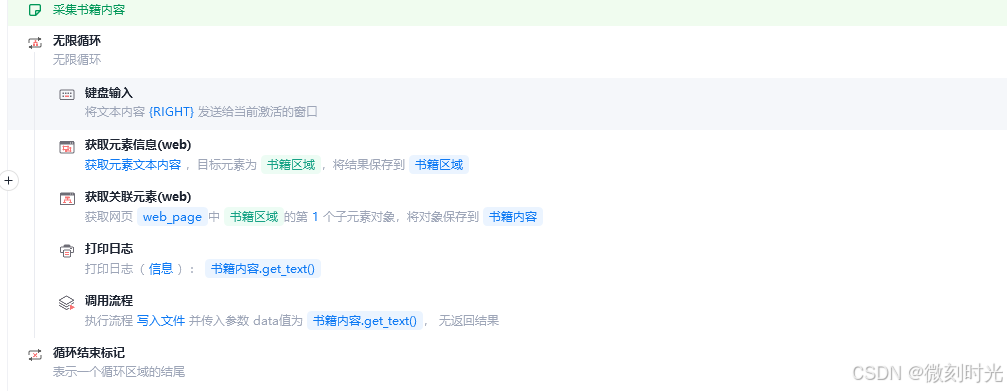
京东读书,没有分页按钮,通过键盘左右键翻页,所以,我们采用无限循环指令,加键盘像右键,翻页采集内容
书籍内容,我们通过关联元素,指定位置获取

最后将采集的内容写入txt中

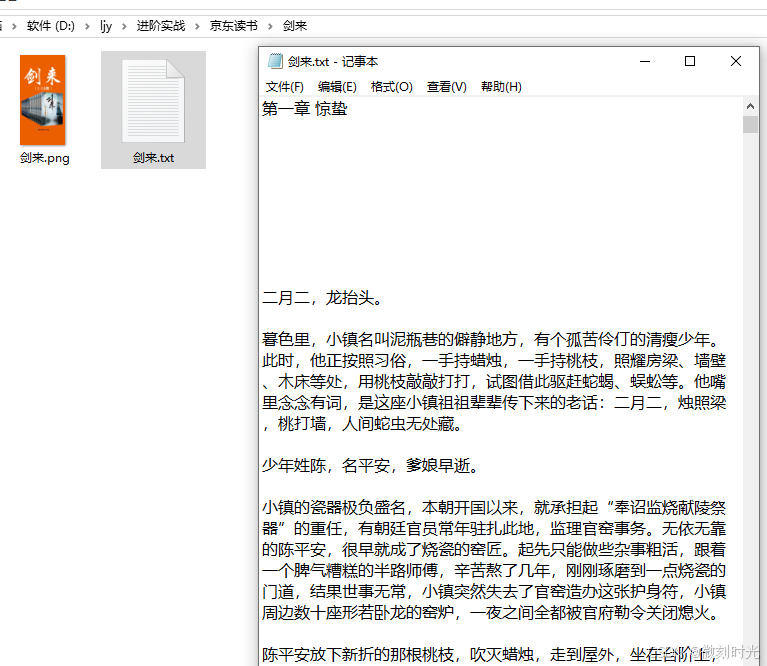
3.战果演示
4.最后
影刀RPA在做爬虫方面具有显著优势,主要体现在以下几个方面:
易用性与低门槛
影刀RPA采用完全图形化的流程设计,操作界面直观,用户无需编写代码,通过简单的拖拽和配置即可快速搭建自动化爬虫任务。这种低代码甚至无代码的设计方式,极大地降低了技术门槛,即使是非技术人员也能快速上手并完成简单的爬虫任务。同时,影刀RPA提供了丰富的教程和社区支持,进一步降低了学习成本。
快速开发与部署
影刀RPA能够快速实现自动化任务,尤其适合处理重复性高、规则性强的爬虫任务。与传统编程方式相比,其开发周期更短,能够快速响应业务需求并投入使用。这种快速开发和部署的能力,使得企业在面对紧急数据采集需求时,能够迅速响应并获取所需数据。
资源占用低
影刀RPA对硬件资源的占用较低,适合在普通PC上运行,无需高端配置的服务器。这使得企业在使用影刀RPA进行爬虫任务时,能够有效降低硬件成本,同时避免了因资源不足导致的运行卡顿或崩溃问题。
抗反爬虫能力强
影刀RPA通过模拟人类操作行为,能够有效规避一些简单的反爬虫机制。它可以根据实际情况灵活调整操作频率、等待时间等参数,从而更好地应对目标网站的反爬虫策略。这种灵活性使得影刀RPA在面对复杂的网络环境时,依然能够稳定运行。
数据处理与扩展性强
影刀RPA不仅可以从网页中采集数据,还能操作Excel、PDF、Word等文件,甚至可以连接数据库和API,实现多种数据源的采集与整合。此外,影刀RPA支持与Python等编程语言结合,进一步扩展功能,满足复杂的数据处理需求。
维护与扩展性好
影刀RPA的图形化流程设计使得整个自动化任务的逻辑清晰可见,便于后期维护和扩展。当业务需求发生变化时,用户可以快速调整流程,而无需重新编写代码。这种良好的维护性和扩展性,使得影刀RPA能够适应企业不断变化的业务需求。
总结
影刀RPA在做爬虫方面具有易用性高、开发快速、资源占用低、抗反爬虫能力强、数据处理与扩展性强以及维护性好等多方面优势。它不仅降低了技术门槛,使得非技术人员也能轻松上手,还能够快速响应业务需求,有效降低硬件成本。影刀RPA的灵活性和扩展性使其能够适应复杂多变的网络环境和业务需求,是企业进行数据采集和自动化处理的有力工具。


















 9516
9516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











