










 本文详细介绍VGG网络模型的构建、训练与测试过程。VGG网络是一种深度卷积神经网络,能有效提取图像特征,适用于大规模图像识别任务。文中通过实例展示了如何使用VGG16进行猫狗分类,包括数据集加载、图像预处理、网络训练及验证。
本文详细介绍VGG网络模型的构建、训练与测试过程。VGG网络是一种深度卷积神经网络,能有效提取图像特征,适用于大规模图像识别任务。文中通过实例展示了如何使用VGG16进行猫狗分类,包括数据集加载、图像预处理、网络训练及验证。
VGG网络训练和测试
简单介绍
VGG是卷积网络里面比较常见的网络模型,相比LeNet要复杂一些,但是都属于拓补结构简单直接的前置反馈网络,详细信息可参考论文VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION,VGG网络能够提取更多的图像特征,最后输出的特诊向量信息量更丰富,所以可以进行更大规模的分类,前面介绍的LeNet5可以产生10个分类,分别对应0~9, VGG可以产生上万个分类,识别更多的类型。VGG也是Faster RCNN的基础,Faster RCNN在现实当中实用性更强,能在任意图像内进行目标定位,然后再进行目标识别。
下图是从论文中截取的一张网络配置图,并加上代码中对应的层:

这张表后面结合代码再做详细描述,与前面笔记中提到的LeNet5相比:
| Network | 网络层数 | 权重层数 | 参数个数 |
|---|---|---|---|
| LeNet5 | 7 | 5 | 61706 |
| VGG16(D) | 39 | 16 | 138357544 |
| 可想而知VGG要比LeNet5复杂很多,运算量也大很多,训练时间更长,训练的网络状态所占空间也越大。 | |||
| 在我的机器上(MacBook Pro 2017), 用CPU训练,60000张MNIST训练图片(1x28x28)2轮学习花了10分钟左右,10000张测试图片花了10秒,但是8000张左右猫狗训练集(3x可变长宽)2轮学习花了6.7个小时, 2000张测试图片识别花了11分钟左右。GPU可能快很多,目前没试过。 | |||
| 从上表中也能看出一般网络模型命名规律:网络模型名 + 权重层数,所以有LeNet-5, VGG-11, VGG-16和VGG-19这些名称。 |
网络构建
根据上述论文,选择ConvNet Configuration D,也称作VGG16,基于c++ libtorch库用如下代码创建了它,在上图中也标出了每层对应的module名称,这些网络层的命令是,模型名称缩写+所在第几层,如C29,就是卷积层(Convolutional network, C)在本网络中位于第29层, FC38就是全连接层(FullConnection, FC)在此网络中位于第38层。
另外有些网络层就是做一个简单操作,比如RELU, MaxPool等,就不注册网络层,具体就在forward中当作function来in-place处理。
VGGNet::VGGNet(int num_classes)
: C1 (register_module("C1", Conv2d(Conv2dOptions( 3, 64, 3).padding(1))))
, C3 (register_module("C3", Conv2d(Conv2dOptions( 64, 64, 3).padding(1))))
, C6 (register_module("C6", Conv2d(Conv2dOptions( 64, 128, 3).padding(1))))
, C8 (register_module("C8", Conv2d(Conv2dOptions(128, 128, 3).padding(1))))
, C11 (register_module("C11", Conv2d(Conv2dOptions(128, 256, 3).padding(1))))
, C13 (register_module("C13", Conv2d(Conv2dOptions(256, 256, 3).padding(1))))
, C15 (register_module("C15", Conv2d(Conv2dOptions(256, 256, 3).padding(1))))
, C18 (register_module("C18", Conv2d(Conv2dOptions(256, 512, 3).padding(1))))
, C20 (register_module("C20", Conv2d(Conv2dOptions(512, 512, 3).padding(1))))
, C22 (register_module("C22", Conv2d(Conv2dOptions(512, 512, 3).padding(1))))
, C25 (register_module("C25", Conv2d(Conv2dOptions(512, 512, 3).padding(1))))
, C27 (register_module("C27", Conv2d(Conv2dOptions(512, 512, 3).padding(1))))
, C29 (register_module("C29", Conv2d(Conv2dOptions(512, 512, 3).padding(1))))
, FC32(register_module("FC32",Linear(512 * 7 * 7, 4096)))
, FC35(register_module("FC35",Linear(4096, 4096)))
, FC38(register_module("FC38",Linear(4096, num_classes)))
{
...
}
torch::Tensor VGGNet::forward(torch::Tensor input)
{
namespace F = torch::nn::functional;
// block#1
auto x = F::max_pool2d(F::relu(C3(F::relu(C1(input)))), F::MaxPool2dFuncOptions(2));
// block#2
x = F::max_pool2d(F::relu(C8(F::relu(C6(x)))), F::MaxPool2dFuncOptions(2));
// block#3
x = F::max_pool2d(F::relu(C15(F::relu(C13(F::relu(C11(x)))))), F::MaxPool2dFuncOptions(2));
// block#4
x = F::max_pool2d(F::relu(C22(F::relu(C20(F::relu(C18(x)))))), F::MaxPool2dFuncOptions(2));
// block#5
x = F::max_pool2d(F::relu(C29(F::relu(C27(F::relu(C25(x)))))), F::MaxPool2dFuncOptions(2));
x = x.view({ -1, num_flat_features(x) });
// classifier
x = F::dropout(F::relu(FC32(x)), F::DropoutFuncOptions().p(0.5));
x = F::dropout(F::relu(FC35(x)), F::DropoutFuncOptions().p(0.5));
x = FC38(x);
return x;
}
训练网络
加载训练集
这里训练集还是选择网上比较容易找到资源的猫狗训练集,目录结构如下:
I:.
├─test_set
│ ├─cats
│ │ cat.4001.jpg
│ │ cat.4002.jpg
│ │ cat.4003.jpg
. ...........
│ └─dogs
│ dog.4001.jpg
│ dog.4002.jpg
│ dog.4003.jpg
. ...........
└─training_set
├─cats
│ cat.1.jpg
│ cat.10.jpg
│ cat.100.jpg
. .........
└─dogs
dog.1.jpg
dog.10.jpg
dog.100.jpg
..........
label就是training_set子目录名称,比如cats和dogs,如果想要支持其他目标的分类,可以以新的目标名称创建子目录,然后把对应的待训练的图片放到对应的子目录下,以支持更多目标识别。我找到的这个训练集大概有8000张猫狗训练照片集,2000张测试照片集。
HRESULT VGGNet::loadImageSet(
const TCHAR* szRootPath, // the root path to place training_set or test_set folder
std::vector<tstring>& image_files, // the image files to be trained or tested
std::vector<tstring>& image_labels, // the image label
std::vector<size_t>& image_shuffle_set, // the shuffle image set, ex, [1, 0, 3, 4, 2]
bool bTrainSet, bool bShuffle)
{
HRESULT hr = S_OK;
TCHAR szDirPath[MAX_PATH] = { 0 };
TCHAR szImageFile[MAX_PATH] = { 0 };
_tcscpy_s(szDirPath, MAX_PATH, szRootPath);
size_t ccDirPath = _tcslen(szRootPath);
if (szDirPath[ccDirPath - 1] == _T('\\'))
szDirPath[ccDirPath - 1] = _T('\0');
_stprintf_s(szImageFile, MAX_PATH, _T("%s\\%s\\*.*"),
szDirPath, bTrainSet ? _T("training_set") : _T("test_set"));
// Find all image file names under the train set, 2 level
WIN32_FIND_DATA find_data;
HANDLE hFind = FindFirstFile(szImageFile, &find_data);
if (hFind == INVALID_HANDLE_VALUE)
return E_FAIL;
do {
if (!(find_data.dwFileAttributes&FILE_ATTRIBUTE_DIRECTORY) ||
_tcsicmp(find_data.cFileName, _T(".")) == 0 ||
_tcsicmp(find_data.cFileName, _T("..")) == 0)
continue;
WIN32_FIND_DATA image_find_data;
_stprintf_s(szImageFile, MAX_PATH, _T("%s\\%s\\%s\\*.*"), szDirPath,
bTrainSet?_T("training_set"):_T("test_set"), find_data.cFileName);
BOOL bHaveTrainImages = FALSE;
HANDLE hImgFind = FindFirstFile(szImageFile, &image_find_data);
if (hImgFind == INVALID_HANDLE_VALUE)
continue;
do
{
if (image_find_data.dwFileAttributes&FILE_ATTRIBUTE_DIRECTORY)
continue;
// check whether it is a supported image file
const TCHAR* szTmp = _tcsrchr(image_find_data.cFileName, _T('.'));
if (szTmp && (_tcsicmp(szTmp, _T(".jpg")) == 0 ||
_tcsicmp(szTmp, _T(".png")) == 0 ||
_tcsicmp(szTmp, _T(".jpeg")) == 0))
{
// reuse szImageFile
_stprintf_s(szImageFile, _T("%s\\%s"),
find_data.cFileName, image_find_data.cFileName);
image_files.emplace_back(szImageFile);
if (bHaveTrainImages == FALSE)
{
bHaveTrainImages = TRUE;
image_labels.emplace_back(find_data.cFileName);
}
}
} while (FindNextFile(hImgFind, &image_find_data));
FindClose(hImgFind);
} while (FindNextFile(hFind, &find_data));
FindClose(hFind);
if (image_files.size() > 0)
{
// generate the shuffle list to train
image_shuffle_set.resize(image_files.size());
for (size_t i = 0; i < image_files.size(); i++)
image_shuffle_set[i] = i;
std::random_device rd;
std::mt19937_64 g(rd());
std::shuffle(image_shuffle_set.begin(), image_shuffle_set.end(), g);
}
return hr;
}
图片转化为3x224x224张量
这里还是不使用opencv和PIL其他第三方库来处理图片,用标准Windows API将图像转化为tensor
HRESULT VGGNet::toTensor(const TCHAR* cszImageFile, torch::Tensor& tensor)
{
HRESULT hr = S_OK;
ComPtr<IWICBitmapDecoder> spDecoder; // Image decoder
ComPtr<IWICBitmapFrameDecode> spBitmapFrameDecode; // Decoded image
ComPtr<IWICBitmapSource> spConverter; // Converted image
ComPtr<IWICBitmap> spHandWrittenBitmap; // The original bitmap
ComPtr<ID2D1Bitmap> spD2D1Bitmap; // D2D1 bitmap
UINT uiFrameCount = 0;
UINT uiWidth = 0, uiHeight = 0;
WICPixelFormatGUID pixelFormat;
int nPredict = -1;
if (cszImageFile == NULL || _taccess(cszImageFile, 0) != 0)
return -1;
wchar_t* wszInputFile = NULL;
size_t cbFileName = _tcslen(cszImageFile);
#ifndef _UNICODE
wszInputFile = new wchar_t[cbFileName + 1];
if (MultiByteToWideChar(CP_UTF8, 0, cszCatImageFile, -1, wszInputFile, cbFileName + 1) == 0)
{
delete[] wszInputFile;
return -1;
}
#else
wszInputFile = (wchar_t*)cszImageFile;
#endif
// 加载图片, 并为其创建图像解码器
if (FAILED(m_spWICImageFactory->CreateDecoderFromFilename(wszInputFile, NULL,
GENERIC_READ, WICDecodeMetadataCacheOnDemand, &spDecoder)))
goto done;
// 得到多少帧图像在图片文件中,如果无可解帧,结束程序
if (FAILED(hr = spDecoder->GetFrameCount(&uiFrameCount)) || uiFrameCount == 0)
goto done;
// 得到第一帧图片
if (FAILED(hr = hr = spDecoder->GetFrame(0, &spBitmapFrameDecode)))
goto done;
// 得到图片大小
if (FAILED(hr = spBitmapFrameDecode->GetSize(&uiWidth, &uiHeight)))
goto done;
// 得到图片像素格式
if (FAILED(hr = spBitmapFrameDecode->GetPixelFormat(&pixelFormat)))
goto done;
// 如果图片不是Pre-multiplexed BGRA格式,转化成这个格式,以便用D2D硬件处理图形转换
if (!IsEqualGUID(pixelFormat, GUID_WICPixelFormat32bppPBGRA))
{
if (FAILED(hr = WICConvertBitmapSource(GUID_WICPixelFormat32bppPBGRA,
spBitmapFrameDecode.Get(), &spConverter)))
goto done;
}
else
spConverter = spBitmapFrameDecode;
// 转化为Pre-multiplexed BGRA格式的WICBitmap
if (FAILED(hr = m_spWICImageFactory->CreateBitmapFromSource(
spConverter.Get(), WICBitmapCacheOnDemand, &spHandWrittenBitmap)))
goto done;
// 将转化为Pre-multiplexed BGRA格式的WICBitmap的原始图片转换到D2D1Bitmap对象中来,以便后面的缩放处理
if (FAILED(hr = m_spRenderTarget->CreateBitmapFromWicBitmap(spHandWrittenBitmap.Get(), &spD2D1Bitmap)))
goto done;
// 将图片进行缩放处理,转化为28x28的图片
{
m_spRenderTarget->BeginDraw();
D2D1_RECT_F dst_rect = { 0, 0, VGG_INPUT_IMG_WIDTH, VGG_INPUT_IMG_HEIGHT };
m_spRenderTarget->FillRectangle(dst_rect, m_spBGBrush.Get());
// do the transform
FLOAT fN = uiWidth > uiHeight ? uiWidth : uiHeight;
FLOAT x1 = (fN - uiWidth) / 2.0f;
FLOAT y1 = (fN - uiHeight) / 2.0f;
FLOAT x2 = x1 + uiWidth;
FLOAT y2 = y1 + uiHeight;
FLOAT ratio_h = VGG_INPUT_IMG_HEIGHT / fN;
FLOAT ratio_w = VGG_INPUT_IMG_WIDTH / fN;
dst_rect.left = x1 * ratio_w;
dst_rect.right = x2 * ratio_w;
dst_rect.top = y1 * ratio_h;
dst_rect.bottom = y2 * ratio_h;
m_spRenderTarget->DrawBitmap(spD2D1Bitmap.Get(), &dst_rect);
m_spRenderTarget->EndDraw();
}
// 并将图像每个channel中数据转化为[-1.0, 1.0]的raw data
{
WICRect rect = { 0, 0, VGG_INPUT_IMG_WIDTH, VGG_INPUT_IMG_HEIGHT };
hr = m_spNetInputBitmap->CopyPixels(&rect, VGG_INPUT_IMG_WIDTH * 4,
4 * VGG_INPUT_IMG_WIDTH * VGG_INPUT_IMG_HEIGHT, m_pBGRABuf);
float* res_data = (float*)malloc(3 * VGG_INPUT_IMG_WIDTH * VGG_INPUT_IMG_HEIGHT * sizeof(float));
for (int c = 0; c < 3; c++)
{
for (int i = 0; i < VGG_INPUT_IMG_HEIGHT; i++)
{
for (int j = 0; j < VGG_INPUT_IMG_WIDTH; j++)
{
int pos = c * VGG_INPUT_IMG_WIDTH*VGG_INPUT_IMG_HEIGHT + i * VGG_INPUT_IMG_WIDTH + j;
res_data[pos] =
((255 - m_pBGRABuf[i * VGG_INPUT_IMG_WIDTH * 4 + j * 4 + 2 - c]) / 255.0f - 0.5f) / 0.5f;
}
}
}
tensor = torch::from_blob(res_data, { 1, 3, VGG_INPUT_IMG_WIDTH, VGG_INPUT_IMG_HEIGHT }, FreeBlob);
hr = S_OK;
}
done:
if (wszInputFile != NULL && wszInputFile != cszImageFile)
delete[] wszInputFile;
return hr;
}
训练网络
由于一轮训练时间太长,一般机器上3到10个小时,这里缺省只做了一轮训练,如果要更多轮训练,需修改参数kNumberOfEpochs ,取你需要训练的轮数。
int VGGNet::train(const TCHAR* szImageSetRootPath, const TCHAR* szTrainSetStateFilePath)
{
TCHAR szImageFile[MAX_PATH] = {0};
// store the file name classname/picture_file_name
std::vector<tstring> train_image_files;
std::vector<tstring> train_image_labels;
std::vector<size_t> train_image_shuffle_set;
auto tm_start = std::chrono::system_clock::now();
auto tm_end = tm_start;
if (FAILED(loadImageSet(szImageSetRootPath,
train_image_files, train_image_labels, train_image_shuffle_set, true)))
{
printf("Failed to load the train image/label set.\n");
return -1;
}
auto criterion = torch::nn::CrossEntropyLoss();
auto optimizer = torch::optim::SGD(parameters(), torch::optim::SGDOptions(0.001).momentum(0.9));
tm_end = std::chrono::system_clock::now();
printf("It takes %lld msec to prepare training classifying cats and dogs.\n",
std::chrono::duration_cast<std::chrono::milliseconds>(tm_end - tm_start).count());
tm_start = std::chrono::system_clock::now();
int64_t kNumberOfEpochs = 1;
torch::Tensor tensor_input;
for (int64_t epoch = 1; epoch <= kNumberOfEpochs; ++epoch)
{
auto running_loss = 0.;
// Take the image shuffle
for(size_t i = 0;i<train_image_shuffle_set.size();i++)
{
tstring& strImgFilePath = train_image_files[train_image_shuffle_set[i]];
const TCHAR* cszImgFilePath = strImgFilePath.c_str();
const TCHAR* pszTmp = _tcschr(cszImgFilePath, _T('\\'));
if (pszTmp == NULL)
continue;
size_t label = 0;
for (label = 0; label < train_image_labels.size(); label++)
if (_tcsnicmp(train_image_labels[label].c_str(),
cszImgFilePath, (pszTmp - cszImgFilePath) / sizeof(TCHAR)) == 0)
break;
if (label >= train_image_labels.size())
continue;
_stprintf_s(szImageFile, _T(CATDOG_IMAGE_TRAINSET_ROOT) _T("\\%s"), cszImgFilePath);
if (toTensor(szImageFile, tensor_input) != 0)
continue;
// Label在这里必须是一阶向量,里面元素必须是整数类型
torch::Tensor tensor_label = torch::tensor({ (int64_t)label });
optimizer.zero_grad();
// 喂数据给网络
auto outputs = forward(tensor_input);
//std::cout << outputs << '\n';
//std::cout << tensor_label << '\n';
// 通过交叉熵计算损失
auto loss = criterion(outputs, tensor_label);
// 反馈给网络,调整权重参数进一步优化
loss.backward();
optimizer.step();
running_loss += loss.item().toFloat();
if ((i + 1) % 100 == 0)
{
printf("[%lld, %5zu] loss: %.3f\n", epoch, i + 1, running_loss / 100);
running_loss = 0.;
}
}
}
printf("Finish training!\n");
tm_end = std::chrono::system_clock::now();
printf("It took %lld msec to finish training VGG network!\n",
std::chrono::duration_cast<std::chrono::milliseconds>(tm_end - tm_start).count());
m_image_labels = train_image_labels;
savenet(szTrainSetStateFilePath);
return 0;
}
使用本代码一轮训练下来,loss为0.7左右,有点高,识别率大概49%左右,有点偏低:(
验证和测试网络
最后一层中对应的soft-max, 在分类问题中,通常需要使用它的输出值进行操作,求出预测值索引。下面讲解一下torch::max()函数的输入及输出值都是什么
static inline std::tuple<Tensor,Tensor> max(
const Tensor & self,
int64_t dim,
bool keepdim=false)
输入
self是softmax函数输出的一个tensor
dim是max函数索引的维度0/1,0是每列的最大值,1是每行的最大值
void VGGNet::verify(const TCHAR* szImageSetRootPath, const TCHAR* szPreTrainSetStateFilePath)
{
TCHAR szImageFile[MAX_PATH] = { 0 };
// store the file name with the format 'classname/picture_file_name'
std::vector<tstring> test_image_files;
std::vector<tstring> test_image_labels;
std::vector<size_t> test_image_shuffle_set;
auto tm_start = std::chrono::system_clock::now();
auto tm_end = tm_start;
if (FAILED(loadImageSet(szImageSetRootPath,
test_image_files, test_image_labels, test_image_shuffle_set, false)))
{
printf("Failed to load the test image/label sets.\n");
return;
}
tm_end = std::chrono::system_clock::now();
printf("It took %lld msec to load the test images/labels set.\n",
std::chrono::duration_cast<std::chrono::milliseconds>(tm_end - tm_start).count());
tm_start = std::chrono::system_clock::now();
if (loadnet(szPreTrainSetStateFilePath) != 0)
{
printf("Failed to load the pre-trained VGG network.\n");
return;
}
tm_end = std::chrono::system_clock::now();
printf("It took %lld msec to load the pre-trained network state.\n",
std::chrono::duration_cast<std::chrono::milliseconds>(tm_end - tm_start).count());
tm_start = std::chrono::system_clock::now();
torch::Tensor tensor_input;
int total_test_items = 0, passed_test_items = 0;
for (size_t i = 0; i < test_image_shuffle_set.size(); i++)
{
tstring& strImgFilePath = test_image_files[test_image_shuffle_set[i]];
const TCHAR* cszImgFilePath = strImgFilePath.c_str();
const TCHAR* pszTmp = _tcschr(cszImgFilePath, _T('\\'));
if (pszTmp == NULL)
continue;
size_t label = 0;
for (label = 0; label < m_image_labels.size(); label++)
if (_tcsnicmp(m_image_labels[label].c_str(), cszImgFilePath,
(pszTmp - cszImgFilePath) / sizeof(TCHAR)) == 0)
break;
if (label >= m_image_labels.size())
{
tstring strUnmatchedLabel(cszImgFilePath, (pszTmp - cszImgFilePath) / sizeof(TCHAR));
_tprintf(_T("Can't find the test label: %s\n"), strUnmatchedLabel.c_str());
continue;
}
_stprintf_s(szImageFile, _T(CATDOG_IMAGE_TESTSET_ROOT) _T("\\%s"), cszImgFilePath);
if (toTensor(szImageFile, tensor_input) != 0)
continue;
// Label在这里必须是一阶向量,里面元素必须是整数类型
torch::Tensor tensor_label = torch::tensor({ (int64_t)label });
auto outputs = forward(tensor_input);
auto predicted = torch::max(outputs, 1);
_tprintf(_T("predicted: %s, fact: %s --> file: %s.\n"),
m_image_labels[std::get<1>(predicted).item<int>()].c_str(),
m_image_labels[tensor_label[0].item<int>()].c_str(), szImageFile);
if (tensor_label[0].item<int>() == std::get<1>(predicted).item<int>())
passed_test_items++;
total_test_items++;
//printf("label: %d.\n", labels[0].item<int>());
//printf("predicted label: %d.\n", std::get<1>(predicted).item<int>());
//std::cout << std::get<1>(predicted) << '\n';
//break;
}
tm_end = std::chrono::system_clock::now();
printf("Total test items: %d, passed test items: %d, pass rate: %.3f%%, cost %lld msec.\n",
total_test_items, passed_test_items, passed_test_items*100.f / total_test_items,
std::chrono::duration_cast<std::chrono::milliseconds>(tm_end - tm_start).count());
}
可运行工程和训练集
我已经上传代码和工程到VGG@GitHub
下面是具体用法
Usage:
VGGNet [command] [train/test image set] [train_net_state_filename] [testimagefile]
commands:
state: Print the VGG layout
train: Train the VGG16
verify: Verify the train network with the test set
classify: Classify the input image
examples:
VGGNet state
VGGNet train I:\CatDog I:\catdog.pt
VGGNet verify I:\CatDog I:\catdog.pt
VGGNet classify I:\catdog.pt I:\test.png
打印网络状态
VGGNet state
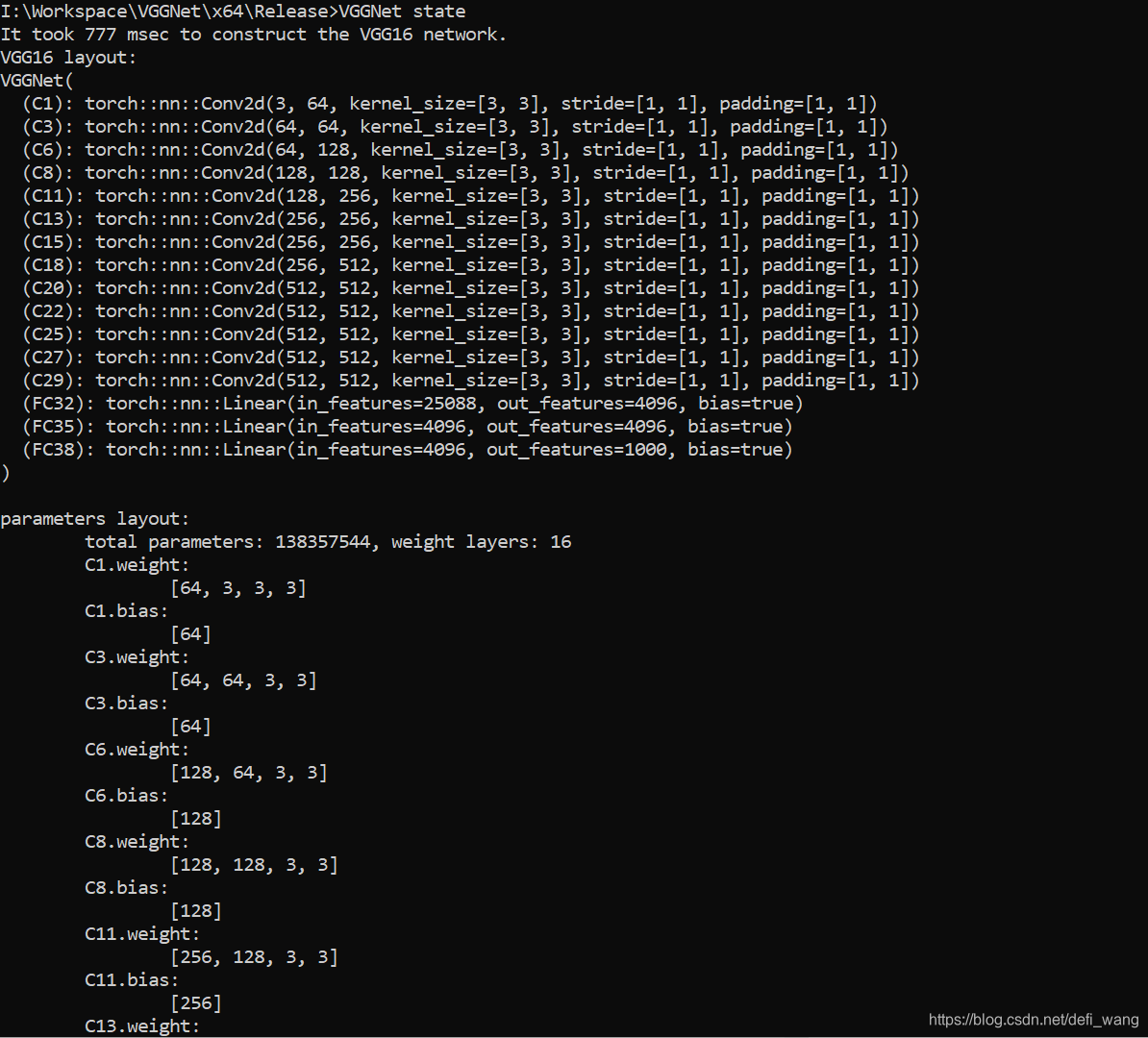
训练网络
VGGNet train 训练集目录 输出训练网络状态文件
VGGNet.exe train C:\VGG\CatsDogs C:\VGG\catdog.pt
验证网络
VGGNet verify 训练集目录 预训练网络状态文件
VGGnet verify C:\VGG\CatsDogs\ C:\VGG\catdog.pt
图片分类
VGGNet classify 预训练网络状态文件 图片文件路径
VGGnet Classify C:\VGG\catdog.pt C:\VGG\CatsDogs\test_set\dogs\dog.4008.jpg

















 3799
3799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









