




- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标:
搭建CNN网络模型实现多云、下雨、晴、日出四种天气状态的识别,并用真实天气做预测
具体实现:
(一)环境:
语言环境:Python 3.10
编 译 器: PyCharm
框 架: Tensorflow
**(二)具体步骤:
1. 使用GPU
之前的GPU一直没检测出来 ,今天参考windows安装tensorflow-gpu / CUDA / cuDNN - 前端大兵 - 博客园和 Build from source on Windows | TensorFlow,主要的就是保证python版本、cuda版本, cuDNN以及Tensorflow版本一致。我的Python版本是3.8,cuda安装的是11.2,查看如下:
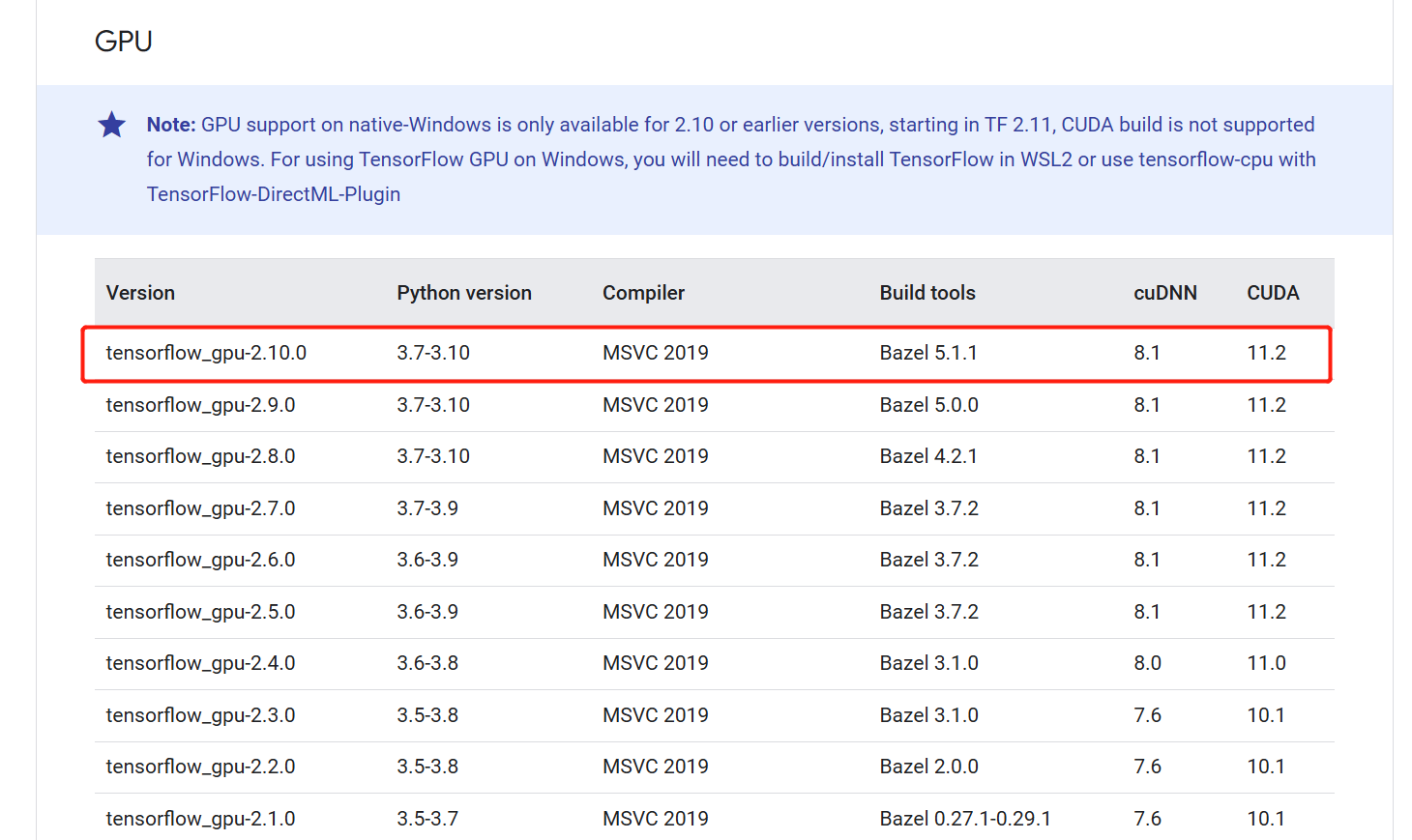
那么cudnn和tensowflow-gpu的版本也找到了,直接下载安装就成。看成果:
import os
import PIL
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:
gpu0 = gpus[0]
# print(gpu0)
tf.config.experimental.set_memory_growth(gpu0, True)
tf.config.set_visible_devices([gpu0], "GPU")

解决。
2.查看数据
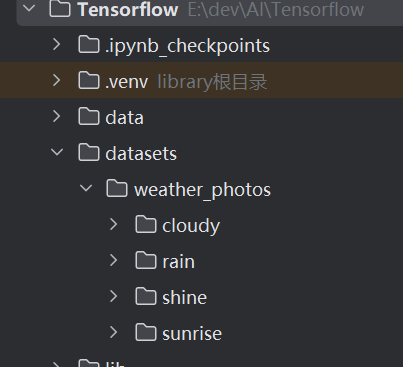
在工程根目录下创建了一个datasets目录,然后下面有一个weather_photos的子目录,再下面分为cloudy(多云)、rain(雨天)、shine(晴天)和sunrise(日出)4种天气类型。
# 导入数据集
data_dir = "datasets/weather_photos/"
data_dir = pathlib.Path(data_dir) # 将目录转换成pathlib.Path类对象,以便使用Path的各种方法
print(data_dir)
# 查看数据
# 查看目录下所在.jpg文件的数据。glob方法是按.jpg去匹配所有文件。要能够使用glob方法,需要上当是pathlib.Path类的对象。
image_count = len(list(data_dir.glob('*/*.jpg')))
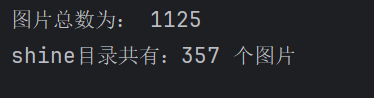
print("图片总数为:", image_count)
# 看一下shine目录下的图片
shine = list(data_dir.glob('sunrise/*.jpg'))
print("shine目录共有:%d 个图片" % len(shine))
im = PIL.Image.open(str(shine[0]))
im.show()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3461
3461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









