









咱们再前两期已经对孟德尔随机化进行了一个初步的介绍,孟德尔随机化步骤相对简单固定,一共就是3步,但是如果我们一个一个的对研究变量和结果数据进行筛选,也是挺费时间的,我随手写了一个R的小程序可以帮助咱们进行数据挖掘。
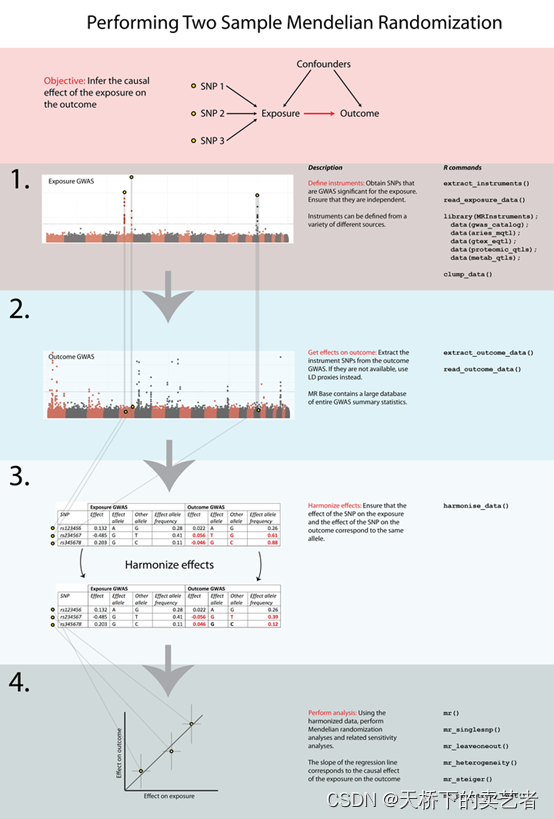
其实就是一个很简单的小程序,主要是对孟德尔随机化的步骤进行了打包,利用双循环对研究变量和结果变量进行匹配。函数体为
Mendelian.help (exposure,outcome)
Exposure就是我们的研究变量,outcome就是我们的结果变量。
假设我们研究的想研究的原因变量有两个"ieu-a-22",“prot-b-66”,想研究的结局变量有3个"finn-b-O15_MEMBR_PREMAT_RUPT",“ukb-b-12621”,“finn-b-O15_PLAC_PREMAT_SEPAR”,如果我们一个一个的做也是要花费一定时间的,如果变量更多就需要更多时间了。
我们先定义暴露变量和结果变量
exposure<-c("ieu-a-22","prot-b-66")
outcome<-c("finn-b-O15_MEMBR_PREMAT_RUPT","ukb-b-12621","finn-b-O15_PLAC_PREMAT_SEPAR")
然后生成结果,非常简单吧。
out<-Mendelian.help(exposure=exposure,outcome=outcome)
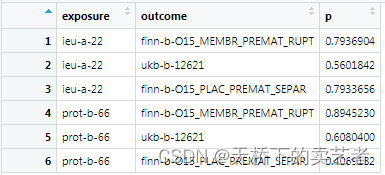
这样就结果就生成啦,我们可以看到每个暴露变量和结果变量匹配的情况,看出有没有意义,对于大规模变量的筛选我个人认为还是有帮助的。P值的筛选是通过孟德尔随机化P值中最要的方法Inverse variance weighted提取出的P值。

然而这个函数也是有部分缺点的,第一就是它是通过在线下载数据,如果你的网络不行,下载不到数据,它就会报错,所以因在网络比较好的时候进行(如白天)。如下图就是下载不到数据

第二就是如果你第一步提取的SNP数据过少只有1-2个的话,在第二步有可能匹配不上,也会报错。
最后,虽然这是一个非常简单的小程序,没有什么技术含量,但是也是有构思在里面的,不能免费贴出来烂大街,需要的公众号回复:代码,可以获得该程序。
















 3837
3837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











