







本教程教你怎么使用工具训练数据集推理出你想要转换的声音音频,并且教你处理剪辑伴奏和训练后的音频合并一起,在文章的最后有用我自己声音处理的歌曲,哎哟,还怪不好意思的~,哈哈,快来试试看把!
DDSP-SVC3.0训练推理克隆声音,超物有所值,训练完毕有伴奏处理教程哦
1.使用的工具
要想训练ai声音,首先需要有各种工具,还需要我们提供你需要训练的声音,当然声音需要没有噪音存干声,如果要是歌曲就需要分离歌曲的背景和声音,然后将音频文件切分,切分的目的是为了保证训练不卡,否则音频文件太大,所以你知道我们需要什么工具了把!以下揭晓
Adobe Audition :我主要用这个提取mp4的音频文件,后期可以用这个剪辑将伴奏和音频合起来
UVR5:这个是专门背景与人生分离的软件,一键安装就可以
Audio Slicer(音频切分):这个可以不用专门下软件自己操作了,大神在webui里集成了,按一下自动切分。
DDSP-SVC-3.0:最重要的工具,启动后是个webui界面,然后呢我们需要在里边训练自己的声音,转换声音等操作。
整合包使用b站大佬羽毛布团提供的包-地址: https://pan.baidu.com/s/1DWqVpJ7b6ueoUv6h4yF1-A?pwd=ddsp
处理音频的工具可以去羽毛布团的这个整合包下载,注意不要下载so-svc文件哦: https://pan.baidu.com/s/12u_LDyb5KSOfvjJ9LVwCIQ?pwd=g8n4
2.素材准备
2.1 AU提取音频
将mp4提取音频文件,用AU操作,操作如下:
我是要把我在bilibili录制的视频下载下来的,需要借助bilibili的一些工具才能下载下来视频,我用的是这个在线解析bilibili视频的还是蛮方便的,链接在这里。
然后得到的视频可以拖到如下的位置,
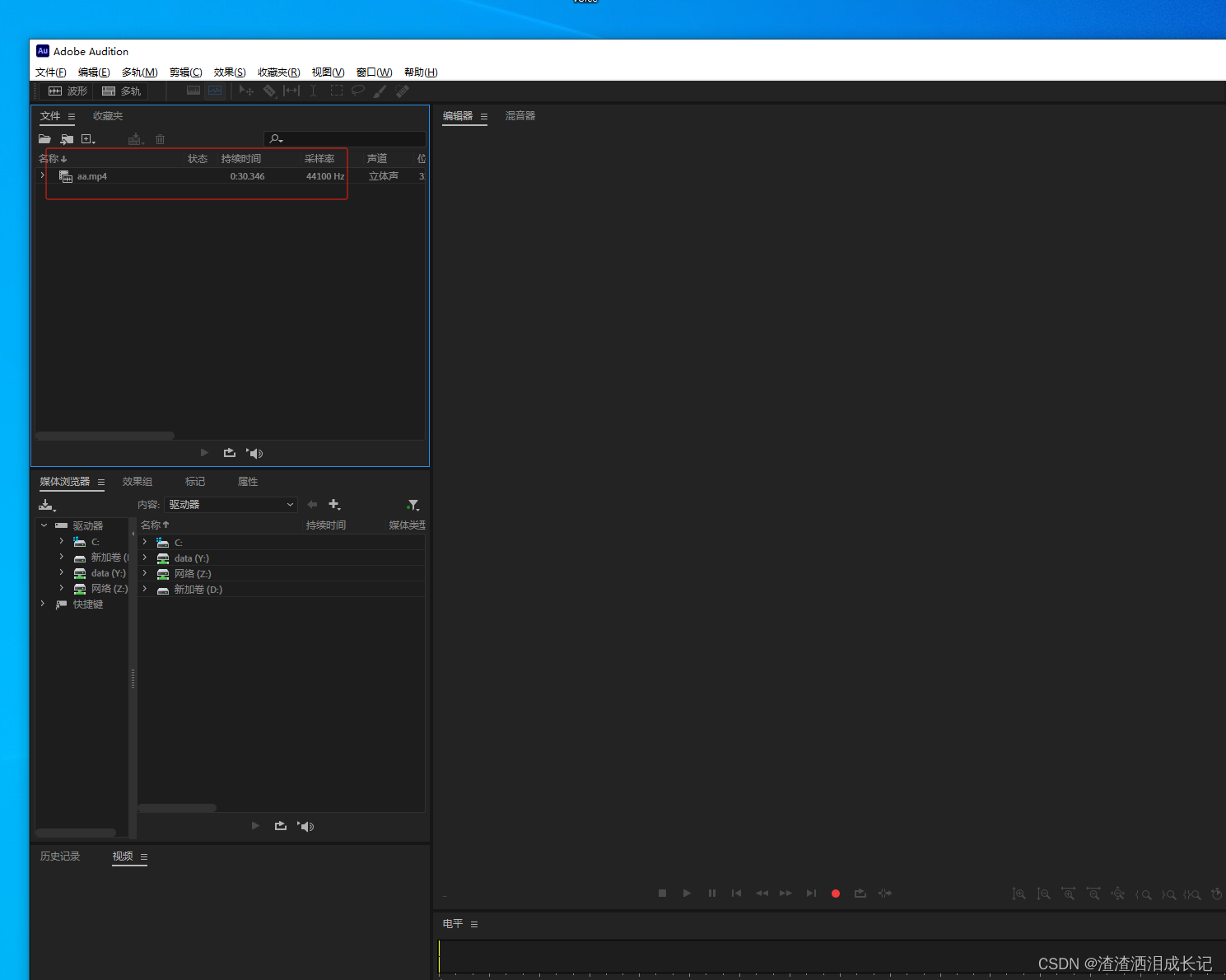
然后点击这个文件右键将音频提取到文件,然后点击新出的音频文件再点击最上面的菜单文件保存或另存为然后就得到音频文件了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









