






以下收录暂时看不懂得,等翻阅了文献再来补充。
http://deeplearning.stanford.edu/wiki/index.php/反向传导算法
1、[注:通常权重衰减的计算并不使用偏置项 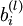 ,比如我们在
,比如我们在 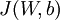 的定义中就没有使用。一般来说,将偏置项包含在权重衰减项中只会对最终的神经网络产生很小的影响。如果你在斯坦福选修过CS229(机器学习)课程,或者 在YouTube上看过课程视频,你会发现这个权重衰减实际上是课上提到的贝叶斯规则化方法的变种。在贝叶斯规则化方法中,我们将高斯先验概率引入到参数 中计算MAP(极大后验)估计(而不是极大似然估计)。]
的定义中就没有使用。一般来说,将偏置项包含在权重衰减项中只会对最终的神经网络产生很小的影响。如果你在斯坦福选修过CS229(机器学习)课程,或者 在YouTube上看过课程视频,你会发现这个权重衰减实际上是课上提到的贝叶斯规则化方法的变种。在贝叶斯规则化方法中,我们将高斯先验概率引入到参数 中计算MAP(极大后验)估计(而不是极大似然估计)。]
2、我们的目标是针对参数 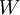 和
和 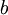 来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数
来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数 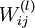 和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布
和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布 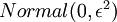 生成的随机值,其中
生成的随机值,其中 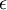 设置为
设置为 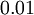 ),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为
),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为 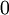 。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有
。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有  ,
,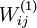 都会取相同的值,那么对于任何输入
都会取相同的值,那么对于任何输入  都会有:
都会有: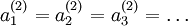 )。随机初始化的目的是使对称失效。
)。随机初始化的目的是使对称失效。
http://deeplearning.stanford.edu/wiki/index.php/梯度检验与高级优化
1、迄今为止,我们的讨论都集中在使用梯度下降法来最小化 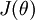 。如果你已经实现了一个计算 和
。如果你已经实现了一个计算 和 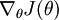 的函数,那么其实还有更精妙的算法来最小化 。举例来说,可以想象这样一个算法:它使用梯度下降,并能够自动调整学习速率
的函数,那么其实还有更精妙的算法来最小化 。举例来说,可以想象这样一个算法:它使用梯度下降,并能够自动调整学习速率 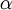 ,以得到合适的步长值,最终使
,以得到合适的步长值,最终使 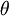 能够快速收敛到一个局部最优解。还有更妙的算法:比如可以寻找一个Hessian矩阵的近似,得到最佳步长值,使用该步长值能够更快地收敛到局部最优(和 牛顿法类似)。此类算法的详细讨论已超出了这份讲义的范围,但是L-BFGS算法我们以后会有论述(另一个例子是共轭梯度算法)。你将在编程练习里使用这 些算法中的一个。使用这些高级优化算法时,你需要提供关键的函数:即对于任一个 ,需要你计算出 和 。之后,这些优化算法会自动调整学习速率/步长值 的大小(并计算Hessian近似矩阵等等)来自动寻找 最小化时 的值。诸如L-BFGS和共轭梯度算法通常比梯度下降法快很多。
能够快速收敛到一个局部最优解。还有更妙的算法:比如可以寻找一个Hessian矩阵的近似,得到最佳步长值,使用该步长值能够更快地收敛到局部最优(和 牛顿法类似)。此类算法的详细讨论已超出了这份讲义的范围,但是L-BFGS算法我们以后会有论述(另一个例子是共轭梯度算法)。你将在编程练习里使用这 些算法中的一个。使用这些高级优化算法时,你需要提供关键的函数:即对于任一个 ,需要你计算出 和 。之后,这些优化算法会自动调整学习速率/步长值 的大小(并计算Hessian近似矩阵等等)来自动寻找 最小化时 的值。诸如L-BFGS和共轭梯度算法通常比梯度下降法快很多。














 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









