







各位同学好,今天和大家分享一下YOLOV1目标检测的原理。
1. 预测阶段--前向传播
预测阶段就是在模型已经成功训练之后,输入未知图片,对图片预测。此时只需要前向传播运行这个模型。
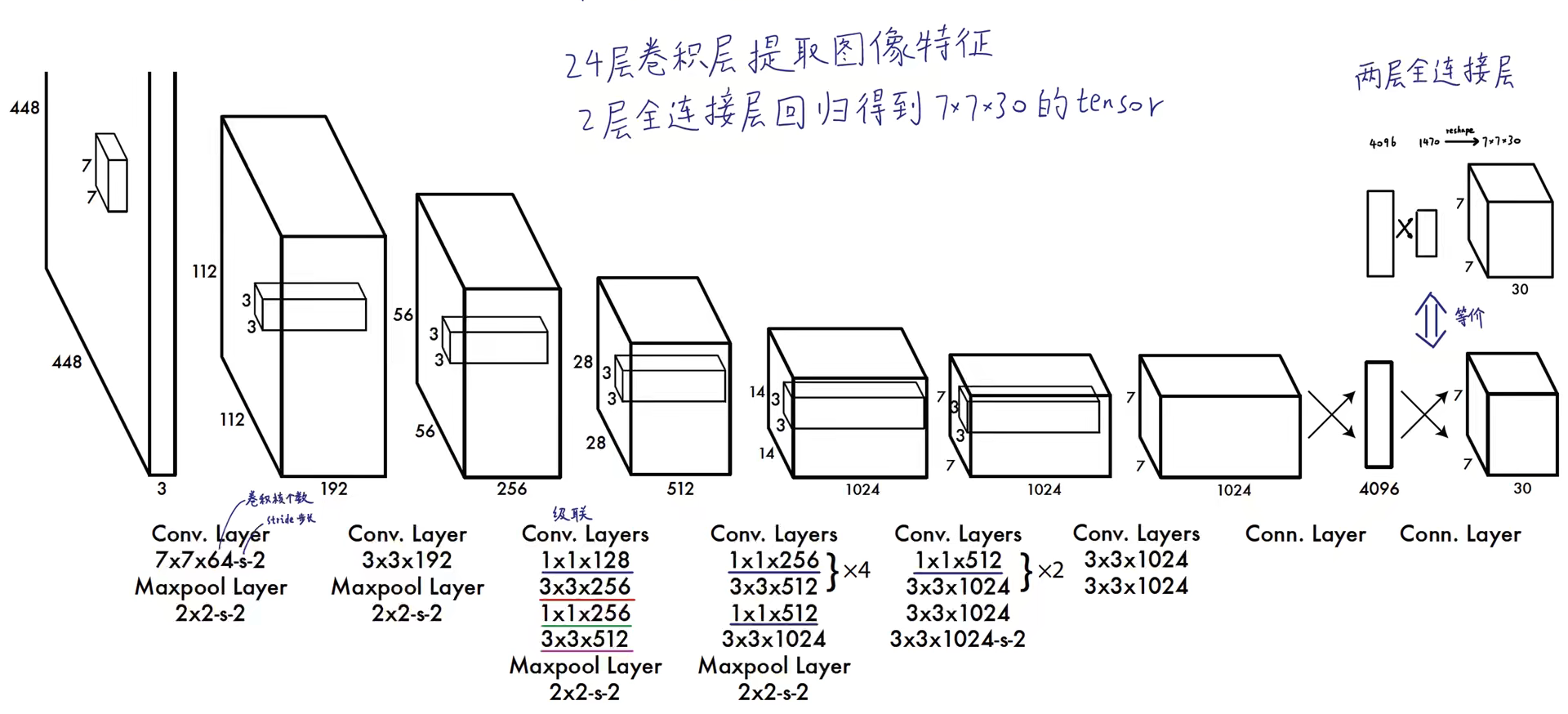
流程如下图,模型输入图像的shape为 [448,448,3],经过若干个卷积层和池化层,输出特征图的shape为 [7,7,1024];再将这个特征图拉平放到有4096个神经元的全连接层中,输出 4096 维的向量;再将该向量输入至 1470 个的神经元的全连接层中,输出 1470 维的向量;最后将该向量reshape成 [7,7,30] 的特征图。
在预测阶段,YOLOV1模型相当于一个黑箱子,输入 [448,448,3] 的图像,输出 [7,7,30] 的特征图。输出的 tensor 中包含了所有预测框的坐标,置信度,类别结果
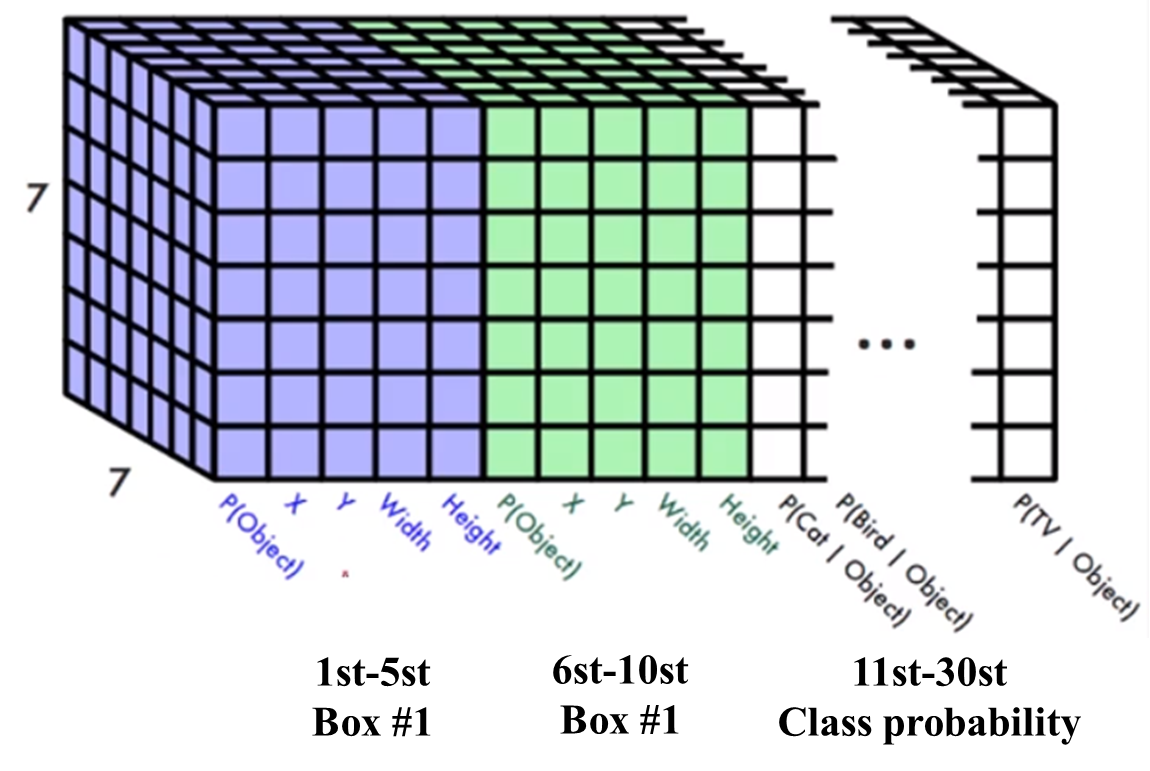
输出特征图的shape是 [7,7,30] 可以理解为:
(1)首先,网络将图像划分成 SxS 个网格(grid cell),在YOLOv1中S=7,因此每张图像都划分成 7x7 的网格。
(2)每个网格(grid cell)能预测出 b 个预测框(bounding box),在YOLOv1中b=2,每个网格能预测出2个预测框。这个两个预测框可能大小形状差别很大,只要预测框的中心点落在该网格中,就说明这个检测框是由该网格生成的。所以每个网格生成的两个预测框的中心点肯定落在该网格中。
(3)每个预测框包含中心点坐标(x, y),宽高(w, h)这四个定位坐标确定预测框的位置;包含预测框中的物体是不是目标物体的置信度 c;包含所有类别的条件概率,假设在预测框已经包含目标物体的情况下,该物体是某一个类别的概率。如:在包含目标物体的情况下是狗的概率。
(4)将每个预测框的置信度乘以类别的条件概率,就能获得每个预测框属于各个类别的概率。
(5)输出特征图的通道数是30,可以理解为,每个网格生成2个预测框,每个预测框包含5各参数(x, y, w, h, c),那么两个预测框就有10个参数,在VOC数据集中包含20个类别,即每个网格包含这20个类别的条件概率。
因此,每个网格包含5+5+20个参数,每张图片被划分成7x7的网格,一张图片有7x7x30个参数
如下面左图,每个网格预测出两个预测框,预测框的置信度高的用粗线表示,置信度低的用细线表示,保留下置信度高的预测框。
每个网格还能生成20个类别的条件概率,如右图,展示了条件概率高的类别所占有的网格。如绿色代表狗的条件概率较高的区域。每个网格只有一个类别,选择20个条件概率中最高的那一个类别。
每一网格只能识别一个目标物体,7x7的网格最多能预测出49个物体,这也是YOLOv1在小目标和密集目标识别性能差的原因

2. 预测阶段--后处理
将纷繁复杂的预测出的98个预测框筛选过滤(NMS非极大值抑制),去除低置信度的预测框,重复的预测框只保留一个,获得最终目标检测的结果。
后处理就是将网络输出的 7x7x30 的特征图变成最后的目标检测结果

从 7x7 个网格中取出一个网格来研究,首先如第一节所述,每个网格包含2个预测框参数(x,y,w,h,c)和20个类别的条件概率(假设预测框包含目标物体,它是某个类别的概率),即5+5+20个参数

接下来,将每个预测框的置信度和每个网格属于20个类别的条件概率相乘,得到网格真正属于某个类别的概率。第一个预测框的置信度乘以20个类别的条件概率,得到第一个预测框属于20个类别的全概率。一个20维的向量,代表一个预测框属于每个类别的概率。
那么每个网格就有2个概率向量,每个向量有20个元素。7x7个网格就有98个向量

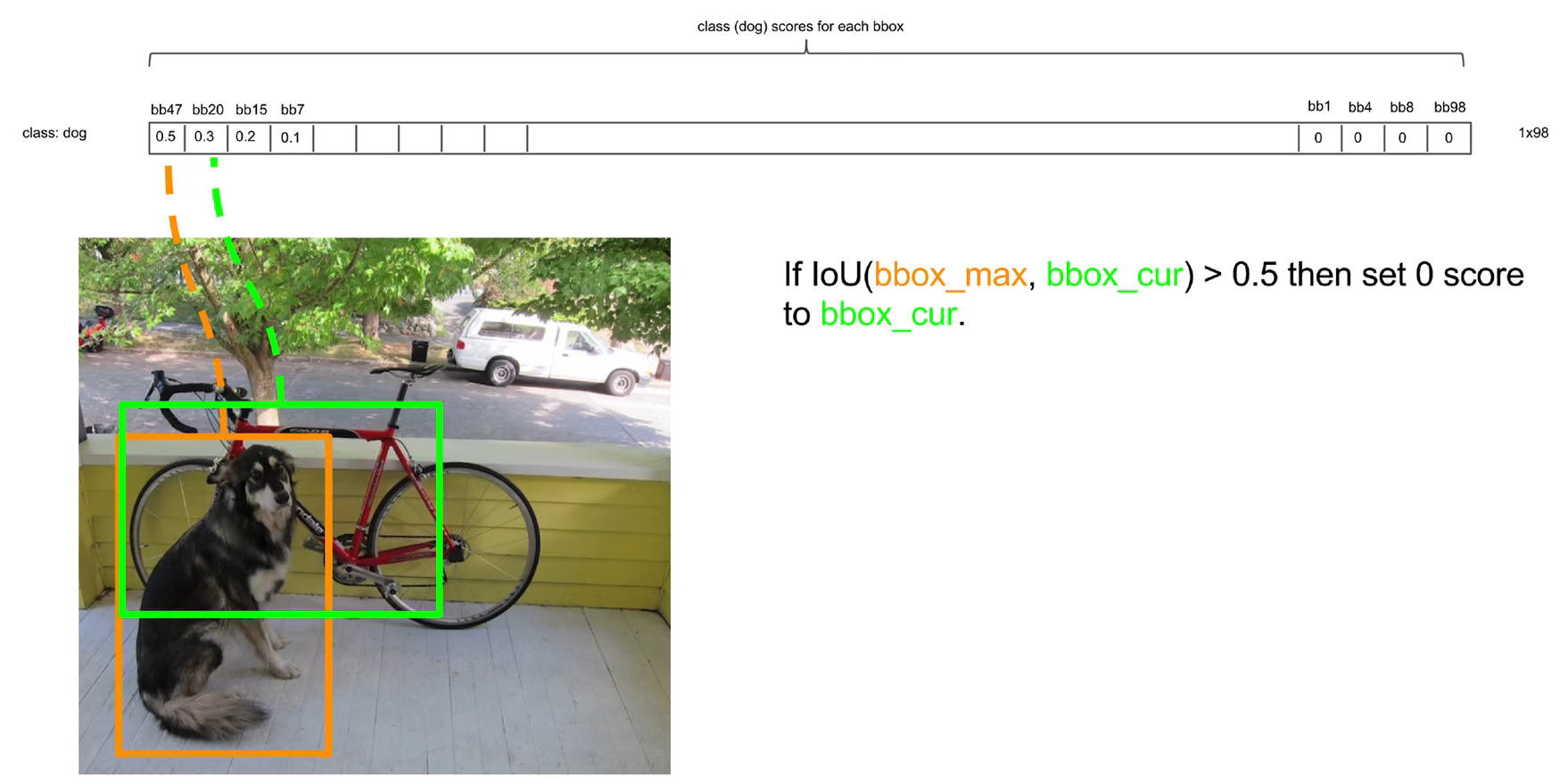
现在获得了98个概率向量,以狗这个类别为例,某些预测框计算出的狗这个类别的概率很小,现在设置一个阈值如0.2,将所有检测框预测狗的概率小于0.2的概率值全部变成0,然后按照狗类别的概率值高低排序所有的预测框。

对排序后的预测框使用非极大值抑制NMS
先把概率值最大的预测框拿出来,然后把剩下的预测框逐一和概率最大的预测框比较,如果两个框的IOU(交并比)大于某个阈值,就认为这两个检测框重复识别了同一个目标物体,把低概率的预测框过滤掉。把交并比满足要求的预测框保留下来
如下图,橘色预测框和绿色预测框的交并比大于0.5,表明两个框预测了同一个目标物体,将概率小的绿框的概率值变成0
接下来再把概率值第二高的预测框拿出来,和剩下的预测框逐一计算交并比。蓝框和紫框的交并比超过阈值,表示重合,概率值小的紫框的概率值置为0。同理依次对所有预测框比较。
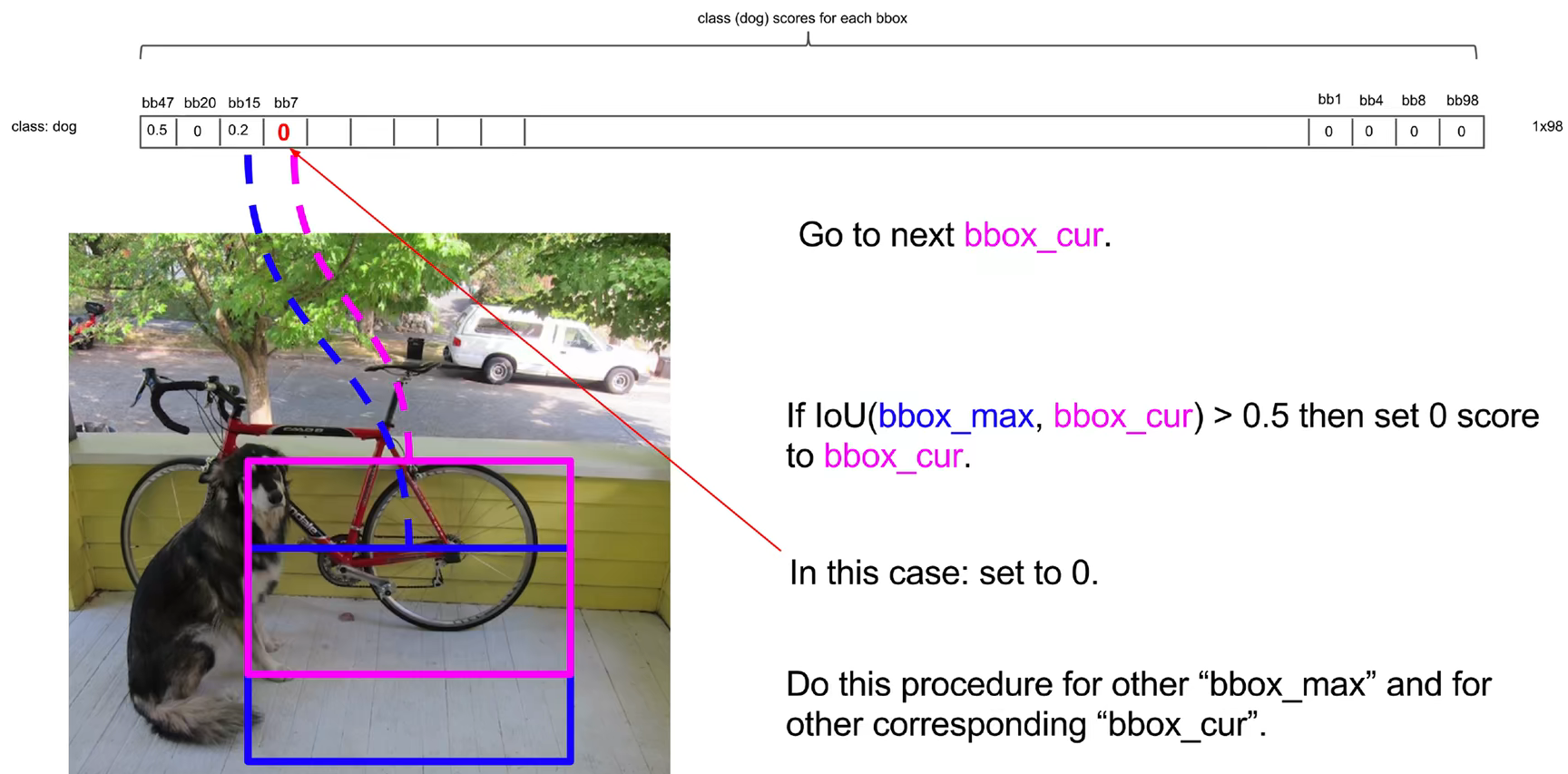
最终比较完剩下橘框和蓝框预测结果是狗被保留下来,然后分别对这20个类别使用NMS,最终的计算结果一个稀疏矩阵,有很多元素被置为0。将98个预测框中概率值不为0的框找出来,找到类别索引和概率值,就能获得最终的目标检测结果。
3. 训练阶段
监督学习的训练是通过梯度下降和方向传播方法,迭代微调神经元的权重,使得损失函数最小化。
目标检测是一个典型的监督学习问题,在训练集上已经人工画出了真实目标的检测框,而算法要使得预测框尽量去拟合真实检测框。
真实检测框的中心点落在哪个网格中,就需要哪个网格生成的预测框去拟合真实的检测框。每个网格生成两个预测框,那么就需要这两个预测框中的一个框去拟合真实检测框。并且这个网格输出的类别也必须是该真实检测框的类别。
如下图,蓝色实线框是真实检测框,中心点落在红色网格中,该网格生成了两个预测框,黄色和橘色虚线框。预测框和真实框的IOU交并比大的预测框负责拟合真实框,下图就是黄色虚线框来拟合真实框。调整预测框尽量逼近真实框的样子。让交并比小的预测框的置信度越小越好。

损失函数
损失函数包含五项,都是回归问题的损失函数,预测出一个连续的值,将该值和标注值比较,越接近越好。
(1)第一个是负责检测物体的预测框的中心点定位误差。预测框和真实框在横纵坐标上尽可能的一致。
(2)第二项是负责检测物体的预测框的宽高定位误差。预测框的宽高要和真实框的宽高尽可能一致,求根号能使小框对误差更敏感。
(3)第三项是负责检测物体的预测框的置信度误差。标签值是预测框和真实框的IOU交并比,预测值需要和标签值越接近越好。
(4)第四项是不负责检测物体的预测框的置信度误差。所有不用来拟合真实框的预测框的标签值IOU最好都等于0
(5)第五项是负责检测物体物体的网格的分类误差。若某个网格负责预测狗,那么这个网格在20个类别中狗这个类别的概率越接近于1越好。

代表第 i 个网格是否包含物体,即真实框的中心点是否落在该网格中。若有则为1,否则为0
代表第 i 个网格的第 j 个预测框,若负责预测物体则为1,否则为0
代表第 i 个网格的第 j 个预测框,若不负责预测物体则为1,否则为0
代表给真正负责检测物体的预测框的误差给予更多的权重
代表给不负责检测物体的预测框的误差给予很小的权重

















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











