









 本文探讨了iCaRL算法,一种针对图像分类网络的增量学习策略,旨在防止灾难性遗忘,通过微调网络并结合旧数据样例,实现新旧知识的平衡学习。
本文探讨了iCaRL算法,一种针对图像分类网络的增量学习策略,旨在防止灾难性遗忘,通过微调网络并结合旧数据样例,实现新旧知识的平衡学习。
前言
我将看过的增量学习论文建了一个github库,方便各位阅读,地址
什么是增量学习
增量学习是指一个学习系统能不断地从新样本中学习新的知识,并能保存大部分以前已经学习到的知识,就和人类学习知识一样,学习完新知识后,我们仍然记得旧知识
增量学习存在的问题
灾难性遗忘(catastrophic forgetting)
神经网络在新数据上训练后,权重发生变化,导致神经网络遗忘旧数据上学习到的规律,类似于背英语单词,背了新的忘了旧的
克服灾难性遗忘的策略
策略一
冻结当前神经网络的部分权重,并且增加神经网络的深度,让神经网络能够保留学习新知识的能力。
以下为个人对策略一的理解
浅层神经网络会保留旧数据上学习的知识,而深层神经网络则在旧知识的基础上继续学习新知识,假设利用残差结构连接深层网络的输出与浅层网络的输出,对于旧知识,只需要让深层网络的输出近似于0即可完全保留旧知识,这和残差结构的出发点类似。
策略二
利用旧数据与新数据对网络进行训练。
以下为个人对策略二的理解
策略二更像是一种微调,如果仅仅利用新数据训练网络,那么网络的确很有可能遗忘旧知识,提供旧数据有助于网络在学习新知识的前提下抵抗遗忘。
论文主要工作
针对图像分类网络的增量学习,即让网络在保留旧类别区分能力的基础上,区分新类别,提出了一种名为iCaRL的训练策略,该算法可以让分类器(例如softmax分类器)与特征提取器(例如CNN)同时学习。
论文提出的训练策略并不针对某个CNN框架,因此可以自由选择CNN框架。另外,CNN框架的不同并不能解决灾难性遗忘。
网络架构细节
可以自由选择CNN架构,CNN架构之后接一个激活函数为 s i g m o i d sigmoid sigmoid的全连接层 L L L,作为分类器,全连接层的输入(特征向量),均进行了 L 2 L2 L2归一化,L2归一化有助于网络收敛。使用多标签分类损失函数,多标签分类损失函数其实就是极大似然估计,具体可查看我是链接。
算法介绍
名词解释
- e x a m p l a r examplar examplar:可以看成一个容器,一个 e x a m p l a r examplar examplar保存了某一类的部分训练数据
- K K K:K即为存储训练数据的上限,假设目前有 m m m类,那么每一个 e x a m p l a r examplar examplar可以存储的训练数据为 K m \frac{K}{m} mK。
总体流程
iCaRL算法的总体流程如下:

每个函数的具体解释如下:
u
p
d
a
t
e
r
e
p
r
e
s
e
n
t
a
t
i
o
n
updaterepresentation
updaterepresentation函数:用于更新CNN与全连接层分类器的参数。
r
e
d
u
c
e
e
x
e
m
p
l
a
r
s
e
t
reduceexemplarset
reduceexemplarset函数:用于减少旧类的
e
x
a
m
p
l
a
r
examplar
examplar的容量。
c
o
n
s
t
r
u
c
t
e
x
e
m
p
l
a
r
s
e
t
constructexemplarset
constructexemplarset函数:用于构造新类的
e
x
a
m
p
l
a
r
examplar
examplar。
整个算法的流程总结一下,即为:
- 添加新类别数据后,训练CNN与全连接层分类器
- 减少旧类别的 e x a m p l a r examplar examplar的容量,去除部分训练数据
- 构造新类别的 e x a m p l a r examplar examplar,存储部分新类别的训练数据
e x a m p l a r examplar examplar存储数据会用于模型的训练,帮助模型抵抗遗忘
步骤一:模型训练
由
u
p
d
a
t
e
r
e
p
r
e
s
e
n
t
a
t
i
o
n
updaterepresentation
updaterepresentation函数实现

该函数需要的参数为
- 新类别数据
- e x a m p l a r examplar examplar集合
- CNN与全连接层分类器
具体步骤如下:
- 合并 e x a m p l a r examplar examplar集合以及新类别数据集,构造训练数据集
- 存储训练前,模型对于训练数据的预测结果(迷之操作, g ( x i ) g(x_i) g(xi)表示CNN+全连接层分类器的输出向量, g y ( x i ) g_y(x_i) gy(xi)表示输出向量的第 y y y维的值)
- 训练模型
损失函数使用多标签分类损失函数,分为分类以及蒸馏两部分,按步骤来说
- 从旧模型上得到新数据的分类标签,该类标签可以提供一种更强的监督信号,表明与新旧类别相似的类别
- 新模型对应的one-hot标签的旧类别部分替换为步骤一的结果
对于旧类别而言,步骤一的标签可以提供更强的监督信号,来弥补数据不足导致的监督信号缺失。
步骤二: e x a m p l a r examplar examplar管理
训练完模型后,需要对 e x a m p l a r examplar examplar集合进行调整, e x a m p l a r examplar examplar集合的作用有两个
- 帮助模型抵抗遗忘(上面已经介绍)
- 预测分类(在模型预测模块介绍)
e x a m p l a r examplar examplar的管理由 r e d u c e e x e m p l a r s e t reduceexemplarset reduceexemplarset函数与 c o n s t r u c t e x e m p l a r s e t constructexemplarset constructexemplarset函数实现。
c o n s t r u c t e x e m p l a r s e t constructexemplarset constructexemplarset函数

采样的标准:每次选择离训练数据类别中心最接近的图像样本,这和之后的分类有关。
按照采样的先后顺序构建新类别的
e
x
a
m
p
l
a
r
examplar
examplar(即
P
P
P),在
P
P
P中越靠前位置的样本组成的集合,离类别中心越接近
r e d u c e e x e m p l a r s e t reduceexemplarset reduceexemplarset函数

e
x
a
m
p
l
a
r
examplar
examplar中的样本要遵循的原则——样本集合的中心尽可能的接近类别集合,依据进入
e
x
a
m
p
l
a
r
examplar
examplar的顺序,靠前位置样本组成的集合,比靠后位置样本组成的集合,离类别中心更接近,因此,每次都去除尾部一定数量的样本,让
e
x
a
m
p
l
a
r
examplar
examplar的大小不超过
K
m
\frac{K}{m}
mK,
K
K
K为存储空间上限,
m
m
m为当前类别数。
模型预测
常见的神经网络分类模型,都是分类器(例如softmax分类器)与特征提取器(例如CNN)一起学习,但是iCaRL将分类器与特征提取器分开,只有特征提取器进行学习,分类器则选择了不需训练的最近邻分类器,这点有点反直觉,分类过程如下:

由于使用最近邻分类器,所以
e
x
a
m
p
l
a
r
examplar
examplar中,A类别的样本集合中心应该尽可能接近A类别训练数据的中心,这也是构建
e
x
a
m
p
l
a
r
examplar
examplar的出发点。
实验
与其他方法的比较
论文选取了三个baseline
- Finetuning:在之前学习的基础上添加一个新的类别分支,利用新数据微调网络
- Fixed representation:第一次增量学习训练完毕后,冻结特征提取器的权重,只会训练分类器新分支的权重,新分支训练完毕后,冻结新分支的权重
- Learning without Forgetting模型
iCaRL与上述三个baseline都使用相同的CNN(ResNet),一次增量学习即让学习器多学习 N N N类,论文比对了N=2,5,10,20,50的情况,论文在CIFAR100以及ImageNet数据集上比对了这几个方法
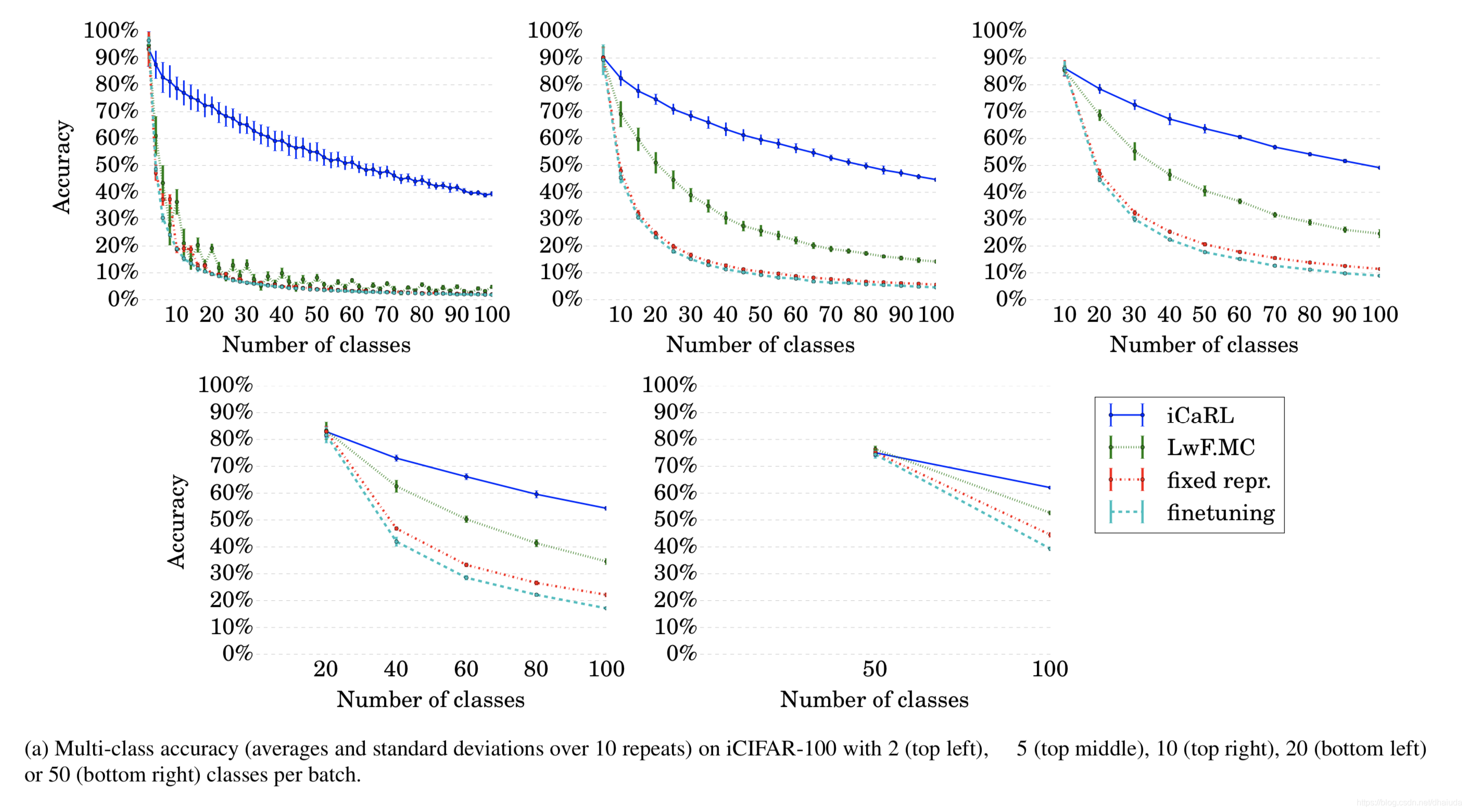
CIFAR-100数据集的结果如下:
在ImageNet数据集的结果如下:
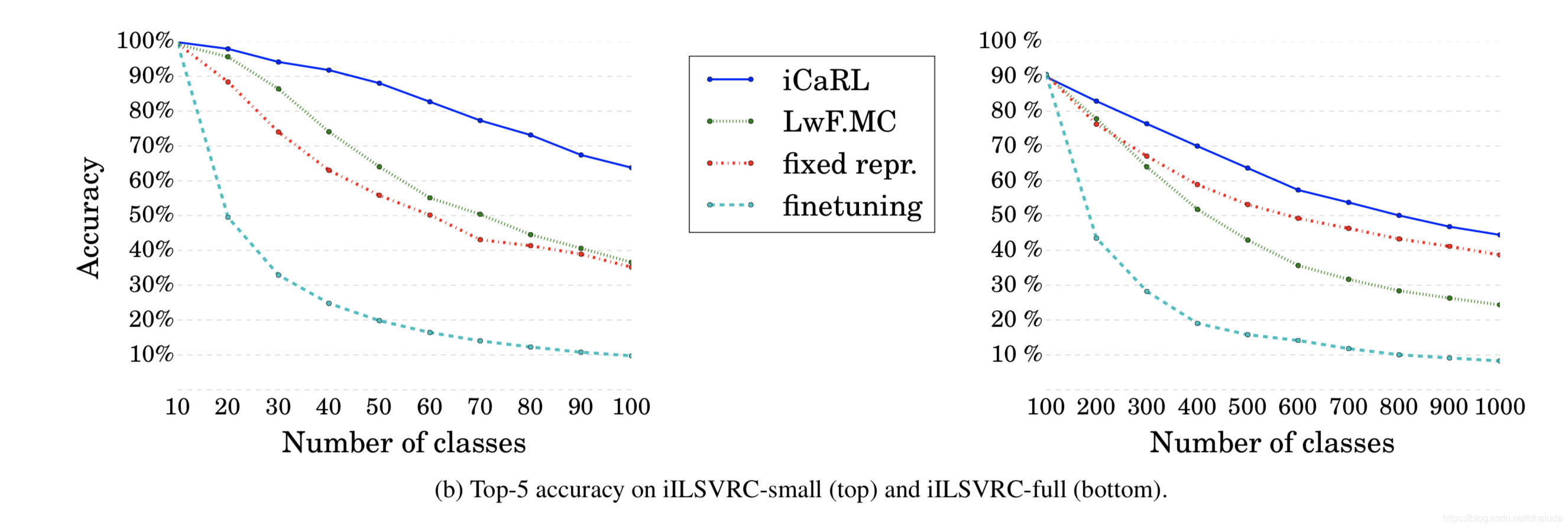
学习次数的越多,网络的性能表现越糟糕,这在一定程度上表明模型存在遗忘现象,从上图可知,iCaRL训练的网络,性能最号,但是无法判断相比于baseline,iCaRL是否可以更好的抵抗遗忘。
为了进一步显示模型是否出现遗忘,作者还比较了iCaRL与三个baseline在CIFAR-100上的混淆矩阵(一次增量学习多学习10类),结果如下:
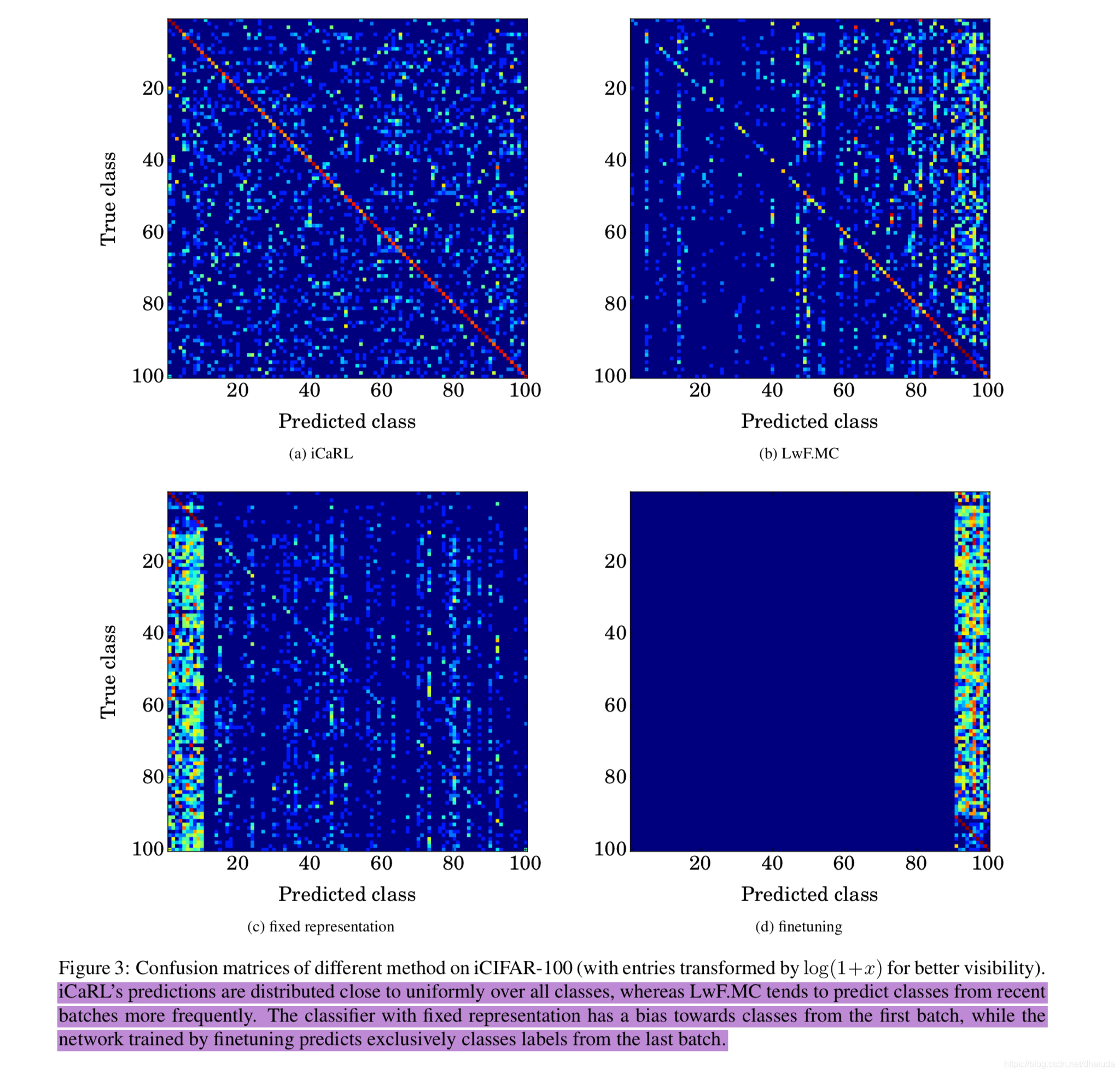
iCaRL存在一个明显的对角线,分类性能最好,LwF.MC偏向于预测新的类别,这在一定程度上说明模型出现了遗忘,fixed representation偏向于预测旧的类别,这很好理解,因为特征提取器一次增量学习后就被固定了,对于新类别,很难提取出足够区分度的特征,finetuning
的遗忘现象最为严重。
其他实验
iCaRL采取了三个策略
- 使用最近邻分类器
- 使用 e x a m p l a r examplar examplar集合以及新类别数据训练模型
- 使用蒸馏loss
为了探究上述三个策略在抵抗遗忘方面的作用,论文设计了三个比对实验
- h y b r i d 1 hybrid1 hybrid1:使用策略2、3,使用全连接层分类器
- h y b r i d 2 hybrid2 hybrid2:使用策略1、2,不使用蒸馏loss
- h y b r i d 3 hybrid3 hybrid3:仅使用策略2
- i C a R L iCaRL iCaRL:使用策略1、2、3
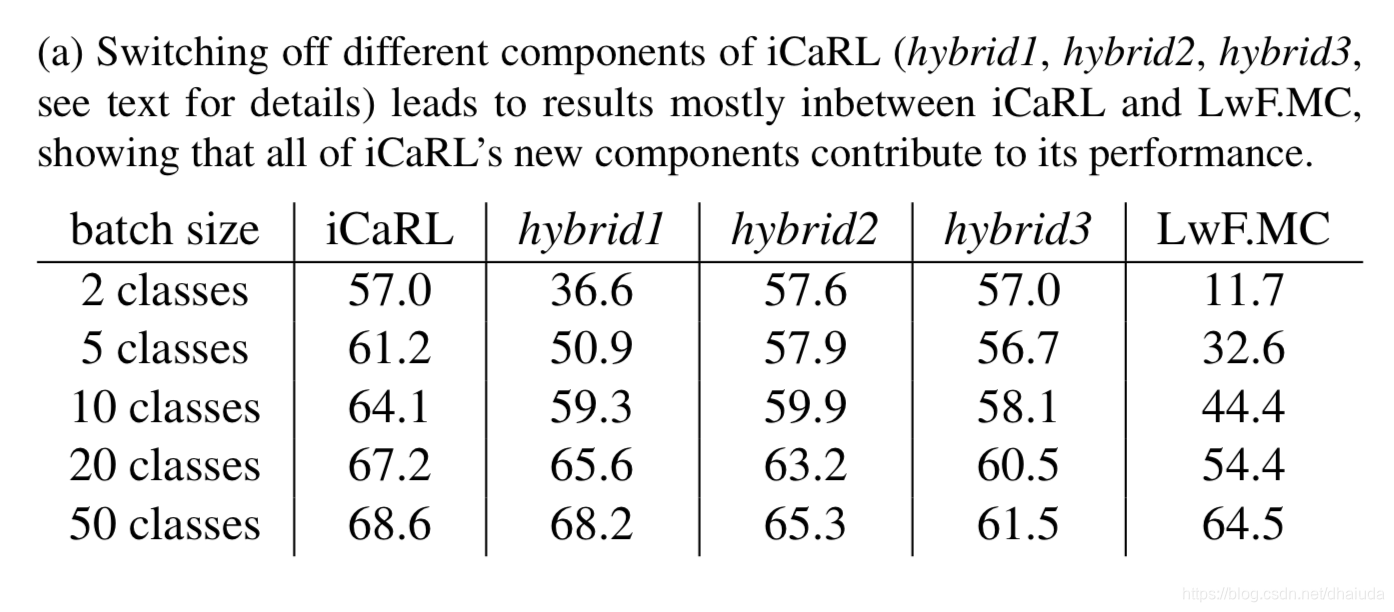
多次增量学习后,模型的平均准确率如下:
i
C
a
R
L
iCaRL
iCaRL vc
h
y
b
r
i
d
1
hybrid1
hybrid1:可以康出使用最近邻分类器更具有优势
i
C
a
R
L
iCaRL
iCaRL vc
h
y
b
r
i
d
2
hybrid2
hybrid2:当N取值较小(例如2)时,蒸馏loss似乎无法有效提高模型准确率,当N取值较大(N>2)时,蒸馏loss有助于抵抗遗忘
h
y
b
r
i
d
3
hybrid3
hybrid3 vs LwF.MC:使用
e
x
a
m
p
l
a
r
examplar
examplar集合与新数据一起训练模型一定程度上有助于模型抵抗遗忘
个人理解
本论文的分类准确率提升来源于两个方面
- 使用新数据与部分旧数据微调网络
- 使用更为鲁棒的分类算法——最近邻
从论文结果中可以看到,使用最近邻进行分类的架构比使用全连接层进行分类的架构准确率提升了几个百分点,个人认为这属于分类器的鲁棒性带来的性能提升。
对新数据进行训练时,特征提取器(CNN)的输出可能与旧数据的输出发生非常大的改变,如果分类器对于输入的扰动过于敏感,可能会导致旧数据的遗忘,而最近邻算法鲁棒性恰好非常优越。
论文开源代码地址iCaRL

















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









