







前言
该论文从类别不平衡的角度解决持续学习中的灾难性遗忘问题。
在保存部分旧数据的情况下,新旧数据之间会出现类别不平衡,导致模型在训练时过度关注新数据,忽略旧数据,从而导致灾难性遗忘。
本文将简单介绍该论文提出的方法,并介绍其中较为有意思的实验,最后给出我对本篇文章的看法
Method
Motivation
作者首先介绍了GKD和TKD两种知识蒸馏loss,其区别如下图
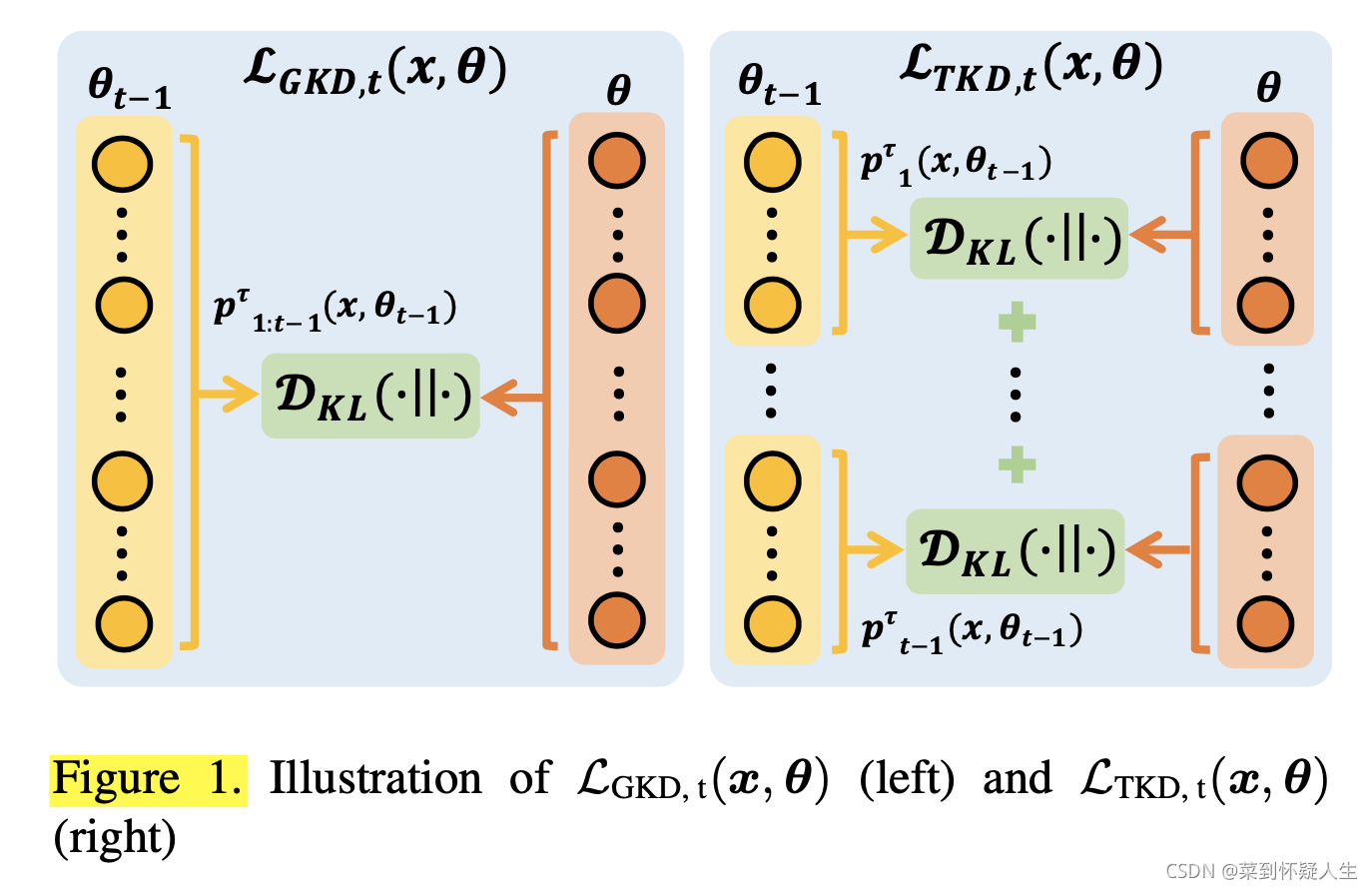
假设旧模型有50类,新模型有60类,每个task包含10类数据,GKD知识蒸馏流程如下
- 新模型输出的前50个logit进行softmax操作
- 旧模型输出的50个logit进行softmax操作
- 步骤一、二的结果进行交叉熵计算,其中步骤二作为交叉熵的target分布
TKD知识蒸馏流程如下
- 新模型输出的前50个logit以task为单位,每10个logit计算softmax,共有5组
- 旧模型输出的50个logit以task为单位,每10个logit计算softmax,共有5组
- 步骤一、二的结果按组进行交叉熵计算,其中步骤二作为交叉熵的target分布
作者指出GKD会加剧模型的分类偏好,如下图所示
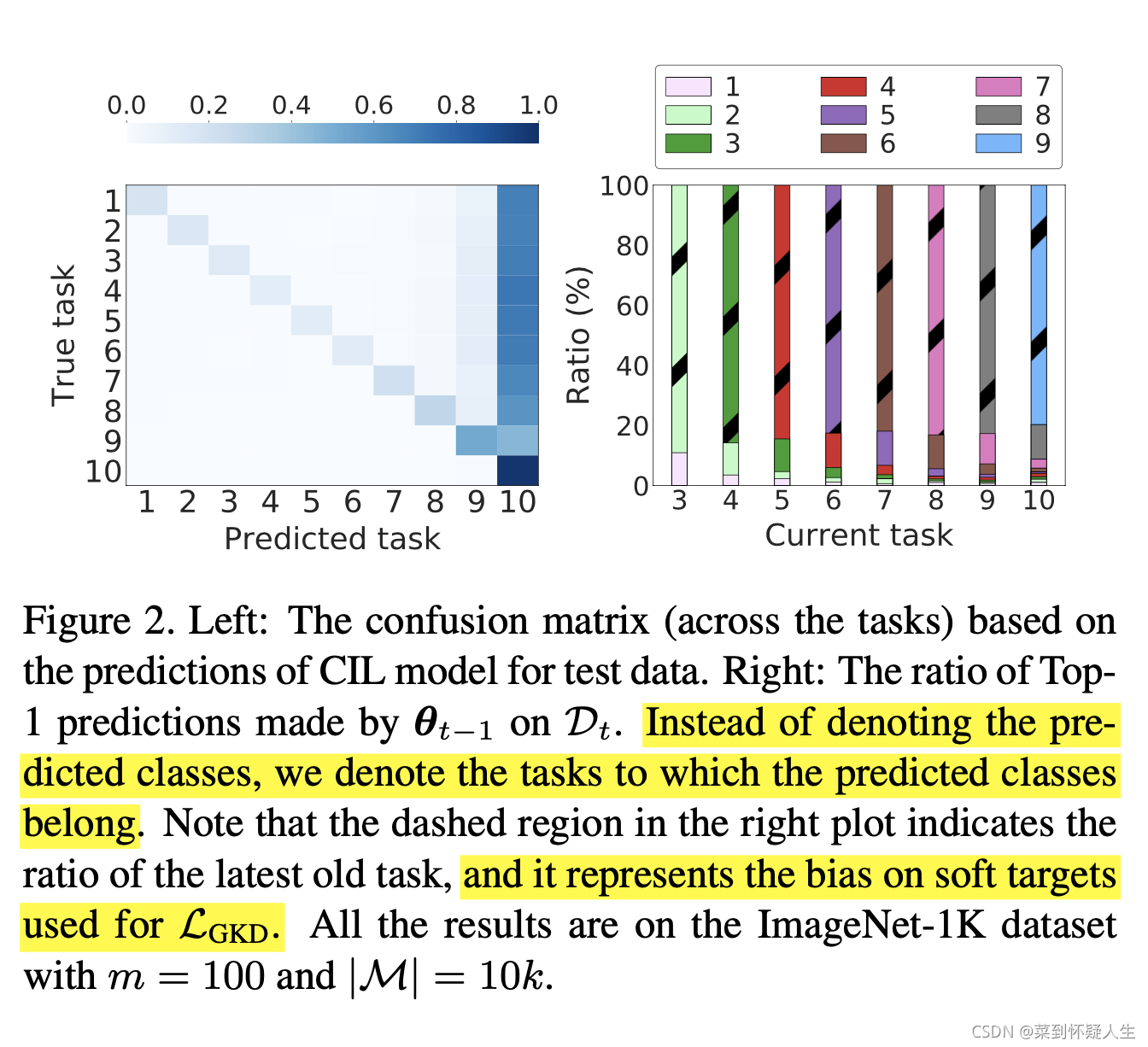
我们看右边那张图,举个例子,Current Task=3表示Task 2的模型,在Task 3训练数据上的预测结果,绿色表示模型分类结果为Task 2的比例,浅粉色表示模型分类结果为Task 1的比例,可以看到模型偏向于将样本分为最近新学习过的task,如果使用GKD进行知识蒸馏,会导致模型只关注最近学习过的旧task,而忽略更早以前的task。
作者在Bias caused by ordinary cross-entropy一节中指出交叉熵会加剧分类偏好,并且从梯度角度做了简单解释,我不太认可他这类说法,one-hot编码情况下,交叉熵等价于极大似然估计,极大似然估计会认为训练数据较多的类别,在现实场景中出现的概率更大,从而偏向于将测试样本分为训练数据较多的类别,这是我认为类别不平衡情况下交叉熵会出现分类偏好的原因。
不论是GKD还是交叉熵,他们都是将分类器的全部输出做softmax,作者认为这可能导致分类偏好(原文如下),因此作者提出了Separated-Softmax。
- Above two observations suggest that the main reason for the prediction bias could be to compute the softmax probability by combining the old and new tasks altogether. Motivated by this, we propose Separated-Softmax for Incremen- tal Learning (SS-IL) in the next section.
Separated-Softmax
该论文会保留部分旧数据,假设现在有50类属于旧类别,10类属于新类别,当一张图像属于旧类别时,分类器的前50个输出做softmax计算,当一张图像属于新类别时,分类器的后10分输出做softmax计算。除此之外,作者还提出使用TKD进行知识蒸馏。作者会控制一个batch中新旧类别的比例,相当于re-sample,但是文章没有指出这个trick影响有多大。
实验
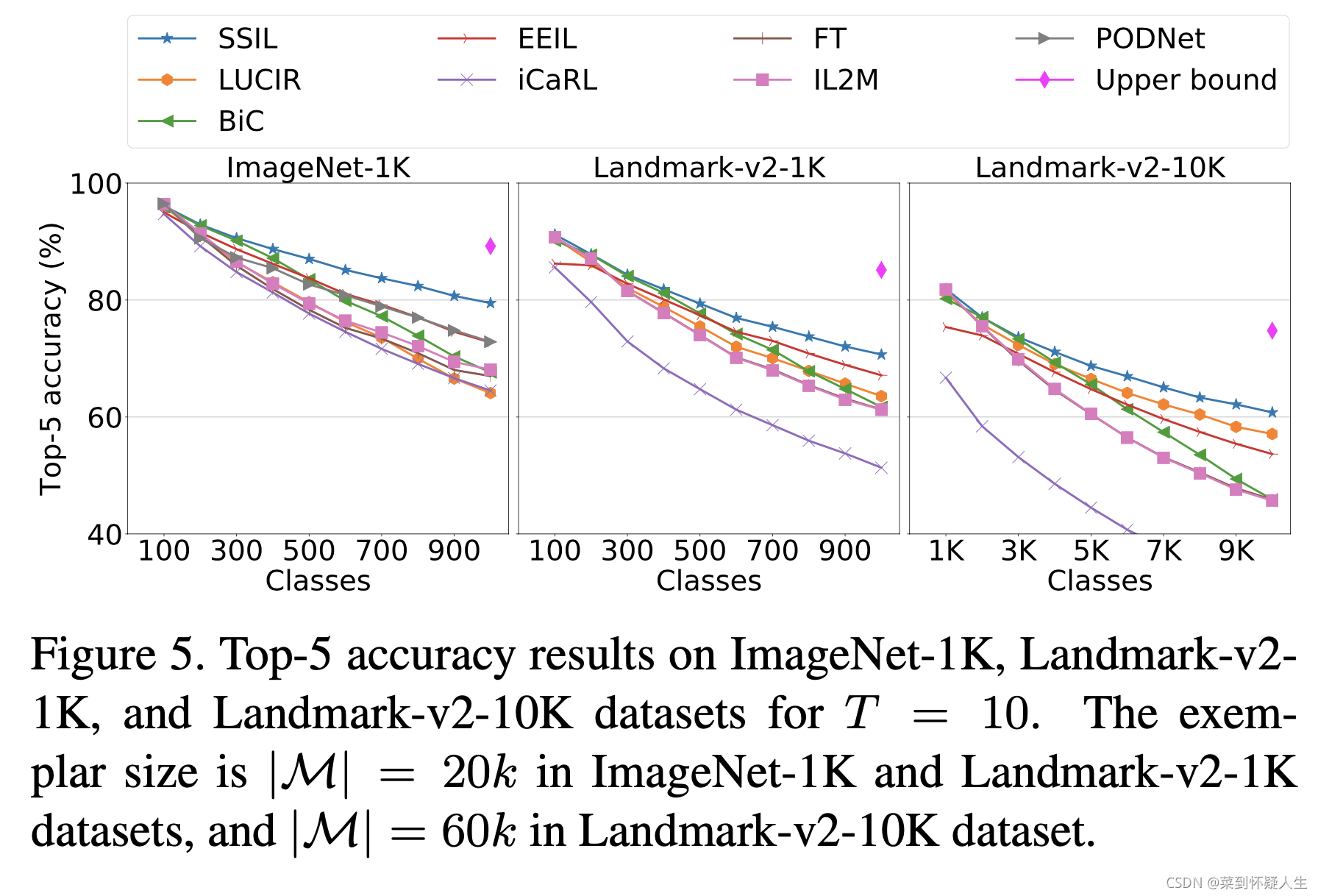
初始阶段的准确率必须保证基本一致,作者给出的解释是End2End的参数不够合理,iCaRL的NME分类器不够好,这个说法不是正确的,初始阶段都是用交叉熵训练的,你调一下参数让每个method的拟合程度基本一致即可。
消融实验部分
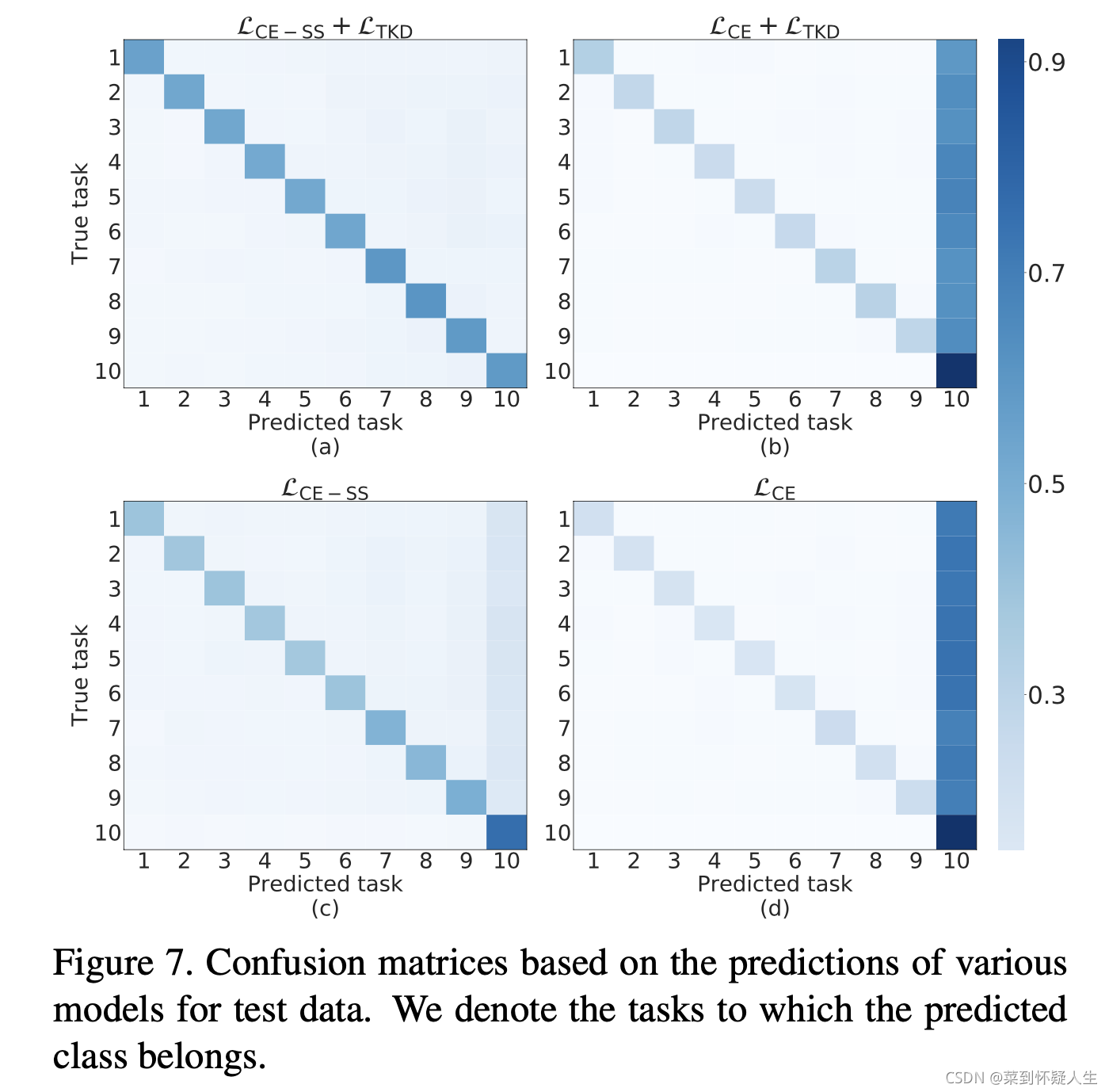
其中
L
C
E
−
S
S
L_{CE-SS}
LCE−SS即作者提出的Separated-Softmax loss,可见作者提出的方案的确可以减缓分类偏好
思考
这篇文章的Motivation和做法还是相当奇怪的。分类器的全部输出做softmax怎么可能是导致分类偏好的原因呢?此外,作者将分类器的输出按照新旧类别分为两部分,两部分单独做softmax,这个做法有点反直觉,举个例子,假设我们有四个类别,标签分别为1、2、3、4,旧类别为1、2,新类别为3、4,当我们输入一张类别4的图像时,如何保证类别4输出的logit一定比类别1、2、3的都大(训练时只能保证类别4输出的logit比类别3大)?
文章的另一个contribution是指出TKD比GKD的效果好,从混淆矩阵看,TKD相比于GKD,分类偏好的程度确实更弱些。
总体而言,这篇文章的确有亮点,能给人一些启示,但我个人感觉够不太上ICCV的发表标准
近年来增量的文章质量都比较一般,甚至出现不少依据方法特性改实验设置的顶会论文,此类论文很难给人一些启示,我更喜欢看到一些新角度解决增量学习的论文,即使这些论文的性能不是最优的。这个领域缺少的是新视角,而不是各种刷点的组合类文章。希望审稿人们对于提供新视角的论文宽容一些,而不是一味强调performance。

















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









