







前言
本文总结《深度强化学习》中连续控制章节的内容,如有错误,欢迎指出。
连续控制
前面几篇博客总结的强化学习方法,动作空间都是离散有限的。但动作空间不一定总是离散的,也可能是连续的,例如驾驶车辆,汽车转向角度的动作空间就是连续的。针对上述问题,一个可行的解决方案是将动作空间离散化,除此之外,可以直接使用连续控制相关的强化学习方法。本文将总结确定策略梯度算法(DPG)。
DPG
DPG属于策略学习的方法。具体而言,DPG使用Actor-Critic框架,利用价值网络辅助策略网络的训练。DPG的方法框架如下图所示
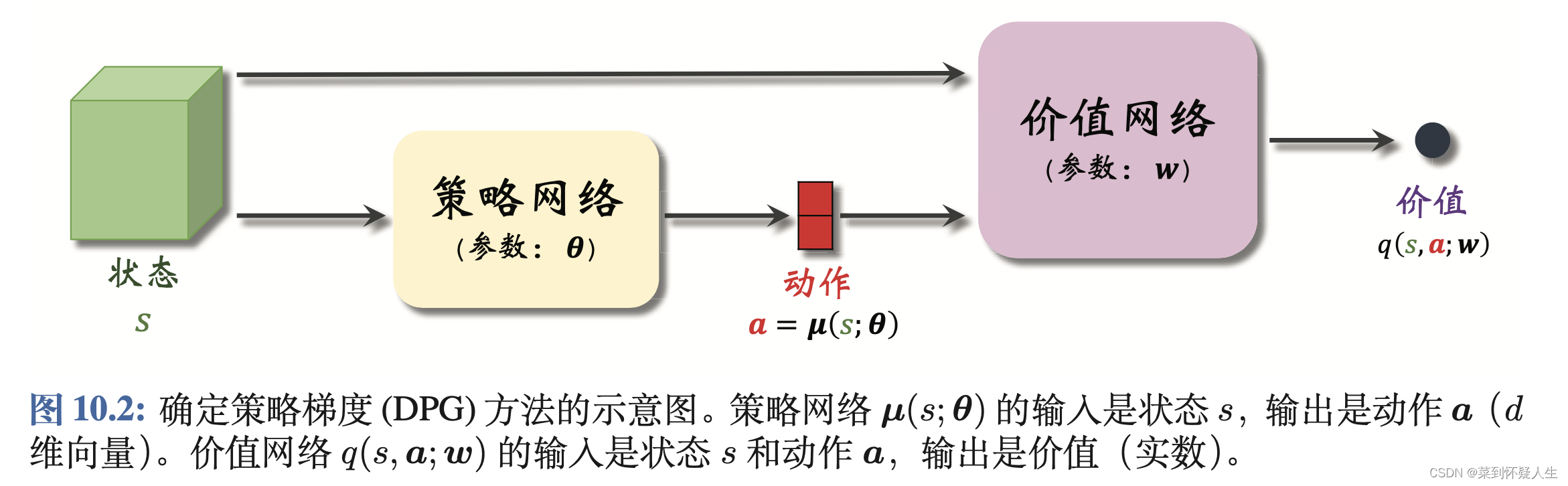
策略网络的输入为状态
s
s
s,输出为智能体执行的具体动作
a
=
μ
(
s
;
θ
)
a=\mu(s;\theta)
a=μ(s;θ)。前文介绍的方法,策略网络的输出为智能体执行各个动作的概率,而DPG的输出为一个确定值。将状态
s
s
s与动作
a
=
μ
(
s
;
θ
)
a=\mu(s;\theta)
a=μ(s;θ)输入到价值网络中,给出动作的得分
q
(
s
,
a
;
θ
)
q(s,a;\theta)
q(s,a;θ)。
DPG的优化目标
DPG的优化目标为
max
J
(
θ
)
=
max
E
S
[
q
(
S
,
μ
(
S
;
θ
)
;
w
)
]
(1.0)
\max J(\theta)=\max E_S[q(S,\mu(S;\theta);w)]\tag{1.0}
maxJ(θ)=maxES[q(S,μ(S;θ);w)](1.0)
θ
\theta
θ为策略网络的参数。即希望不论面对什么状态,策略网络的输出都能使价值网络给出较高的分数。因此可得式1.0的梯度为
∇ θ J ( θ ) = E S [ ∇ θ μ ( S ; θ ) ∇ θ q ( S , μ ( S ; θ ) ; w ) ] (1.1) \nabla_\theta J(\theta)=E_S[\nabla_\theta \mu(S;\theta) \nabla_\theta q(S,\mu(S;\theta);w)]\tag{1.1} ∇θJ(θ)=ES[∇θμ(S;θ)∇θq(S,μ(S;θ);w)](1.1)
值得一提的是,DPG作为策略学习的一类算法,其目标应该是使状态价值函数的取值最大化,而式1.1与强化学习——策略学习章节推导的随机策略梯度
∇
θ
J
′
(
θ
)
\nabla_\theta J'(\theta)
∇θJ′(θ)不同,
∇
θ
J
′
(
θ
)
\nabla_\theta J'(\theta)
∇θJ′(θ)的数学表达式为
∇
θ
J
′
(
θ
)
=
E
S
[
E
A
∼
π
(
.
∣
S
;
θ
)
[
Q
π
(
S
,
A
)
∇
θ
ln
π
(
A
∣
S
;
θ
)
]
]
(1.2)
\nabla_\theta J'(\theta)=E_S[E_{A\sim \pi(.|S;\theta)}[Q_\pi(S,A)\nabla_{\theta}\ln\pi(A|S;\theta)]] \tag{1.2}
∇θJ′(θ)=ES[EA∼π(.∣S;θ)[Qπ(S,A)∇θlnπ(A∣S;θ)]](1.2)
设确定策略
μ
(
S
;
θ
)
\mu(S;\theta)
μ(S;θ)的输出为
d
d
d维向量,它的第
i
i
i个元素记作
μ
i
\mu_i
μi。设随机策略输出的概率分布为
π
(
a
∣
s
;
θ
,
δ
)
=
∏
i
=
1
d
1
6.28
δ
exp
(
−
[
a
i
−
μ
i
]
2
δ
i
2
)
\pi(a|s;\theta,\delta)=\prod_{i=1}^{d}\frac{1}{\sqrt{6.28}\delta}\exp (-\frac{[a_i-\mu_i]}{2\delta_i^2})
π(a∣s;θ,δ)=i=1∏d6.28δ1exp(−2δi2[ai−μi])
当
δ
=
[
δ
1
、
δ
2
、
.
.
.
、
δ
d
]
\delta=[\delta_1、\delta_2、...、\delta_d]
δ=[δ1、δ2、...、δd]为零向量时,存在(具体证明见DPG的论文《Deterministic Policy Gradient Algorithms》)
lim
δ
→
0
∇
θ
J
′
(
θ
)
=
∇
θ
J
(
θ
)
\lim_{\delta\to0}\nabla_\theta J'(\theta)=\nabla_\theta J(\theta)
δ→0lim∇θJ′(θ)=∇θJ(θ)
即确定策略梯度(式1.1)为随机策略梯度(式1.2)的一个特例,优化式子1.1也能使得状态价值函数的取值最大化。
On-Policy DPG
On-Policy DPG(同策略DPG)使用Actor-Critic框架训练策略网络与价值网络,其具体步骤为
- 观测到当前的状态 s t s_t st,将该状态输入到策略网络中,得到智能体的动作 μ ( s t ; θ ) \mu(s_{t};\theta) μ(st;θ)。智能体执行该动作后得到新的状态 s t + 1 s_{t+1} st+1和奖励 r t r_t rt。将状态 s t + 1 s_{t+1} st+1输入到策略网络中,得到智能体执行的动作 μ ( s t + 1 ; θ ) \mu(s_{t+1};\theta) μ(st+1;θ)。
- 计算 q ^ t = q π ( s t , μ ( s t ; θ ) ; w n o w ) \hat q_t=q_\pi(s_t,\mu(s_{t};\theta);w_{now}) q^t=qπ(st,μ(st;θ);wnow)、 q ^ t + 1 = q π ( s t + 1 , μ ( s t + 1 ; θ ) ; w n o w ) \hat q_{t+1}=q_\pi(s_{t+1},\mu(s_{t+1};\theta);w_{now}) q^t+1=qπ(st+1,μ(st+1;θ);wnow)
- 利用贝尔曼方程优化价值网络 q ( s , a ; w ) q(s,a;w) q(s,a;w) w n e w = w n o w − α [ q ^ t − ( r t + q ^ t + 1 ) ] ∇ w q ( s t , μ ( s t ; θ ) ; w n o w ) w_{new}=w_{now}-\alpha [\hat q_t-(r_t+\hat q_{t+1})]\nabla_{w}q(s_t,\mu(s_{t};\theta);w_{now}) wnew=wnow−α[q^t−(rt+q^t+1)]∇wq(st,μ(st;θ);wnow)
- 更新策略网络 θ n e w = θ n o w + β ∇ θ q ^ t ∇ θ μ ( s t ; θ ) \theta_{new}=\theta_{now}+\beta \nabla_{\theta}\hat q_t \nabla_{\theta}\mu(s_t;\theta) θnew=θnow+β∇θq^t∇θμ(st;θ)
Off-Policy DPG
DPG的策略网络输出的动作是确定的,因此同策略DPG难以充分探索环境,网络可能收敛至局部最小值。值得一提的是,随机策略梯度的策略网络输出的动作是概率分布,依据概率采样动作(概率小的动作也可能被采样)可以让智能体充分探索环境。
异策略DPG(Off-Policy DPG)解决同策略DPG难以充分探索环境的问题。值得一提的是,同策略DPG的价值网络拟合的是动作价值函数,而异策略DPG的价值网络拟合的是最优动作价值函数。同策略DPG使用SARSA算法训练价值网络,而异策略DPG使用Q-learning训练价值网络。
异策略DPG训练策略网络和价值网络的流程为
- 开始训练前,利用策略网络控制智能体在环境中运动,得到一系列的四元组( s t , a t , s t + 1 , a t + 1 s_t,a_t,s_{t+1},a_{t+1} st,at,st+1,at+1),所有的四元组构成经验回放数组
- 从经验回放数组中抽取四元组(
s
t
,
a
t
,
s
t
+
1
,
a
t
+
1
s_t,a_t,s_{t+1},a_{t+1}
st,at,st+1,at+1),通过策略网络计算
a ^ t = μ ( s t ; θ n o w ) a ^ t + 1 = μ ( s t + 1 ; θ n o w ) \hat a_t=\mu(s_t;\theta_{now})\ \ \ \hat a_{t+1}=\mu(s_{t+1};\theta_{now}) a^t=μ(st;θnow) a^t+1=μ(st+1;θnow) - 利用价值网络计算(注意动作的符号)
q ^ t = q ( s t , a t ; w n o w ) q ^ t + 1 = q ( s t + 1 , a ^ t + 1 ; w n o w ) \hat q_t=q(s_t,a_t;w_{now}) \ \ \ \hat q_{t+1}=q(s_{t+1},\hat a_{t+1};w_{now}) q^t=q(st,at;wnow) q^t+1=q(st+1,a^t+1;wnow) - 更新价值网络的参数
w n e w = w n o w − α [ q ^ t − ( r t + q ^ t + 1 ) ] ∇ w q ( s t , μ ( s t ; θ ) ; w n o w ) w_{new}=w_{now}-\alpha [\hat q_t-(r_t+\hat q_{t+1})]\nabla_{w}q(s_t,\mu(s_{t};\theta);w_{now}) wnew=wnow−α[q^t−(rt+q^t+1)]∇wq(st,μ(st;θ);wnow) - 更新策略网络的参数
θ n e w = θ n o w + β ∇ θ q ( s t , a ^ t ; w ) ∇ θ μ ( s t ; θ n o w ) \theta_{new}=\theta_{now}+\beta \nabla_{\theta}q(s_t,\hat a_t;w) \nabla_{\theta}\mu(s_t;\theta_{now}) θnew=θnow+β∇θq(st,a^t;w)∇θμ(st;θnow)
值得一提的是,异策略DPG让价值网络拟合最优动作价值函数
Q
∗
(
s
,
a
;
θ
)
Q_*(s,a;\theta)
Q∗(s,a;θ),因此其希望策略网络输出的动作为
μ
(
s
;
θ
)
≈
arg max
a
Q
∗
(
s
,
a
;
θ
)
\mu(s;\theta)\approx \argmax_a Q_*(s,a;\theta)
μ(s;θ)≈aargmaxQ∗(s,a;θ)
由于异策略DPG的价值网络使用最优贝尔曼方程进行优化,因此其存在最大化、自举导致的高估问题(可以浏览强化学习——价值学习中的DQN章节)。对于此类问题,可以使用Twin Delayed Deep Deterministic Policy Gradient(TD3)解决。TD3含有两个价值网络,两个目标价值网络,一个策略网络,一个目标策略,其具体训练流程为
-
初始阶段,随机初始化两个目标网络的参数 w 1 、 w 2 w_1、w_2 w1、w2以及策略网络的参数 θ \theta θ。接着初始化两个目标价值网络的参数 w 1 − 、 w 2 − w_1^-、w_2^- w1−、w2−以及目标策略网络的参数 θ − \theta^- θ−为
w 1 − = w 1 w 2 − = w 2 θ − = θ w_1^-=w_1\\ w_2^-=w_2\\ \theta^-=\theta w1−=w1w2−=w2θ−=θ -
开始训练前,利用某种策略控制智能体与环境交互,获得一系列四元组( s t , a t , r t , s t + 1 s_t,a_t,r_t,s_{t+1} st,at,rt,st+1),这些四元组成经验回放数组。
-
训练时,从经验回放数组中抽取一个四元组( s t , a t , r t , s t + 1 s_t,a_t,r_t,s_{t+1} st,at,rt,st+1),让目标策略网络计算
a ^ j + 1 − = μ ( s j + 1 ; θ n o w − ) + ϵ \hat a_{j+1}^-=\mu(s_{j+1};\theta_{now}^-)+\epsilon a^j+1−=μ(sj+1;θnow−)+ϵ其中 ϵ \epsilon ϵ为截断独立正态分布中抽取的随机噪声,这个步骤视为了缓解最大化导致的高估问题 -
让两个目标价值网络预测,这一步骤用于缓解自举导致的高估问题
q ^ 1 , j + 1 − = q ( s j + 1 , a ^ j + 1 − ; w 1 , n o w − ) q ^ 2 , j + 1 − = q ( s j + 1 , a ^ j + 1 − ; w 2 , n o w − ) \begin{aligned} \hat q_{1,j+1}^-&=q(s_{j+1},\hat a_{j+1}^-;w_{1,now}^-)\\ \hat q_{2,j+1}^-&=q(s_{j+1},\hat a_{j+1}^-;w_{2,now}^-) \end{aligned} q^1,j+1−q^2,j+1−=q(sj+1,a^j+1−;w1,now−)=q(sj+1,a^j+1−;w2,now−) -
计算TD误差 y ^ j = r j + min { q ^ 1 , j + 1 − , q ^ 2 , j + 1 − } \hat y_j=r_j+\min\{\hat q_{1,j+1}^-,\hat q_{2,j+1}^-\} y^j=rj+min{q^1,j+1−,q^2,j+1−}
-
更新两个价值网络
w 1 , n e w = w 1 , n o w − α ( q ^ 1 , j + 1 − − y ^ j ) ∇ w 1 q ( s j , a j ; w 1 , n o w ) w 2 , n e w = w 2 , n o w − α ( q ^ 2 , j + 1 − − y ^ j ) ∇ w 2 q ( s j , a j ; w 2 , n o w ) \begin{aligned} w_{1,new}&=w_{1,now}-\alpha (\hat q_{1,j+1}^--\hat y_j) \nabla_{w_1} q(s_{j},a_{j};w_{1,now})\\ w_{2,new}&=w_{2,now}-\alpha (\hat q_{2,j+1}^--\hat y_j) \nabla_{w_2} q(s_{j},a_{j};w_{2,now}) \end{aligned} w1,neww2,new=w1,now−α(q^1,j+1−−y^j)∇w1q(sj,aj;w1,now)=w2,now−α(q^2,j+1−−y^j)∇w2q(sj,aj;w2,now) -
每隔k轮更新一次策略网络和三个目标网络
- 让策略网络计算 a ^ t = μ ( s t ; θ n o w ) \hat a_t=\mu(s_t;\theta_{now}) a^t=μ(st;θnow),接着更新策略网络 θ n e w = θ n o w + β ∇ θ q ( s t , a ^ t ; w ) ∇ θ μ ( s t ; θ n o w ) \theta_{new}=\theta_{now}+\beta \nabla_{\theta}q(s_t,\hat a_t;w) \nabla_{\theta}\mu(s_t;\theta_{now}) θnew=θnow+β∇θq(st,a^t;w)∇θμ(st;θnow)
- 用动量方式更新三个策略网络参数,
γ
\gamma
γ为超参数
θ n e w − = γ θ n e w + ( 1 − γ ) θ n o w − w 1 , n e w − = γ w 1 , n e w + ( 1 − γ ) w 1 , n o w − w 2 , n e w − = γ w 2 , n e w + ( 1 − γ ) w 2 , n o w − \begin{aligned} \theta_{new}^-&=\gamma \theta_{new}+(1-\gamma)\theta_{now}^-\\ w_{1,new}^-&=\gamma w_{1,new}+(1-\gamma)w_{1,now}^-\\ w_{2,new}^-&=\gamma w_{2,new}+(1-\gamma)w_{2,now}^- \end{aligned} θnew−w1,new−w2,new−=γθnew+(1−γ)θnow−=γw1,new+(1−γ)w1,now−=γw2,new+(1−γ)w2,now−
随机高斯策略
除去使用DPG解决连续控制问题外,还可以使用随机高斯策略解决。随机高斯策略假设策略函数服从高斯分布:
π
(
a
∣
s
;
θ
,
δ
)
=
∏
i
=
1
d
1
6.28
δ
exp
(
−
[
a
i
−
μ
i
]
2
δ
i
2
)
\pi(a|s;\theta,\delta)=\prod_{i=1}^{d}\frac{1}{\sqrt{6.28}\delta}\exp (-\frac{[a_i-\mu_i]}{2\delta_i^2})
π(a∣s;θ,δ)=i=1∏d6.28δ1exp(−2δi2[ai−μi])
其使用两个神经网络
μ
(
s
;
θ
)
\mu(s;\theta)
μ(s;θ)、
ρ
(
s
;
θ
)
\rho(s;\theta)
ρ(s;θ)拟合高斯分布的均值
μ
\mu
μ和对数方差
ln
δ
\ln\delta
lnδ,均值和方差神经网络(又称为辅助网络)的结构图为
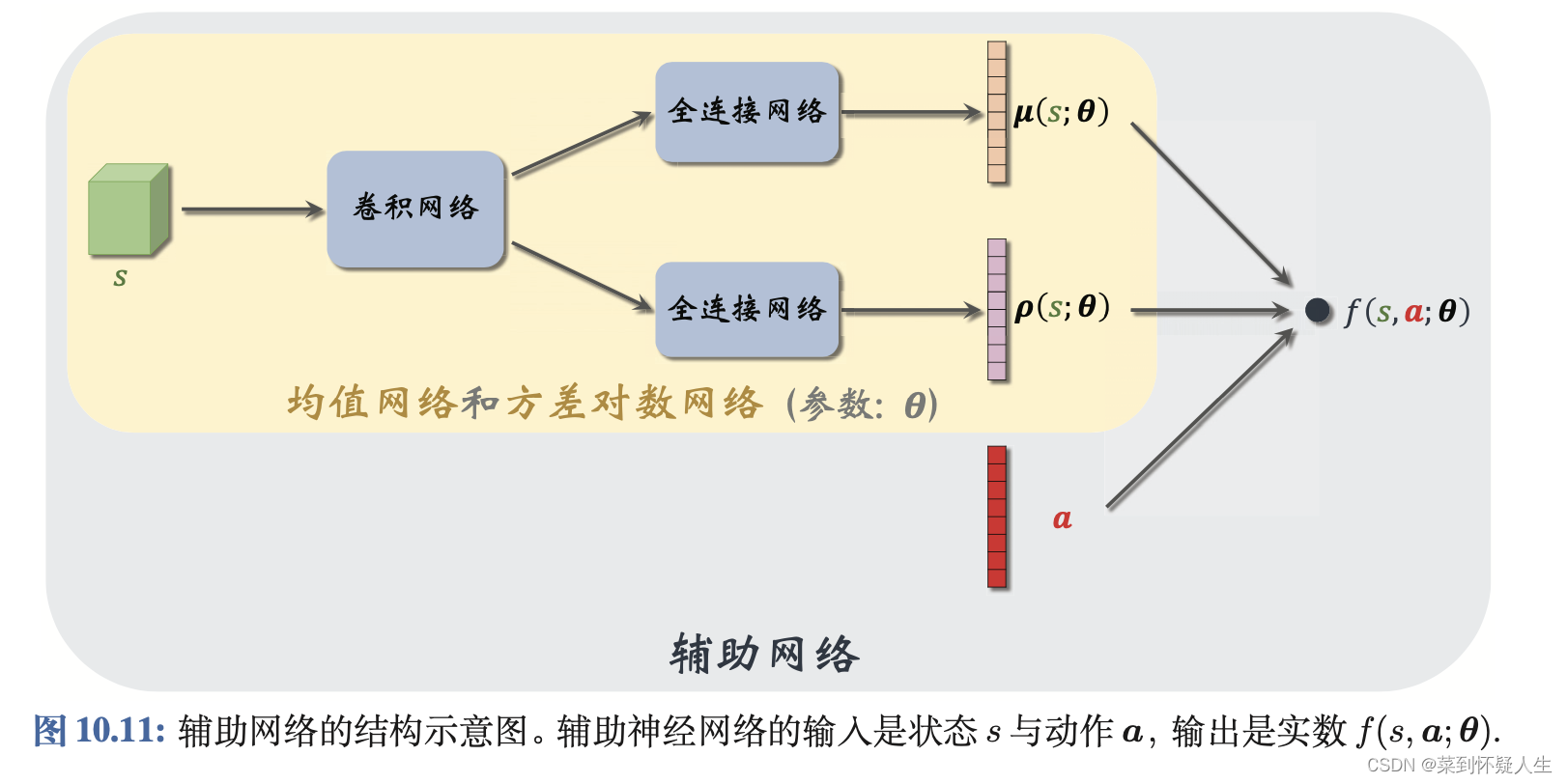
随机高斯策略的训练流程为
- 观测到当前的状态 s t s_t st,计算均值、方差 μ ( s t ; θ ) \mu(s_t;\theta) μ(st;θ)、 exp ( ρ ( s t ; θ ) ) \exp(\rho(s_t;\theta)) exp(ρ(st;θ)),从高斯分布中采样动作 a a a
- 计算动作价值函数 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a)
- 用反向传播计算辅助网络关于参数 θ \theta θ的梯度 ∇ θ ln π ( a ∣ s ; θ ) \nabla_{\theta}\ln \pi(a|s;\theta) ∇θlnπ(a∣s;θ)
- 计算策略梯度
Q π ( s , a ) ∇ θ ln π ( a ∣ s ; θ ) Q_{\pi}(s,a)\nabla_{\theta}\ln \pi(a|s;\theta) Qπ(s,a)∇θlnπ(a∣s;θ) - 用梯度上升法更新辅助网络的参数
θ n e w = θ n o w + β Q π ( s , a ) ∇ θ ln π ( a ∣ s ; θ ) \theta_{new}=\theta_{now}+\beta Q_{\pi}(s,a)\nabla_{\theta}\ln \pi(a|s;\theta) θnew=θnow+βQπ(s,a)∇θlnπ(a∣s;θ)
上述训练流程中的 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a)可以使用策略学习中的REINFORCE方法或Actor-Critic方法近似,具体查阅强化学习——策略学习。
测试时,将状态 S S S输入到卷积神经网络中,卷积神经网络的输出经过两个并行的全连接网络,得到高斯分布的均值和对数方差 μ ( s ; θ ) \mu(s;\theta) μ(s;θ)、 ρ ( s ; θ ) \rho(s;\theta) ρ(s;θ),接着从高斯分布中采样得到智能体执行的动作。


















 2041
2041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









