






常用的推荐系统算法实现方案有三种:
-
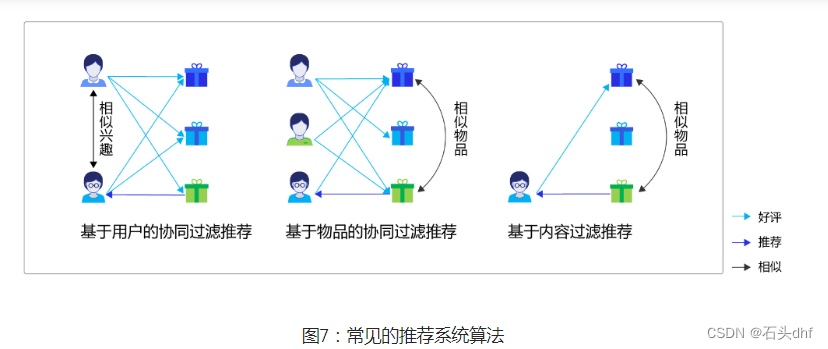
协同过滤推荐(Collaborative Filtering Recommendation):该算法的核心是分析用户的兴趣和行为,利用共同行为习惯的群体有相似喜好的原则,推荐用户感兴趣的信息。兴趣有高有低,算法会根据用户对信息的反馈(如评分)进行排序,这种方式在学术上称为协同过滤。协同过滤算法是经典的推荐算法,经典意味着简单、好用。协同过滤算法又可以简单分为两种:
a)基于用户的协同过滤:根据用户的历史喜好分析出相似兴趣的人,然后给用户推荐其他人喜欢的物品。假如小李,小张对物品A、B都给了十分好评,那么可以认为小李、小张具有相似的兴趣爱好,如果小李给物品C十分好评,那么可以把C推荐给小张,可简单理解为“人以类聚”。
b)基于物品的协同过滤:根据用户的历史喜好分析出相似物品,然后给用户推荐同类物品。比如小李对物品A、B、C给了十分好评,小王对物品A、C给了十分好评,从这些用户的喜好中分析出喜欢A的人都喜欢C,物品A、C是相似的,如果小张给了A好评,那么可以把C也推荐给小张,可简单理解为“物以群分”。
-
基于内容过滤推荐(Content-based Filtering Recommendation):基于内容的过滤是信息检索领域的重要研究内容,是更为简单直接的算法,该算法的核心是衡量出两个物品的相似度。首先对物品或内容的特征作出描述,发现其相关性,然后基于用户以往的喜好记录,推荐给用户相似的物品。比如,小张对物品A感兴趣,而物品A和物品C是同类物品(从物品的内容描述上判断),可以把物品C也推荐给小张。
-
组合推荐(Hybrid Recommendation):以上算法各有优缺点,比如基于内容的过滤推荐是基于物品建模,在系统启动初期往往有较好的推荐效果,但是没有考虑用户群体的关联属性;协同过滤推荐考虑了用户群体喜好信息,可以推荐内容上不相似的新物品,发现用户潜在的兴趣偏好,但是这依赖于足够多且准确的用户历史信息。所以,实际应用中往往不只采用某一种推荐方法,而是通过一定的组合方法将多个算法混合在一起,以实现更好的推荐效果,比如加权混合、分层混合等。具体选择哪种方式和应用场景有很大关系。

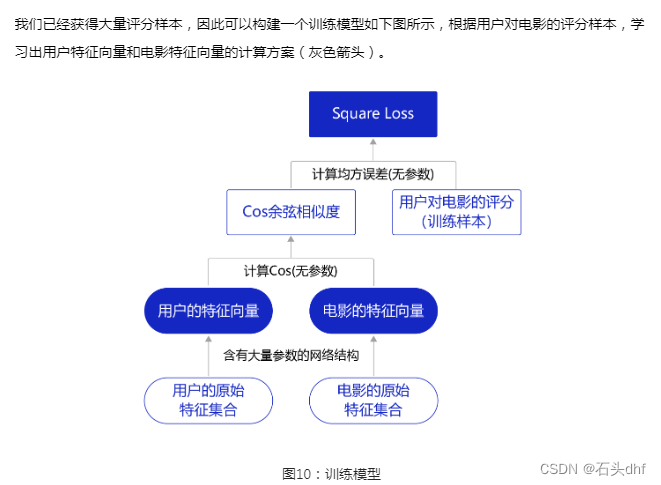
但不同类型的原始特征应该如何变换?有哪些网络设计细节需要考虑?我们将在后续几节结合代码实现逐一探讨,包括四个小节:
- 数据处理,将MovieLens的数据处理成神经网络理解的形式。
- 模型设计,设计神经网络模型,将离散的文字数据映射为向量。
- 配置训练参数并完成训练,提取并保存训练后的数据特征。
- 利用保存的特征构建相似度矩阵完成推荐。
Embedding介绍
Embedding是一个嵌入层,将输入的非负整数矩阵中的每个数值,转换为具有固定长度的向量。
在NLP任务中,一般把输入文本映射成向量表示,以便神经网络的处理。在数据处理章节,我们已经将用户和电影的特征用数字表示。嵌入层Embedding可以完成数字到向量的映射。
实际上,Embedding层和Conv2D, Linear层一样,Embedding层也有可学习的权重,通过矩阵相乘的方法对输入数据进行映射。Embedding中将输入映射成向量的实际步骤是:
-
将输入数据转换成one-hot格式的向量;
-
one-hot向量和Embedding层的权重进行矩阵相乘得到Embedding的结果。
Embedding在计算时,首先将输入数据转换成one-hot向量,one-hot向量的长度和Embedding层的输入参数size的第一个维度有关。比如这里我们设置的是10,所以输入数据将被转换成维度为[3, 10]的one-hot向量,参数size决定了Embedding层的权重形状。最终维度为[3, 10]的one-hot向量与维度为[10, 16]Embedding权重相乘,得到最终维度为[3, 16]的映射向量。
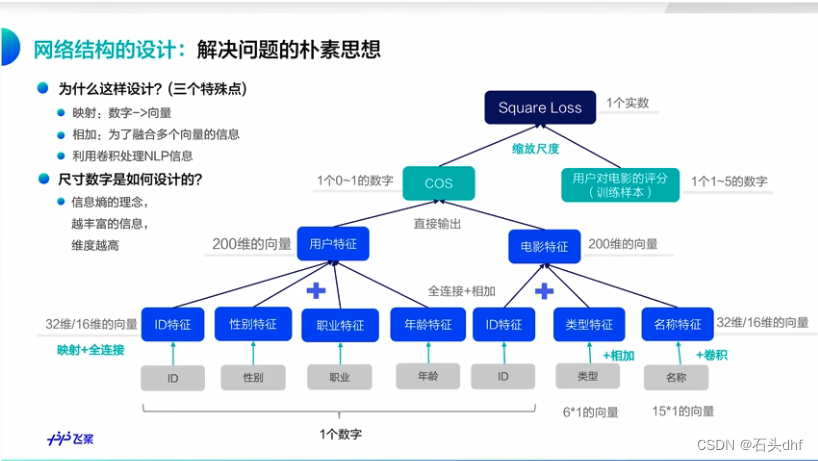
5. 融合用户特征
特征融合是一种常用的特征增强手段,通过结合不同特征的长处,达到取长补短的目的。简单的融合方法有:特征(加权)相加、特征级联、特征正交等等。此处使用特征融合是为了将用户的多个特征融合到一起,用单个向量表示每个用户,更方便计算用户与电影的相似度。上文使用Embedding加全连接的方法,分别得到了用户ID、年龄、性别、职业的特征向量,可以使用全连接层将每个特征映射到固定长度,然后进行相加,得到融合特征。
这里使用全连接层进一步提取特征,而不是直接相加得到用户特征的原因有两点:
- 一是用户每个特征数据维度不一致,无法直接相加;
- 二是用户每个特征仅使用了一层全连接层,提取特征不充分,多使用一层全连接层能进一步提取特征。而且,这里用高维度(200维)的向量表示用户特征,能包含更多的信息,每个用户特征之间的区分也更明显。
上述实现中需要对每个特征都使用一个全连接层,实现较为复杂,一种简单的替换方式是,先将每个用户特征沿着长度维度进行级联,然后使用一个全连接层获得整个用户特征向量,两种方式的对比见下图:
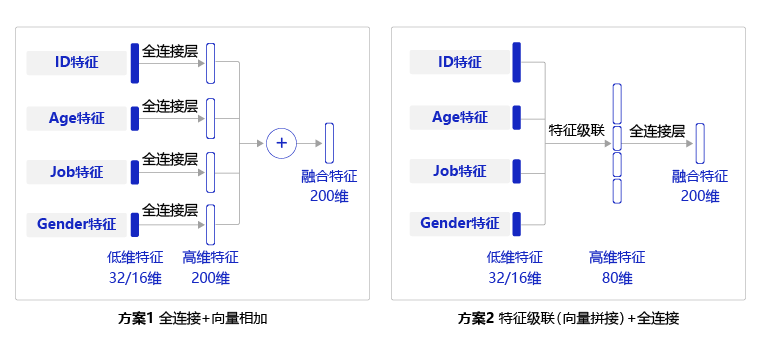
图3:两种特征方式对比示意
两种方式均可实现向量的合并,虽然两者的数学公式不同,但它们的表达方式是类似的。
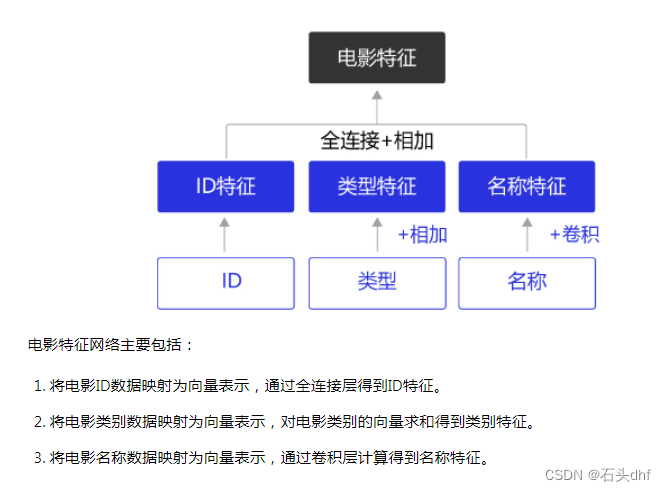
2. 提取电影类别特征
与电影ID数据不同的是,每个电影有多个类别,提取类别特征时,如果对每个类别数据都使用一个全连接层,电影最多的类别数是6,会导致类别特征提取网络参数过多而不利于学习。我们对于电影类别特征提取的处理方式是:
- 通过Embedding网络层将电影类别数字映射为特征向量;
- 对Embedding后的向量沿着类别数量维度进行求和,得到一个类别映射向量;
- 通过一个全连接层计算类别特征向量。
3. 提取电影名称特征
与电影类别数据一样,每个电影名称具有多个单词。我们对于电影名称特征提取的处理方式是:
- 通过Embedding映射电影名称数据,得到对应的特征向量;
- 对Embedding后的向量使用卷积层+全连接层进一步提取特征;
- 对特征进行降采样,降低数据维度。
提取电影名称特征时,使用了卷积层加全连接层的方式提取特征。这是因为电影名称单词较多,最大单词数量是15,如果采用和电影类别同样的处理方式,即沿着数量维度求和,显然会损失很多信息。考虑到15这个维度较高,可以使用卷积层进一步提取特征,同时通过控制卷积层的步长,降低电影名称特征的维度。
如果只是简单的经过一层或二层卷积后,特征的维度依然很大,为了得到更低维度的特征向量,有两种方式,一种是利用求和降采样的方式,另一种是继续使用神经网络层进行特征提取并逐渐降低特征维度。
余弦
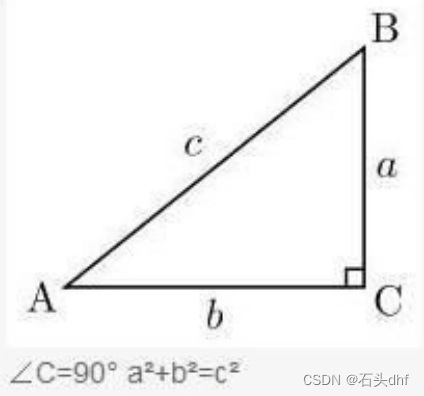
余弦(余弦函数),三角函数的一种。在Rt△ABC(直角三角形)中,∠C=90°(如概述图所示),∠A的余弦是它的邻边比三角形的斜边,即cosA=b/c,也可写为cosa=AC/AB。余弦函数:f(x)=cosx(x∈R)。
余弦定理

余弦定理,欧氏平面几何学基本定理。余弦定理是描述三角形中三边长度与一个角的余弦值关系的数学定理,是勾股定理在一般三角形情形下的推广,勾股定理是余弦定理的特例。余弦定理是揭示三角形边角关系的重要定理,直接运用它可解决一类已知三角形两边及夹角求第三边或者是已知三个边求三角的问题,若对余弦定理加以变形并适当移于其它知识,则使用起来更为方便、灵活。
对于任意三角形,任何一边的平方等于其他两边平方的和减去这两边与它们夹角的余弦的积的两倍。 [1]
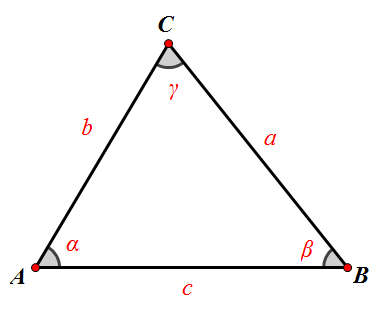
图1 三角形 余弦定理表达式1
![]()
余弦相似度
余弦相似度算法:一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
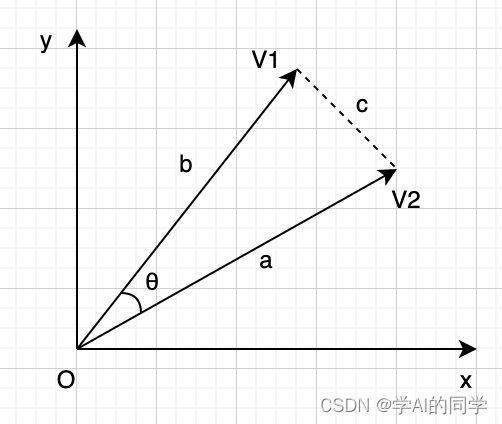
由两个已知的向量和
,利用余弦定理计算它们的夹角θ
这个三角形的三条边显然是确定的,由此我们可以用余弦定理公式算出两个向量的夹角θ。
值得一提的是,恰好等于a和b两个向量的点积<a,b>的两倍,我们将它带入余弦定理公式就能得到
表示向量的点积,其中向量范数$
对于多维向量和
的点积,通常使用下面的公式计算:















 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









