







目录
前言
目标检测损失分为类别损失和位置损失。
一、类别损失函数(分类)
1、交叉熵损失函数——Cross Entropy Loss
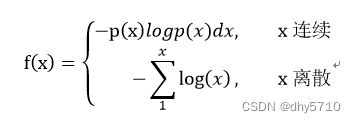
x的预测结果p(x)越大,则交叉熵f(x)越小。
实际使用时,以二分类为例。对目标的预测结果是第0类的概率为P,则是第1类的该概率为(1-P)。损失函数如下:
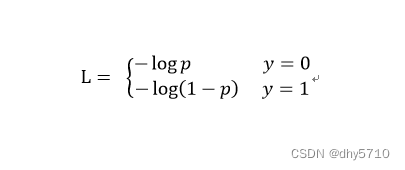
也可以写成以下形式:
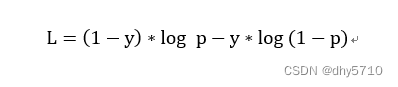
二分类中,常使用sigmod函数将结果映射到(0,1)之间。
多分类中,常使用SoftMax函数得到各个类别的概率。
2、Focal Loss
Flcal Loss函数针对正负样本不均匀、类别不平衡问题,在交叉熵的基础上进行了改进。
(1) 通过α控制正负样本对loss的贡献:
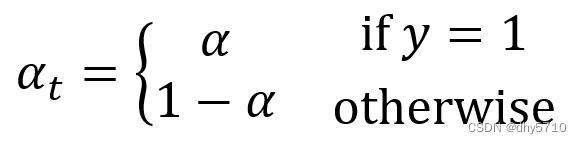
(2)通过(1-pt)^y控制类别权重
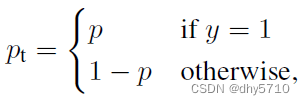
当分类准确时,(1-pt)^y→0,损失变小,当分类不准确时,(1-pt)^y→1,损失值基本不变,整体而言,增加分类不准确的样本在损失函数中的权重。通过设定不同的y,调节对不同类别的关注程度。
(3)最后得到新的公式:
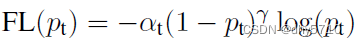
二、位置损失函数(回归)
1、L1 Loss
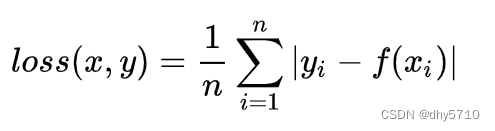
L1 Loss又称L1范数损失,最小绝对值偏差
- 优点:无论对于什么样的输入值,都有着稳定的梯度,不会导致梯度爆炸问题,具有较为稳健性的解
- 缺点:在中心点是折点,不能求导,梯度下降时要是恰好学习到w=0就没法接着进行了
2、L2 Loss
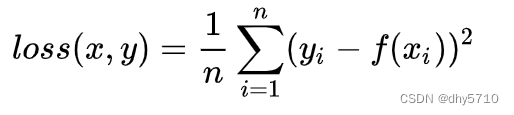
L2 Loss又称L2范数损失,最小绝对值偏差
- 优点:各点都连续光滑,方便求导,具有较为稳定的解
- 缺点:不是特别的稳健,因为当函数的输入值距离真实值较远的时候,对应loss值很大在两侧,则使用梯度下降法求解的时候梯度很大,可能导致梯度爆炸
3、Smooth L1 Loss

当预测值f(xi)和真实值yi差别较小的时候(绝对值差小于1),其实使用的是L2 loss;差别大的时候,使用的是L1 loss的平移。因此,Smooth L1 loss其实是L1 loss 和L2 loss的结合,同时拥有两者的部分优点:
- 真实值和预测值差别较小时(绝对值差小于1),梯度也会比较小(损失函数比普通L1 loss在此处更圆滑)
- 真实值和预测值差别较大时,梯度值足够小(普通L2 loss在这种位置梯度值就很大,容易梯度爆炸
(1)L1 loss在零点不平滑,此处不可导,所以在w=0时没法接着梯度下降了,用的少
(2)L2 loss对离群点比较敏感,离群点处的梯度很大,容易梯度爆炸
(3)smooth L1 loss结合了L1和L2的优点,修改了零点不平滑问题,且比L2 loss对异常值的鲁棒性更强
4、IOU Loss
IOU指的是预测框与真实框的交并比。

此时对应的loss为:L1 = 1 - IOU 或者 -ln(IOU)
5、GIOU Loss
当bounding box 与 ground truth 不相交时,IOU为0,即在此情况下,将无法计算IOU Loss,因而导致其梯度为0并且无法进行优化。因而引入了GIOU Loss。

所以GIOU计算公式如下:

当ground truth 和 bounding box 不相交且两边界框相距无穷远时,GIoU=-1。但是,当ground truth 和 bounding box 等宽高且处于同一水平或同一垂直线时,后半部分=0,此时GIoU退化为IoU。
6、DIOU Loss
IoU loss和GIoU loss都只考虑了两个框的重叠程度,但在重叠程度相同的情况下,我们其实更希望两个框能挨得足够近,即框的中心要尽量靠近。
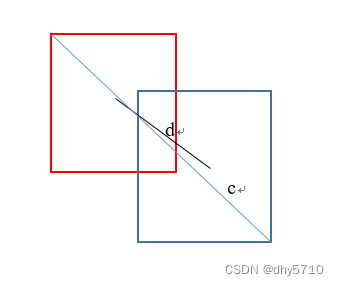
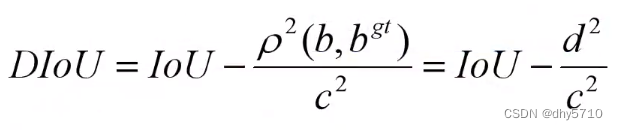
DIoU Loss与回归问题的scale无关(尺度不变性)
与GioU Loss类似,当边界框不与目标框重叠时,DIoU Loss仍然可以为边界框提供移动方向。
DIoU损失可以直接最小化两个目标盒之间的距离,因此它比GioU损失收敛快得多。
在水平和垂直两种情况下,DIoU损失可以使收益损失迅速下降,而GioU损失几乎退化为IoU损失
7、CIOU Loss
DIoU loss考虑了两个框中心点的距离,而CIoU Loss在DIoU loss的基础上做了更详细的度量——长宽比。
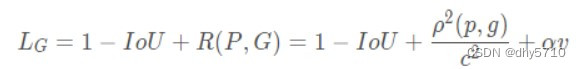
其中,v衡量长宽比的一致性,α用来调节长宽比对整体损失的影响程度。
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息














 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









