






一、SOM原理分析
自组织映射(Self-organizing Maps,SOM)算法是一种无导师学习方法,具有良好的自组织、可视化等特性,已经得到了广泛的应用和研究。它无需期望输出,只是根据数据样本进行学习,并调整自身的权重以达到学习的目的。自组织神经网络的学习规则大都采用竞争型的学习规则。
竞争型神经网络的基本思想是网络竞争层的各神经元通过竞争来获取对输入模式的响应机会,最后仅由一个神经元成为胜利者,并将与获胜神经元有关的各连接权值朝向更有力的方向调整。

在自组织映射的形成中有三个主要过程。
(1)竞争
对每个输入模式,网络中的神经元计算它们各自判别函数的值。这个判别函数为神经元之间的竞争提供基础。具有判别函数最大值的特定神经元成为胜利者。
(2)合作
获胜神经元决定兴奋神经元的拓扑邻域的空间位置, 从而提供这样的相邻神经元合作的基础。
(3)权值调节
作后的这个机制使兴奋神经元通过对它们权值的适当调节以增加其关于该输入模式的判别函数值。所作的调节使获胜神经元对以后相似的输入模式的响应增强了。
二、MATLAB代码分析
2.1 案例描述
根据Excel提供的44个城市的GDP对其发达程序进行分类,实现SOM算法(自组织特征映射),及时了解各地区经济实力等重要的信息,并得出分类结论。
2.2 样本介绍
本文选择北京、青岛、天津等44个市的GDP等五个指标,其详细内容放置在GDP.xlsx工作簿中。
2.3 网络设计
首先利用new函数创建一个SOM网络。代码为:
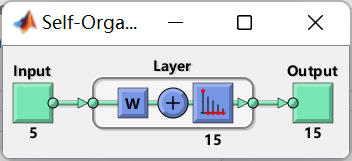
net = selforgmap([5 3]); %SOM结构
式中[5 ,3]表示创建网络的竞争层为5×3 的结构, 它是通过不断调整网络结构得出的,然后利用函数train和仿真函数sim对网络进行训练并仿真。由于训练步数影响网络的聚类性能,所以这里设计10,100 和1000 这3 个步长分别观察其分类性能。
网络结构如下:
2.4 结果分析
根据SOM神经网络聚类分析的结果,当训练步数为10时,分类情况如下:

由此可见,SOM网络已经对样本进行了初步的分类,这种分类与实际情况相符,所以选择这一分类结果。其中第一类和第二类属于经济发达地区;第三类和第四类中多数地区属于经济中等发达地区;第五类和第六类中多数地区属于经济欠发达地区。
当训练步数为100 和1000 时分类结果得到进一步细化,但不一定具有实际意义,具体的训练步数由实际情况决定。
三、完整代码
完整MATLAB代码如下:
close all;clear all;clc;
[X,Y,~]=xlsread('GDP.xlsx');%读取文件
net = selforgmap([5 3]); %SOM结构
net.trainparam.epochs = 10; %迭代次数
net = train(net,X'); %开始训练
view(net) %查看网络结构
y = net(X'); %输出y
classes = vec2ind(y); %将向量转为索引
z=Y(2:end,1)';%将城市名称转为行向量
d={classes,z};%将城市名称与索引对应
%进行排序输出
k=unique(classes);
i=1;
while (i< size(k,2))
[~,n] = find(classes == k(i));
z(n)
i = i+1;
end
总结:利用SOM 神经网络对我国各地区GDP 数据进行聚类分析,能对系统进行较准确、动态的数据聚类预测, 这将对各级政府在未来政策制定及宏观调控上都具有非常重要的现实意义。
【注意】:代码可能还存在一些小瑕疵,如果你有更好的解决方案欢迎私信我或者在文章下方留言哦~















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











