






理解卷积神经网络
搭建环境

下载Tensorflow的纯CPU版
pip install --ignore-installed --upgrade tensorflow
安装keras
pip install keras
添加jupyter_contrib_nbextensions插件
pip install jupyter_contrib_nbextensions -i https://pypi.douban.com/simple/
jupyter contrib nbextension install --user --skip-running-check
猫狗分析实例
新建一个Python3后,引入keras包,查看版本
代码如下
import os, shutil #复制文件
# 原始目录所在的路径
# 数据集未压缩
original_dataset_dir = 'D:\\QQ\\kaggle_Dog&Cat\\train'
# The directory where we will
# store our smaller dataset
base_dir = 'D:\QQ\kaggle_Dog&Cat\\find_cats_and_dogs'
os.mkdir(base_dir)
# # 训练、验证、测试数据集的目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 猫训练图片所在目录
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# 狗训练图片所在目录
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# 猫验证图片所在目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# 狗验证数据集所在目录
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
# 猫测试数据集所在目录
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
# 狗测试数据集所在目录
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# 将前1000张猫图像复制到train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 将下500张猫图像复制到validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 将下500张猫图像复制到test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 将前1000张狗图像复制到train_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将下500张狗图像复制到validation_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将下500张狗图像复制到test_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
图片数量
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))

准备完成
卷积神经网络
使用深度学习最经典的算法卷积神经网络CNN
网络模型搭建
代码如下
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()

使用图像生成器读取图片
代码如下
from keras import optimizers
model.compile(loss=‘binary_crossentropy’,
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=[‘acc’])
from keras.preprocessing.image import ImageDataGenerator
所有图像将按1/255重新缩放
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 这是目标目录
train_dir,
# 所有图像将调整为150x150
target_size=(150, 150),
batch_size=20,
# 因为我们使用二元交叉熵损失,我们需要二元标签
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
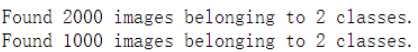















 272
272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









