







喜欢请关注,持续更新生信、统计学和机器学习的论文速递和学习笔记。

StatsART
生信论文速递、统计学和机器学习学习笔记
1,GPT-4o
2024年5月14日,OpenAI发布了GPT-4o - 一个具有多模态推理功能的新模型。
“o”代表 omni(意思是 ‘all’ 或者 ‘universally’)。
它是一种包含文本、视觉和音频输入和输出功能的多模态模型,建立在上一个版本 GPT-4 Turbo 的基础上。
GPT-4o 的强大功能和速度来自于使用单一模型处理多种模式的输出和输出。
以前的 GPT-4 版本是同时使用多个模型(语音到文本、文本到语音、文本到图像),然后后台在不同任务的模型之间切换,所以GPT-4速度比较慢。
GPT-4o官网链接:https://openai.com/index/hello-gpt-4o/
2,Gemini 1.5 系列
今年 2 月,谷歌上线了多模态大模型 Gemini1.5,通过工程和基础设施优化、MoE 架构等策略大幅提升了性能和速度。拥有更长的上下文,更强推理能力,可以更好地处理跨模态内容。
2024年5月17日,Google DeepMind 正式发布了 Gemini 1.5 的技术报告,内容覆盖 Flash 版等最近升级,该文档长达 153 页。
在本报告中,谷歌介绍了 Gemini 1.5 系列模型,它是代表了下一代高计算效率的多模态大模型,能够从数百万 token 上下文中调用细粒度信息并进行推理,包括多个长文档、数小时的视频。
该系列包括两个新型号:
-
更新的 Gemini 1.5 Pro,其大部分功能和基准都超过了 2 月份的版本
-
Gemini 1.5 Flash,一种更轻量级的变体,专为提高效率而设计,并且在性能方面的减益很小。

图:Gemini 1.5 Pro解决数学题能力
链接:
https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
3,Veo
2024年5月15日,Google Deepmind宣布正式推出视频生成模型Veo,能够支持质量更高的视频内容,用户可以对光照、镜头语言、视频颜色风格等进行设定,可生成超过 1 分钟的高质量、1080p 分辨率视频;它支持对视频进行蒙版编辑,还可以生成带有输入图像和文本的视频。
veo_cowboy_sun_1
Veo生成视频示例
Veo链接:
4,Chameleon
2024年5月16日,Meta AI研究团队(FAIR)发布了Chameleon,一个混合模态前融合(Mixed-Modal Early-Fusion)基座模型。
Chameleon 表现出很强的通用能力,在纯文本任务中优于 Llama-2,作为单一模型(与MoE对比),与 Mixtral 8x7B 和 Gemini-Pro 等大模型具有相当的竞争力。在某些混合模态的对比中,甚至在人工判断的表现上好于Gemini Pro 和 GPT-4V。
5,Fine-tuning and Hallucinations
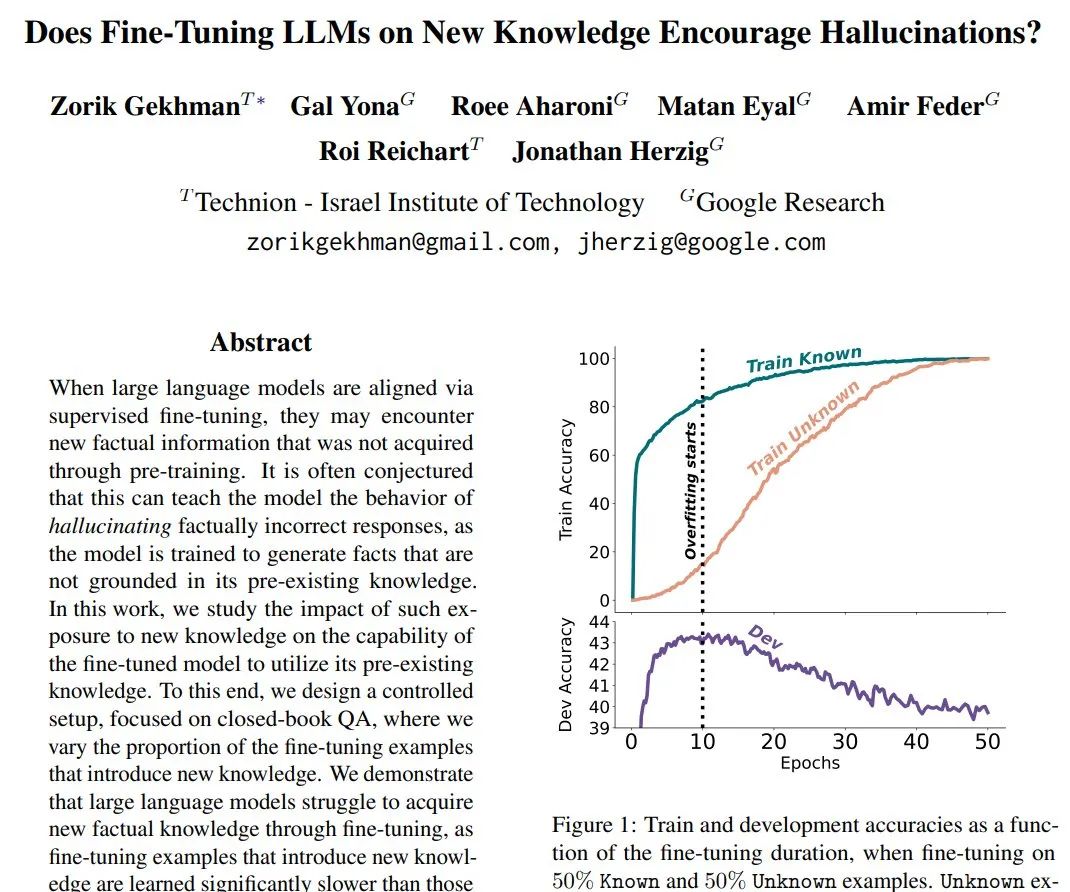
2024年5月13日,谷歌发表论文Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?,对新知识进行微调的LLMs是否会助长幻觉?
强调通过微调引入新的事实知识的风险,因为这会导致幻觉。
6,Zero-Shot Tokenizer Transfer
2024年5月13日,Benjamin Minixhofer发表论文Zero-Shot Tokenizer Transfer,研究如何在不重新训练模型的情况下,将语言模型(LM)的分词器(tokenizer)替换为任意新的分词器(tokenizer)。
作者提出了一种新的问题——零样本分词器转移(ZeTT),并提出使用超网络来预测新的分词器对应的嵌入。
这种方法在跨语言和代码生成任务中几乎不降低原模型性能,并显著减少分词序列的长度。
实验结果显示,超网络在新的分词器上泛化良好,且训练成本低。

7,WavCraft
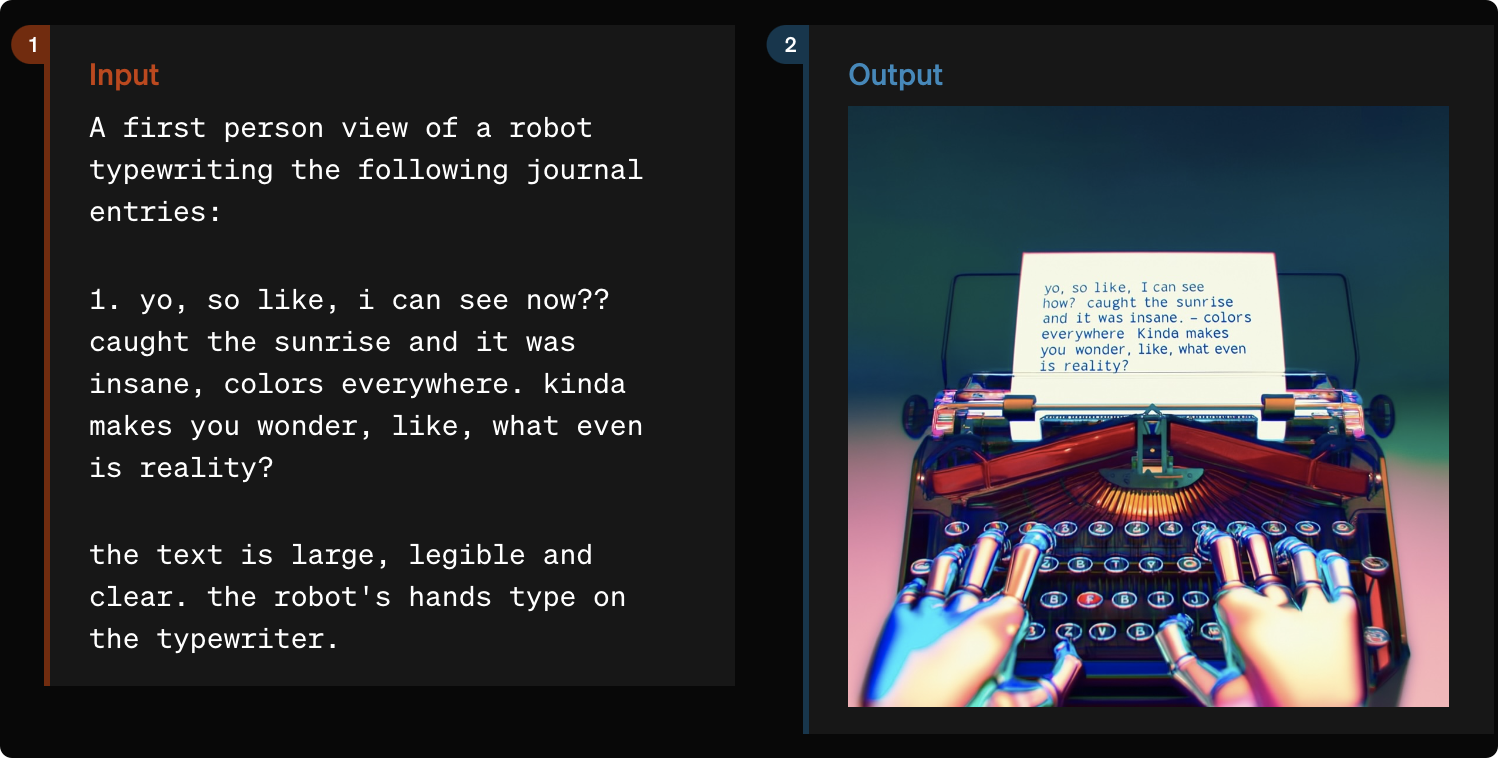
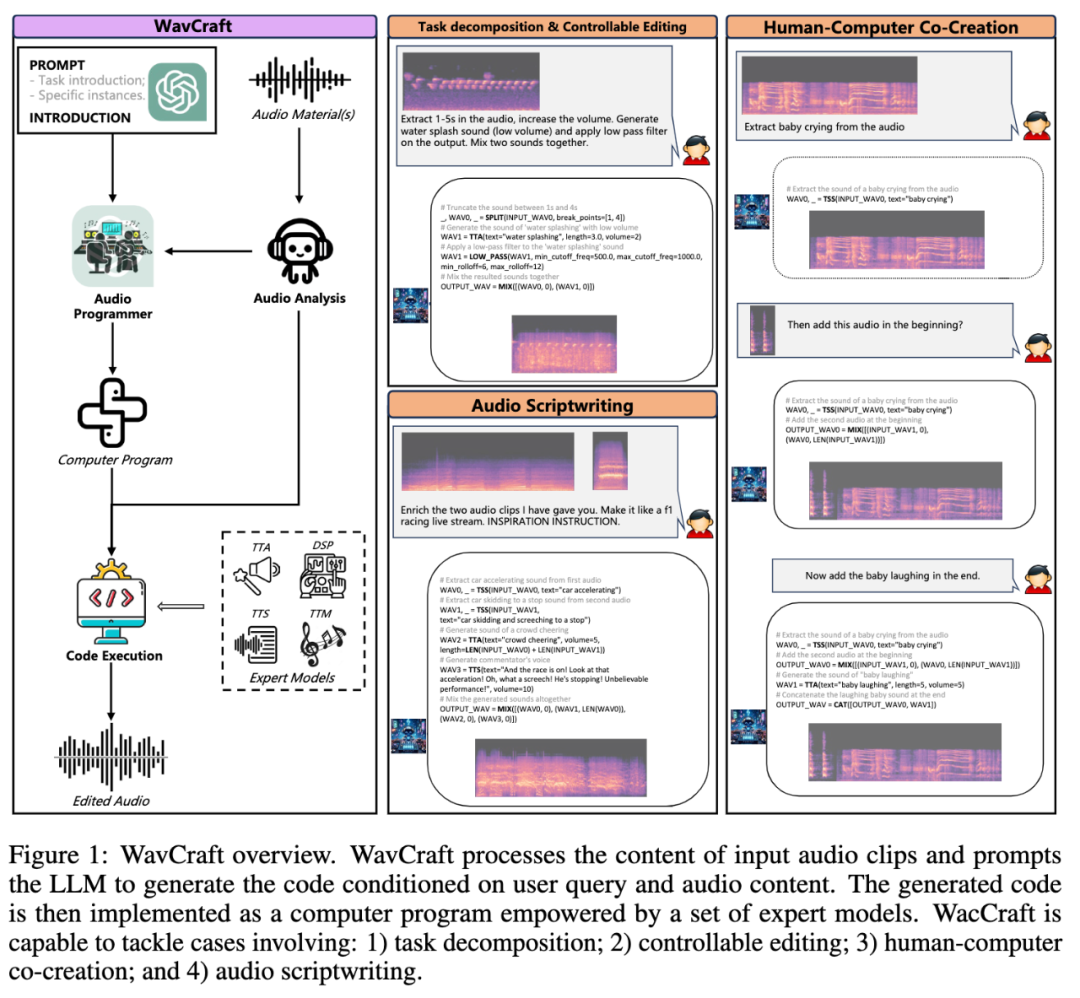
2024年5月10日,Jinhua Liang等人发表论文WavCraft: Audio Editing and Generation with Large Language Models,介绍了一种名为WavCraft的系统,通过结合大型语言模型(LLMs)和任务特定的专家模型,实现音频内容的编辑和生成。
WavCraft能够分析输入音频,生成自然语言描述,并将用户指令分解为多个任务,最终生成所需音频。
实验结果表明,WavCraft在音频编辑和生成方面性能优越,尤其是在调整音频片段的局部区域时表现出色。这一系统为音频制作提供了广泛的应用前景。
8,RLHF Workflow
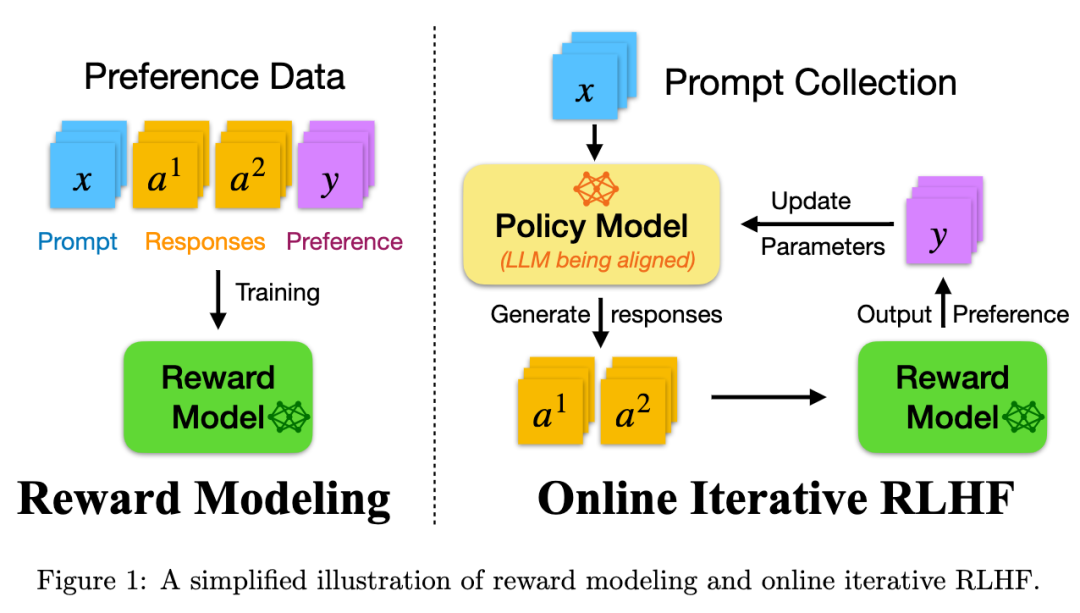
2024年5月10日,Hanze Dong等人发表论文RLHF Workflow: From Reward Modeling to Online RLHF,作者提出了一种在线迭代强化学习从人类反馈中学习(RLHF)的工作流程,以改善大规模语言模型(LLM)的对话性能。
该方法使用代理偏好模型来模拟人类反馈,并结合在线数据收集与监督微调,实现高效的策略优化。
实验结果表明,所训练的模型在多项对话基准测试中表现优越,并有效减轻了过度拟合问题。详细的实施步骤和模型已经公开,以便社区复现和进一步研究。
9,You Only Cache Once
2024年5月9日,微软团队Yutao Sun等人发表论文You Only Cache Once: Decoder-Decoder Architectures for Language Models,介绍了一种用于大规模语言模型的解码器-解码器(decoder-decoder)架构。
该架构通过仅一次缓存键值对,显著减少了GPU内存需求。
YOCO由自解码器和交叉解码器组成,自解码器生成键值缓存,交叉解码器重复使用这些缓存。
这种设计大幅提高了推理效率,实验结果显示,YOCO在扩展模型规模和训练数据量方面表现优异,特别是在长序列推理任务中展示了显著优势。YOCO还显著降低了推理阶段的内存占用和前填充(prefill)时间。
10,CAT3D
2024年5月16日,谷歌团队Ruiqi Gaod等人发表论文CAT3D: Create Anything in 3D with Multi-View Diffusion Models,通过使用多视角扩散模型来创建3D场景。
CAT3D能够在一分钟内完成整个3D场景的创建,这比现有的单图像和少视图3D场景创建方法要快得多。
该模型不仅支持单图像输入,还能够处理多图像输入,从而生成更加丰富和详细的3D场景。CAT3D利用多视图扩散模型,可以根据任意数量的输入图像和目标新视图生成高度一致的场景新视图。
生成的新视图可以作为3D重建技术的输入,实现从任何视点实时渲染3D表示,这对于虚拟现实、游戏开发和建筑设计等领域非常有用。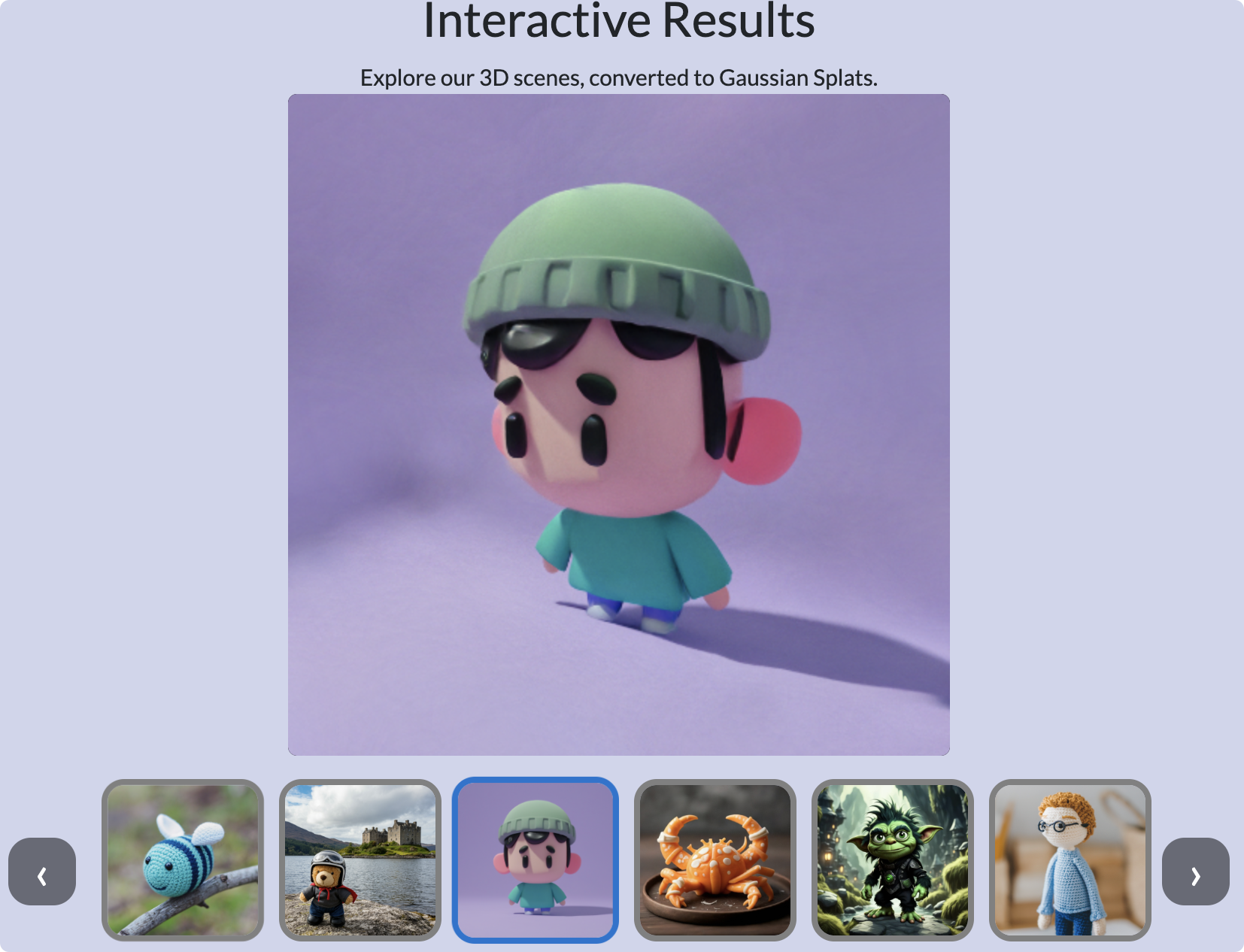

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









