









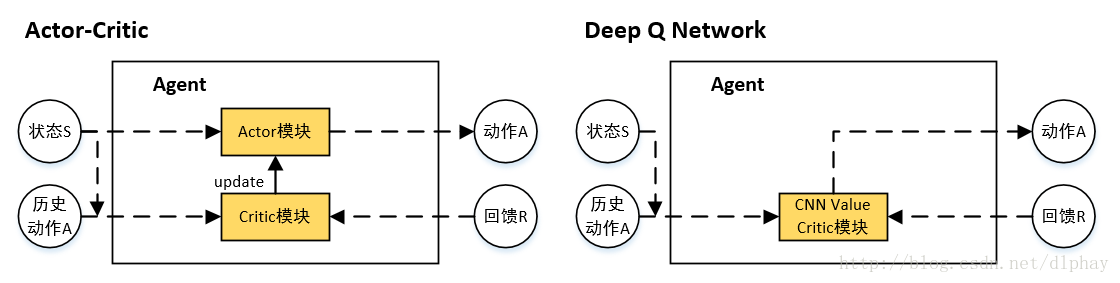
 本文探讨了增强学习(RL)在自动驾驶领域的应用,强调了长期规划和决策的重要性。通过结合搜索和RL算法,可以解决复杂的自动驾驶问题。指出在环境不确定和转移函数未知的情况下,RL能提供自适应决策。同时,提出RL在自动驾驶中的挑战,包括自适应能力、模型可解释性和推理能力,并引用NVIDIA的DAVE-2系统和深度驾驶研究作为实例,展示了RL在端到端学习和模拟训练中的作用。
本文探讨了增强学习(RL)在自动驾驶领域的应用,强调了长期规划和决策的重要性。通过结合搜索和RL算法,可以解决复杂的自动驾驶问题。指出在环境不确定和转移函数未知的情况下,RL能提供自适应决策。同时,提出RL在自动驾驶中的挑战,包括自适应能力、模型可解释性和推理能力,并引用NVIDIA的DAVE-2系统和深度驾驶研究作为实例,展示了RL在端到端学习和模拟训练中的作用。
csdn公式编辑器不好用,就直接从word里面截图发上来一些理论公式:

长期规划问题
迷宫:复杂决策的情景----我们只有把基于搜索的和基于增强学习的算法结合,才能有效解决这类问题。
围棋:确定性的环境,长期奖励----基于搜索的和基于增强学习的算法结合
自动驾驶:环境非确定--转移函数未知
自动驾驶简介
感知、决策和控制
决策:(对安全和可靠性有着严格要求)
1 对行车计划进行长期规划
2 对周围车辆和行人的行为进行预测
注:关于这里的决策模块,对于驾驶中可能出现的各种突发情况,基于规则的决策系统不可能枚举到所有突发情况。我们需要一种自适应系统来应对驾驶环境中出现的各种突发情况
自动驾驶决策模拟器
注:(感知和控制模块在CSDN《程序员》2016年8月《基于Spark与ROS的分布式无人驾驶模拟平台》介绍)
决策模拟器:
1 环境中场景模拟:车道情况、路面情况、障碍物分布和行为、天气等。
2 真实环境中场景采集到的数据进行回放。
决策模拟器的作用:
1 验证:对常见场景的安全性、快捷性、舒适性打分衡量算法性能
2 增强学习:在突发情况中获得的奖励,学习如何应对。
提出改进方向
1 增强学习的自适应能力:在环境性质发生改变时,需要试错很多次才能学习到正确的行为,如何少量样本学习到正确的行为。
2 模型的可解释性:增强学习中的策略函数和值函数都是由深度神经网络表示的,其可解释性比较差,难以排查。
3 推理和想象能力:足够好的模型来推理和想象做出相应行为可能会发生的后果。
NVIDIA的一篇论文《End to End Learning for Self-Driving Cars》
1 DARPA Autonomous Vehicle (DAVE)
2 Autonomous Land Vehicle in a NeuralNetwork (ALVINN) system--Pomerleau
在这两个基础上NVIDIA提出DAVE-2
端输入:前置摄像头的像素 端输出:汽车的控制命令(车轮角度:1/r)
硬件平台:NVIDIA DRIVE PX
训练平台:Torch 7
训练框架:
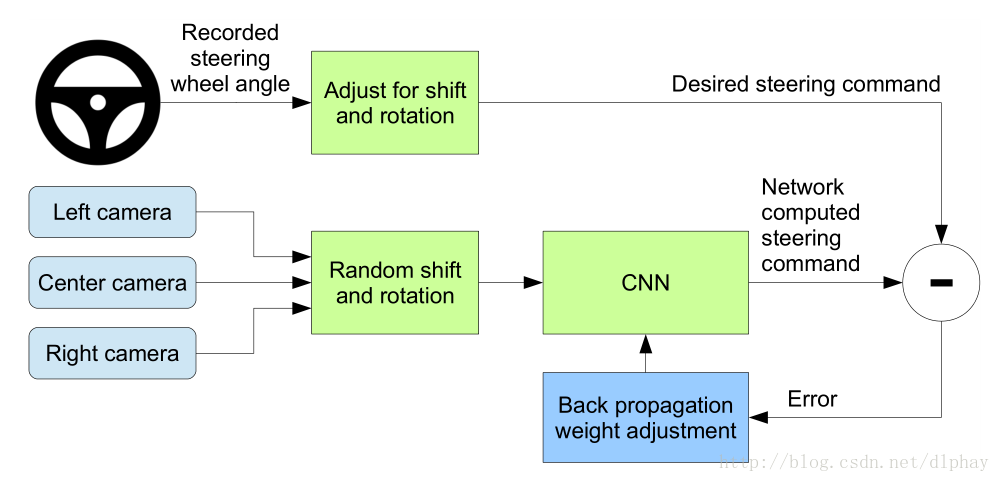
CNN计算可能的驾驶指令,然后把这个可能的指令和标记进行对比来更新CNN的权值(Center camera是正样本,Left camera和Right camera是负样本)。当网络训练好了以后,用Center camera的结果输入到CNN进行计算输出给汽车的控制命令。
仿真框架:
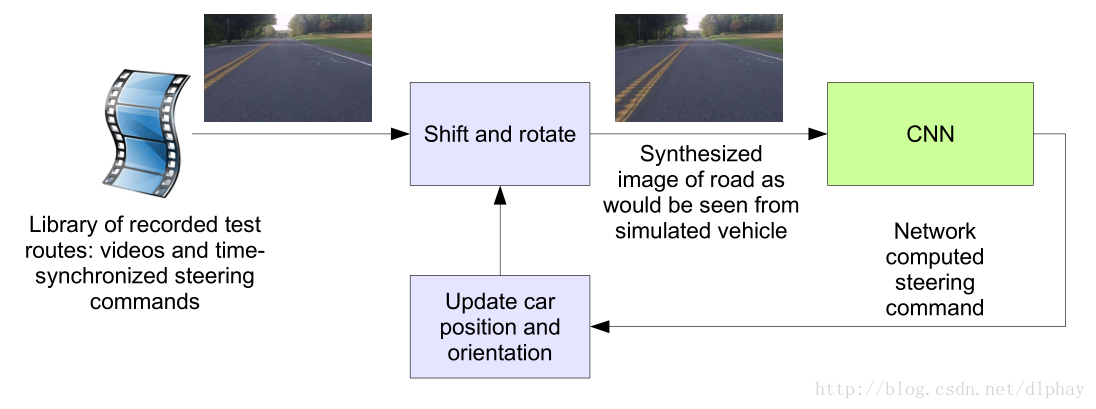
手动校准每帧为“ground truth”,使得每帧图像在车道中心。
仿真器记录偏心距离、旋角、里程
如果偏心距离超过1m,进行虚拟人工干预,重置为原测试视频的相应帧的ground truth
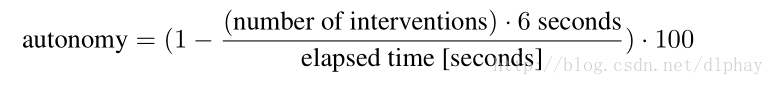
用autonomy值来评估
CVPR论文《深度驾驶:自动驾驶中的学习可供性》
主要的范式:
1 间接知觉方法:解析整个画面计算高维度世界表征(解析环境)来进行驾驶决策
问题:系统的复杂度和成本相对于简单的汽车控制比较高
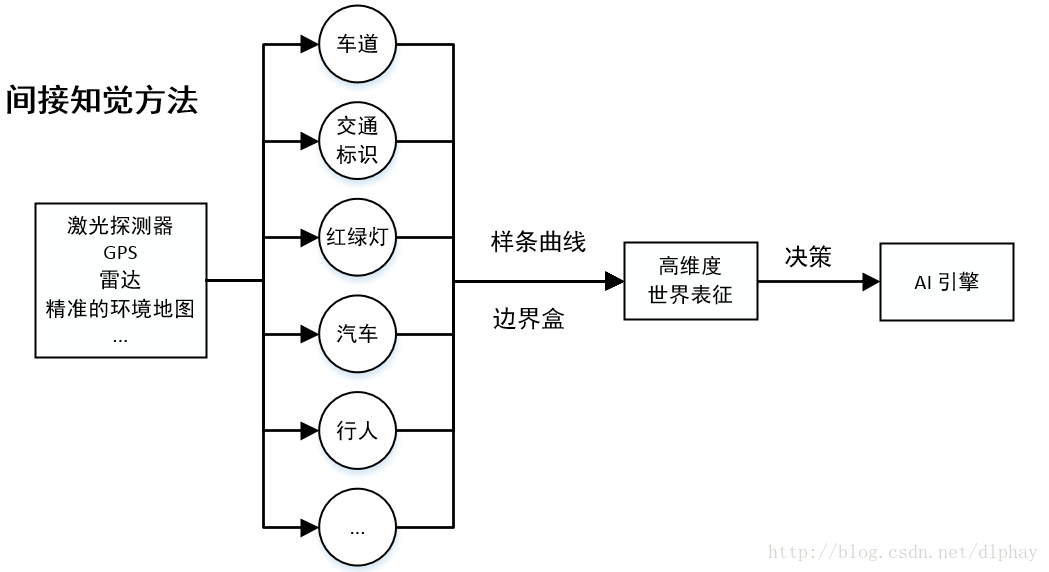
2 行为反射方法:通过一个回归量,直接将输入画面与驾驶行为匹配
问题:不同的人类驾驶员可能做出完全不同的驾驶决定,这导致了在训练回归量时得使用一个错误建构的问题。
3 直接知觉方法:学习将图像与多个有意义的路况可供性指标匹配起来,包括车辆相对于道路的角度、与车道标记线之间的距离以及与目前车道和隔壁车道中车辆的距离
模型:基于尖端的深度卷积神经网络框架
训练库:赛车电子游戏 TORCS记录的屏幕画面和相应的标签
利用一个深度 ConvNet 架构来估测驾驶行为的可供性,在TORCS中模拟训练好的模型,去应用于真实世界进行性能评估。

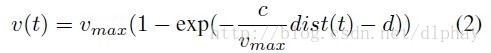
目标:通过(1)式,最小化车辆目前位置和车道中心线之间的间隙。
通过(2)式,控制器通过控制加速或刹车,让实际速度符合desired_speed。















 607
607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









