






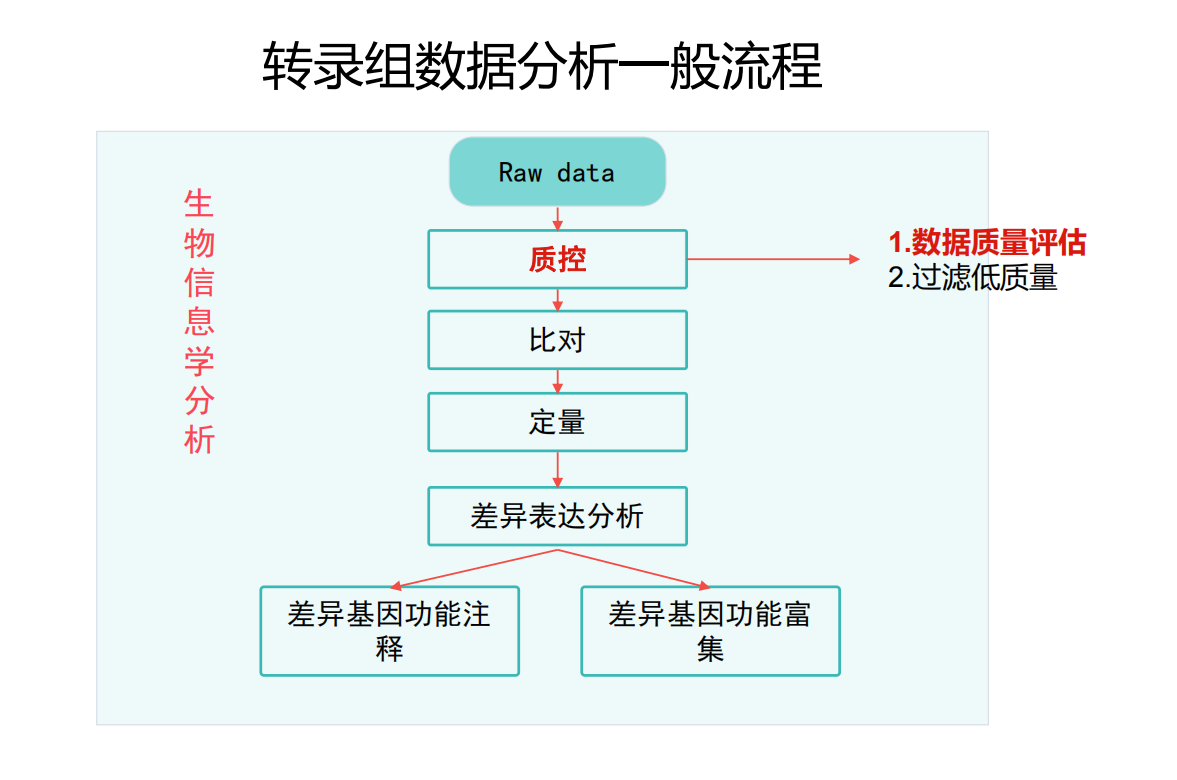
往往我们质控完之后的数据有着各种各样的问题,比如接头没去、低质量的reads等,因此在继续进行分析的时候我们要使用trim-galore/fastp对数据进行过滤。
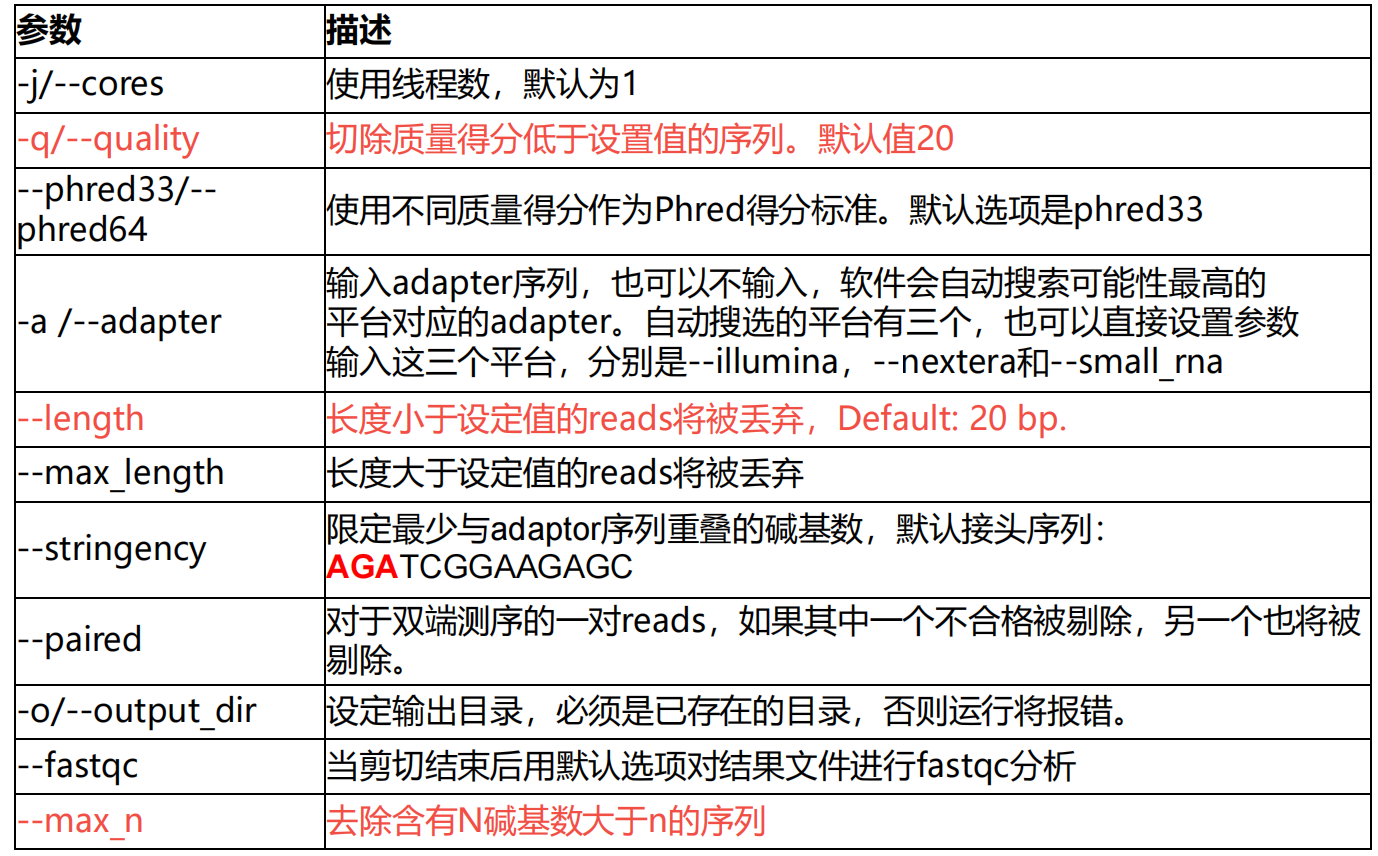
输入:之前经过质控的fastq文件或者或者fastq.gz文件
代码:
# 激活小环境
conda activate rna
# 新建文件夹trim_galore
cd $.../data/cleandata/trim_galore
# 多个样本 vim trim_galore.sh,以下为sh的内容,创建脚本
rawdata=$.../data/rawdata
cleandata=$.../data/cleandata/trim_galore
cat ID | while read id
do
trim_galore -q 20 --length 20 --max_n 3 --stringency 3 --fastqc --paired
-o ${cleandata} ${rawdata}/${id}_1.fastq.gz ${rawdata}/${id}_2.fastq.gz
done
# 提交任务到后台
nohup sh trim_galore.sh >trim_galore.log &
# 使用MultiQc整合FastQC结果
multiqc *.zip
输出:过滤之后的fastq文件或者或者fastq.gz文件
Fastp
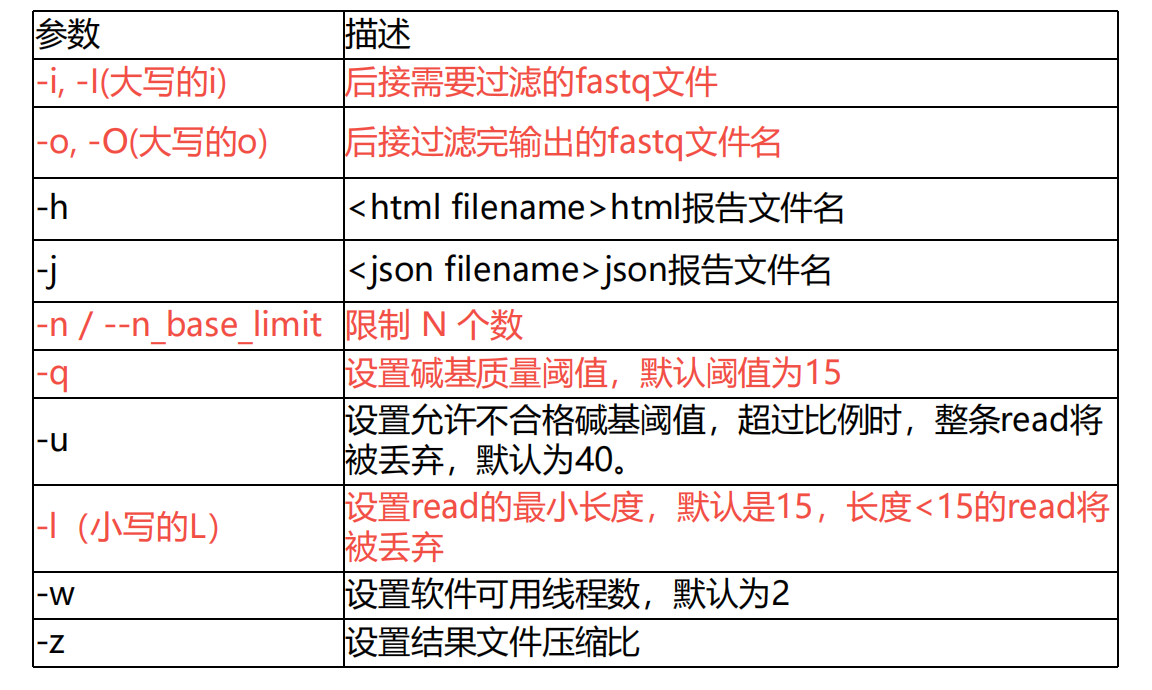
输入:之前经过质控的fastq文件或者或者fastq.gz文件
cd $.../data/cleandata/fastp
# 定义文件夹:vim fastp.sh
cleandata=$H.../data/cleandata/fastp/
rawdata=$.../data/rawdata/
cat ../trim_galore/ID | while read id
do
fastp -l 36 -q 20 --compression=6 \
-i ${rawdata}/${id}_1.fastq.gz \
-I ${rawdata}/${id}_2.fastq.gz \
-o ${cleandata}/${id}_clean_1.fq.gz \
-O ${cleandata}/${id}_clean_2.fq.gz \
-R ${cleandata}/${id} \
-h ${cleandata}/${id}.fastp.html \
-j ${cleandata}/${id}.fastp.json
done
# 运行fastp脚本
nohup sh fastp.sh >fastp.log &输出: 过滤之后的fastq文件或者或者fastq.gz文件
讨论trimgalore与fastp的不同
1.fastp的运行速度相对会快很多,去adapter更准确、高效
2.输出文件的名字写法不同
trimgalore:{id}_1_val_1.fq.gz 和 {id}_2_val_2.fq.gz
fastp:SRR***_1.fastp.fq.gz SRR***_2.fastp.fq.gz
3.fastp之后质控会输出一个KMER统计表格















 3733
3733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









