









1. UDP协议
UDP只在IP数据报服务之上增加了很少功能,即复用分用和差错检测功能。
UDP的主要特点:
-
UDP是无连接的,减少开销和发送数据之前的时延。
-
UDP使用最大努力交付,即不保证可靠交付。
-
UDP是面向报文的,适合一次性传输少量数据的网终应用。
应用层给UDP多长的报文,UDP就照样发送,即一次发一个完整报文。
UDP报文太长,会导致数据报在网络层分片,导致效率低,
UDP报文太低,导致网络层的IP报头比有效载荷长很多,导致效率下降。所以应用层传输的数据报长度需要适中。
-
UDP没有拥塞控制,适合很多实时应用。(视频会议)
-
UDP首部开销比较小8B,TCP首部固定字段20B(不包括选项字段和填充字段)
UDP报文格式

16位UDP长度:代表的是UDP报文的整个长度
16位UDP检验和:检验整个UDP数据报是否出错。出错就丢弃报文。
UDP报文分用时,找不到对应的目的端口号,就丢弃报文。
并给发送方发送ICMP端口不可达差错报告报文.
UDP校验过程
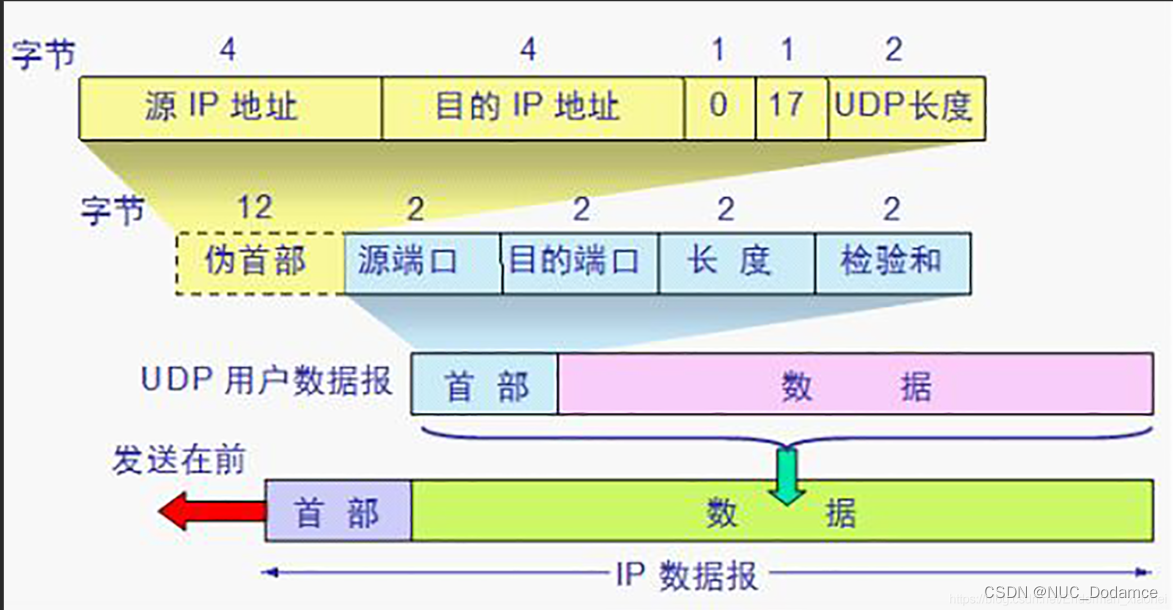
伪首部:
- 在计算校验和的时候才出现,不向上传递或向下传递
- 伪首部的第三个字段为全0
- 第四个字段17代表,封装UDP报文的IP数据报首部协议字段是17。
- UDP长度:UDP首部8B+数据部分长度(不包括伪首部)。
伪首部校验过程:

上图中每一行都是4字节。有时UDP报文数据部分不一定是4字节的整数倍,需要在后面填充0到4字节整数倍。
UDP校验在发送方:
- 填充伪首部
- 校验和字段全部填写为0(初始化校验和)
- 数据部分填充到4字节的倍数。
- 伪首部+首部+数据部分采用二进制反码求和。
- 将求和结果求反码填充到校验和字段
- 去掉伪首部,发送数据
UDP校验在接收方:
- 填上伪首部
- 伪首部+首部+数据部分采用二进制反码求和。(此时校验和字段不是0)
- 结果二进制序列全为1则无差错,否则丢弃数据报或交给应用层附上出差错的警告。差错控制由应用层负责。
















 2102
2102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











