






数据中心网络扩容并不容易,涉及设备上架,切换等又硬又大的动作,期间对所有应用都会产生影响,所以理论上 “加钱加硬件” 这种看起来很简单的事实际上真不如 “写一个随时部署升级的端到端拥塞控制算法” 更容易实施。
傍晚绕小区跑步时感悟,一个不算老的小区,美中不足的是环绕小区的小路上分布着停车位,人车分流改造并不难,道路下面挖下去和地下停车场接通,小区入口开个车库口子即可。但工程上的容易只有先开工才能说,如果没开工,就没工程的事了。问题恰是如何开工,谁出钱,为什么出钱,肯不肯出钱,钱到位,大家能不能忍受施工期的噪声,灰土,围栏等不便,考虑到现状虽然不完美,至少还算 ok,何必多此一举,这个工程也就永远开不了工了。
所以说企图重构数据中心甚至互联网架构的想法都是纸上谈兵,企图重构底层协议的想法也是纸上谈兵。重构必须有厂商携带产品与资本甚至政令加持,即使如此,看看 ipv6 的部署过程,温言在口大棒在手也不好使。
从小区地面停车位不好人车分流可以看出,很多问题之所以不修正,并不是它不好修正,而是因为现状没有太糟糕,而现状恰恰是从 “最开始” 到现在的积累。很多工程类问题问 “为什么会怎样?” 时,答案很简单,“因为它一开始就这样”,可能是深思熟虑的设计,也可能是偶然。积重难返的结果是安土重迁。
tcp/ip 分组交换网已有 40 多年历史,作为一种 “新样式” 的网络技术,电路交换被贴上 “旧技术” 的标签,分组交换机替换了程控电路交换机,每个端口以固定速率接收和发出一系列分组,如果发生多个端口往一个端口发送分组,则用 buffer 暂存冲突分组,排队论为这一切提供理论支撑。
分组交换网络持续迭代成了现在复杂的互联网,但本质上还是 “每个端口以固定比特率接收和发出一系列分组,如果发生多个端口往一个端口发送分组,则用 buffer 暂存冲突分组”,电路交换被彻底抛在脑后,谁提谁就是开倒车。
然而大多数技术都是老技术的重新组合,要换一个视角理解电路交换而不是彻底抛弃它。
接下来从拥塞控制的视角重新理解电路交换,先从问题说起。
如今应对网络拥塞多数是反馈拥塞信息,待 sender 事后收缩,这种端到端的方法有固有滞后性,且对短突发无效,所以我才多次提到按突发长度分流的方法。
另外,我们认识到,传输前多花一个额外 rtt 请求链路预留资源来置换直接传输后可能的拥塞排队时间和丢包重传时间,看起来也划算,但如果是一系列短突发,额外的一个 rtt 在总时延的占比就会很高,不如一把梭哈赌一把,很可能就直接成功了,如果后续仍有数据传输,再预留资源,或在继续传输前,先考虑配额,homa 就是这思路。不管怎样,信息滞后性无可改变,而解决方案也都自带把戏性质。
再深究一下,为什么在拥塞了之后无法让报文立即绕行另一条路,或更直接一点,为什么不能立即申请更大带宽。我们发现原来分组交换导致了这问题本身,而它远不是解决该问题的方案,排队论的队列长度永远不会为 0。
核心原因是,“每个端口以固定比特率接收和发出一系列分组,如果发生多个端口往一个端口发送分组,则用 buffer 暂存冲突分组”,如果立即绕路,在新路上仍然会递归遭遇拥塞导致拥塞扩散,甚至死锁(与 pfc 大差不差),而端口比特率固定意味着无法动态申请新带宽,比如无法将隔壁 40Gbps 端口空闲的 20Gbps 带宽划到拥塞端口。
下图是一个传统的例子:
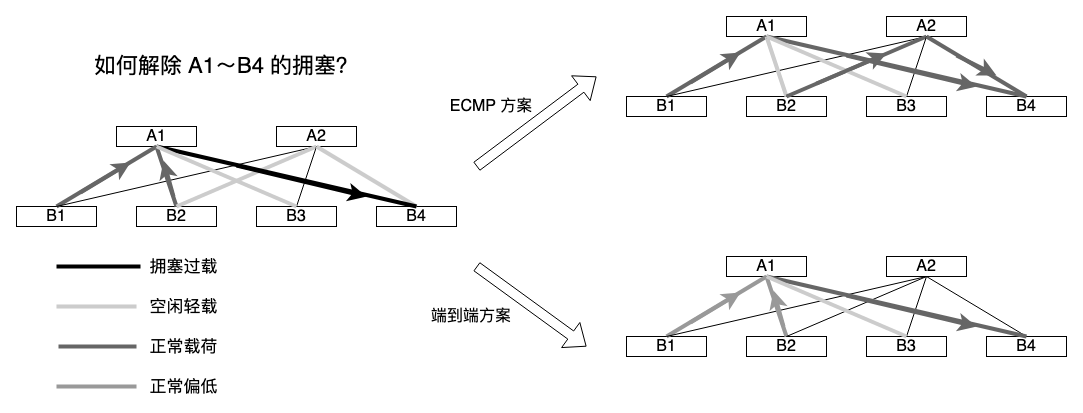
总体看来,无论是 ecmp,还是流量工程,或者端到端拥塞控制,本质上都在对流量本身下手,所谓调度的是流量,过程中的带宽是一定的,还是老的方法论,横竖颠倒一下就香了,流量锁住,调度带宽啊。
电路交换 low 吗?不,新技术大多都是旧事重组合,换个方式用电路交换就高尚了,让程序去接线调度带宽,回归程控交换机。要是不明白,面包板是电路交换的好例子。
如果网线直接插入面包板而不是插入交换机端口,面包板矩阵的通断受程序控制,这面包板就是一台新样式程控交换机了,它本质上就在不断执行接线,断线工作,将某些链路导通从而提供新带宽。
回到最初的问题,拥塞就是端口带宽不够用了,如何将隔壁空闲带宽划过来。
这又是一个解耦合问题,分组交换机只执行分组路由,而带宽资源划分通过电路交换机执行 “面包板接线” 完成:
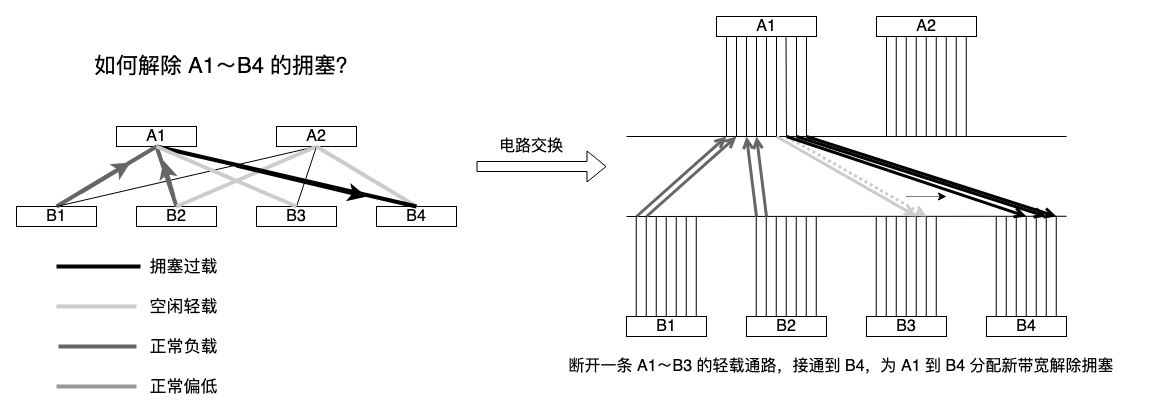
分组交换机只负责可达性,电路交换机为分组交换机的可达流量分配以及调度带宽资源,达到最大化资源利用率。两类交换机通过信令交互,比如分组交换机告诉电路交换机哪个端口队列过长,电路交换机从空闲资源中分配链路带宽并接通,反馈给分组交换机结果,开启新的端口。
电路交换机事实上可改变拓扑布线,实现逻辑 clos 到物理直连之间的任意形态。胖树的每一层都应该接一个面包板来解耦合可达性和带宽分配。
那么问题来了,带宽以多大粒度来分配。这是一个话题。
比如带宽以 10Gbps 为粒度,一台传统分组交换机上行端口有 10 个,每个 40Gbps 的话,上行端口带宽总和就是 400Gbps,改成支持电路交换分配带宽的新式交换机的话,则需要 40 根链路接入 “面包板”,每根 10Gbps,10 个端口所需的带宽在这 40 根链路中按需动态分配。
计算很简单,总 4000Gbps 带宽就是 400 根线缆,如果按 5Gbps 为分配粒度,就是 800 根,一共接入 40 台交换机的话,就是 320000 根线缆,“面包板” 上将密密麻麻,而面包板内部的电路交换机的任务就是调度这些线缆之间的接通和断开。
事情并没有不可收拾,反而这可能本就是趋势。前面也提到过,摩尔定律在芯片尺寸继续变小到足以产生量子效应时已不再有效,主机网卡在追平交换机带宽过程中,主机始发流量持续增加,交换机只能通过并行化提高交换容量满足主机的大流量需求,除此之外不能再指望提高单端口能力。
未来的交换机可能就是进出很多线缆,因为单根线缆接入的单端口带宽已经无法再像以前那样指数级增长了。然而这成千上万的线缆(姑且叫 subline)并非如我们肉眼所见,它们有自己的方式集成捆绑在一起,从交换机引出,插入电路交换机,肉眼可见的只有一根线缆(subline 的集合),比以前还要更简单:
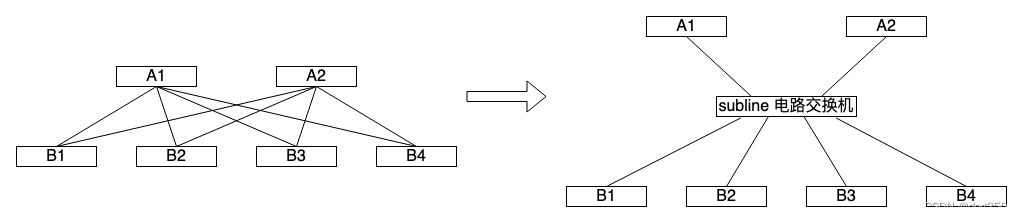
我此前觉得如果真的交换机端口 400Gbps x 8 了,是聚合它们使用呢,还是用 multipath 协议管理它们呢。如果聚合起来将会失去弹性,比如它们空闲时很难被其它端口使用,如果用 mp 协议管理,可想而知这协议将非常复杂。其实用电路交换就行,让专门的程序去管理,而分组交换机的 buffer 队列时间正好为信令的交换和电路的通断提供了缓冲时间。
以下是一个场景:
- 交换机 A 端口 p1 拥塞,对端为交换机 B 端口 p1 ,队列长度 100 告警;
- 交换机 A 端口 p1 触发信令 s1,需申请 5Gbps 带宽;
- 电路交换机处理 s,断开空闲的交换机 A 端口 p2-3 和交换机 B 端口 p4-2,接通二者,回复信令 s2;
- 交换机 A 将 p2-3 加入 p1,交换机 B 将 p4-2 加入 p1;
- 交换机 A 端口 p1 队列逐渐清除,拥塞解除。
要点是,通过控制并行拓展的线缆(即 subline)的通断使带宽资源完全池化(但有最小粒度),分配机制的具体操作很简单:
- 分别在连通拥塞源和目标的 subline 中各找一根空闲的;
- 断开找到的这两根 subline 分别的对端,将二者接通;
- 将 subline 归属拥塞端口,带宽分配结束。
以 subline 分配带宽的过程就像分配内存 page 一样,完全可编程。
dcn 和广域网不同之处在于它全局可观测,而 sdn 控制器可根据观测的结果指标控制电路交换机,动态均衡各个链路的带宽负载,这是分组交换机通过信令主动申请带宽的补充。
而对于广域网,虽然在拓扑上它远没有 dcn 规整,但也可以将某个子网(易拥塞子网,比如那些过境流量多突发大象流的子网)划为一个 “subline 域”,在其中部署电路交换机进行带宽动态分配:
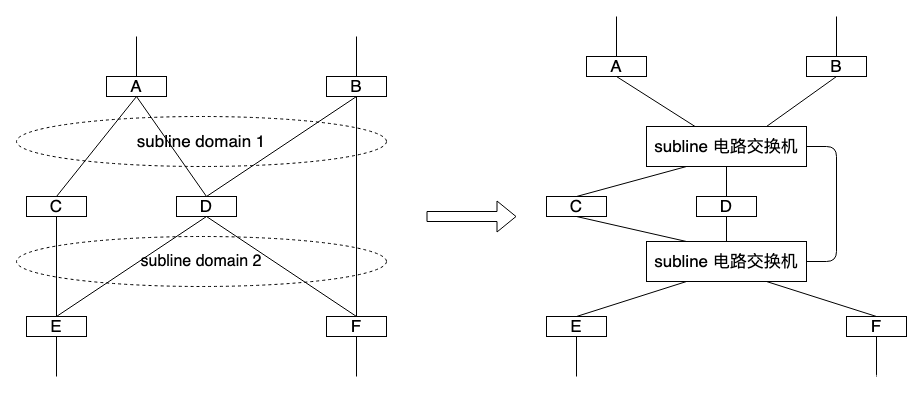
先说这么多。
浙江温州皮鞋湿,下雨进水不会胖。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









