







 本文介绍了SPSS中的个案排序和变量排序操作,包括使用'数据'菜单的'个案排序'和'变量排序'功能,以及如何新增属性。个案排序有助于查找和修改,变量排序便于发现输入错误和缺失值。同时,文章讲解了如何通过'创建索引'加速大型数据集的操作,并详细阐述了还原排序顺序的方法。
本文介绍了SPSS中的个案排序和变量排序操作,包括使用'数据'菜单的'个案排序'和'变量排序'功能,以及如何新增属性。个案排序有助于查找和修改,变量排序便于发现输入错误和缺失值。同时,文章讲解了如何通过'创建索引'加速大型数据集的操作,并详细阐述了还原排序顺序的方法。
个案排序与变量排序
前言
排序的用途:
- 将案例按ID变量排序,有利于查找、修改;
- 将某个变量按升序或降序排列,可以非常容易的发现输入错误,因为它们往往就是最大/最小值;
- 缺失值在排序中会排在最小值前面,可以通过排序的方法发现哪些记录为缺失。
排序的实现: - 数据视图,变量名处右键菜单。【简单排序:单变量、多变量的同种排序规则(同为升序或降序)】
- 数据–> 个案排序。【多变量的复杂排序(比如:一部分变量升序,一部分变量降序)】
1. 案例排序(个案排序)
Steps:
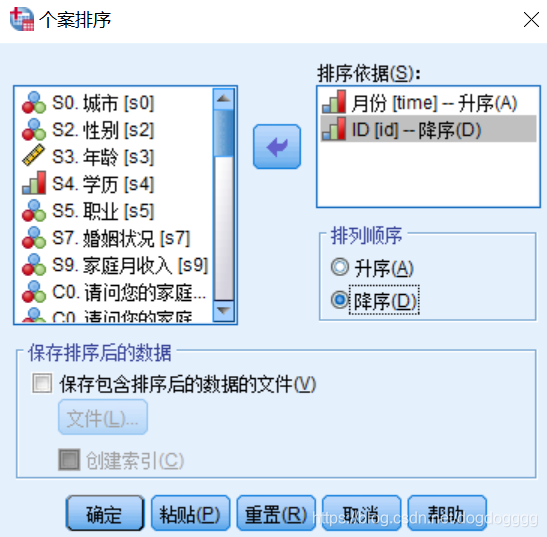
‘数据’–> ‘个案排序’–> 将需要排序的变量选入‘排序依据’;排序顺序可以选择‘升序’或‘降序’–> ‘确定’。
**另外:**对于大型的数据集,可以勾选‘保持包含排序后的数据的文件’。
也可以勾选‘创建索引’:实际上在内部加了一个索引,在大型数据集中‘合并文件’时可以增速。
2. 变量排序
都是按照‘属性’进行排序
当变量数较多时,对变量进行排序是很有意义的。
Steps: (比如:按照‘名称’排序)
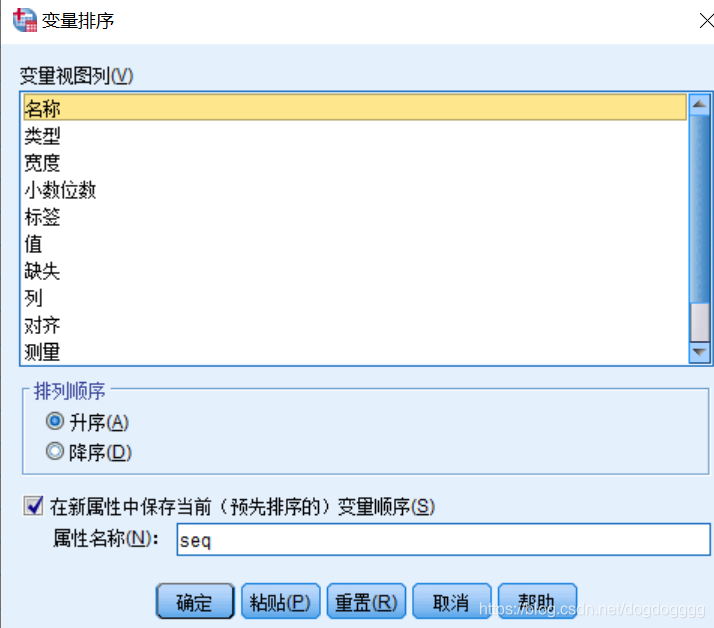
‘数据’–> ‘变量排序’–> (如下对话框所示),可以选择按照哪种方式进行排序,如‘名称’;可以选择‘升序’or‘降序’;勾选‘在新属性中保持当前(预先排序的)变量顺序’,并命名。【该属性保持的是每个变量的原始顺序】
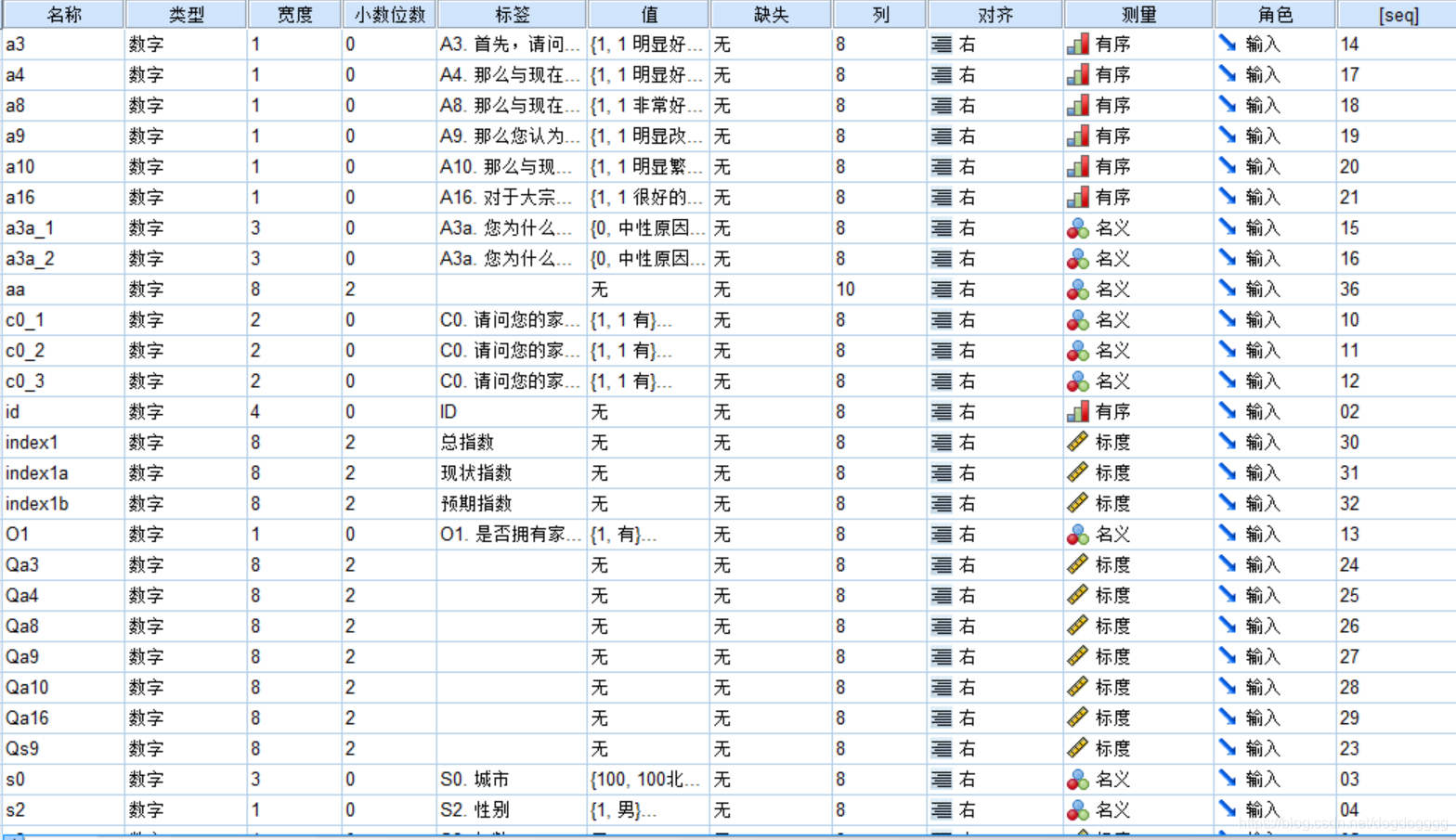
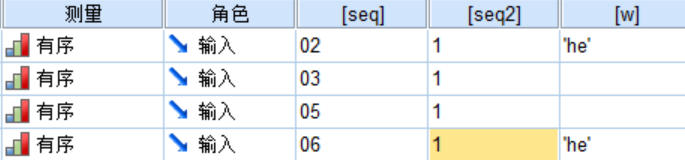
Result: 变量视图如下所示,变量已经按照‘名称’排序,新增属性‘seq’记录了变量的原始顺序(此处可以手动改每个变量的原始数据)。
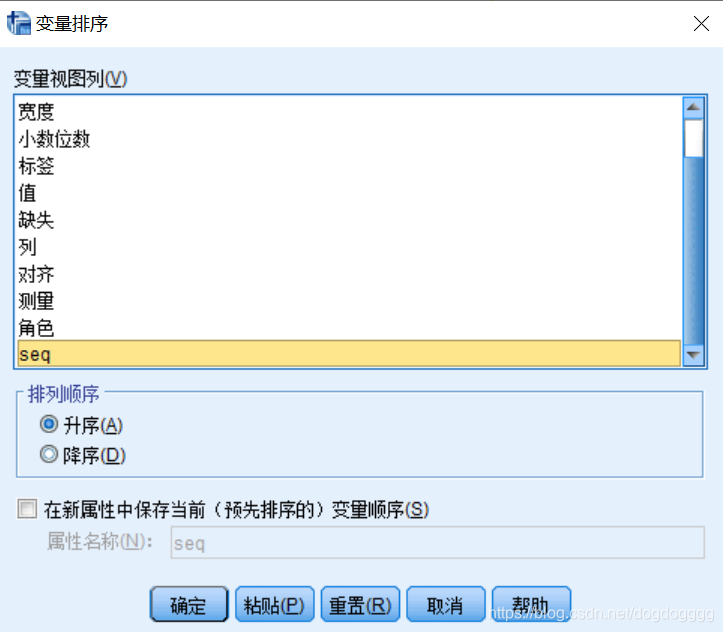
还原: 有了‘seq’属性,则很容易对变量排序进行还原。
‘数据’–> ‘变量排序’–>‘seq’,注意: 不要勾选‘在新属性中保持当前(预先排序的)变量顺序’。即可还原
3. 新增属性
Steps: ‘数据’–> ‘新增定值属性’–> 如下对话框,‘选择变量’:可以选择某些变量(当然,也可以选入所有变量);‘属性名称’:自己给;‘属性值’:可以是数值型,也可以是‘字符串’型–> 确定。

Result:

















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









