







 本文介绍了强化学习中的关键概念on-policy和off-policy,通过Sarsa和q-Learning实例对比,解释了两者在数据收集和策略改进过程中的差异。
本文介绍了强化学习中的关键概念on-policy和off-policy,通过Sarsa和q-Learning实例对比,解释了两者在数据收集和策略改进过程中的差异。
1.前言
强化学习(Reinforcement learning,RL)是机器学习的一个分析,特点是概念多、公式多、入门门槛高🥲(别问我怎么知道的)。本篇文章着重讲解RL最重要的概念之一,即on-policy和off-policy,这2个概念极易与online和offline混淆,为体现文章的独立性,online和offline于下篇blog讲解。话不多话,Let’s go😶!
2.on-policy和off-policy
首先,我们要理解RL大体的工作流程是什么。
- (1)Data collection:智能体与环境进行交互,按照某种方式收集环境中采集的数据,这种收集数据的方式在RL领域称之为behavior policy;
- (2)Policy Improvement:根据收集的数据,智能体改进用于决策的策略,用于决策的策略称之为Target policy;
那什么是on-policy和off-pocliy呢?
官方解释非常的简单直接,但极难理解。官方解释如下。
当behavior policy和target policy相同时,当前的RL算法是on-policy,也称为同策略。
当behavior policy和target policy不同时,当前的RL算法是off-policy,也称为异策略。
嗯……好像什么也没说,又好像什么也说了,留下一脸懵逼的自己,主打一个不理解😶🌫️。
我们来举例说明一下什么是on-policy,什么是off-policy?
以最经典的Sarsa和q-Learning为例。
首先,我们要理解behavior policy采集的数据具体表现是获取下一个状态action,只要谨记这句话,我们就能很轻易地理解on-policy和off-policy。
Sarsa:
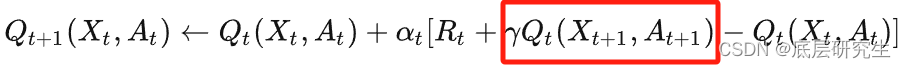
Sarsa在选取下一状态的action时,直接使用当前策略执行了一个action选择,然后再用这个样本去更新当前的策略,所以,Sarsa的behavior policy和target policy是相同的,自然也就是on-policy了。
q-Learning:
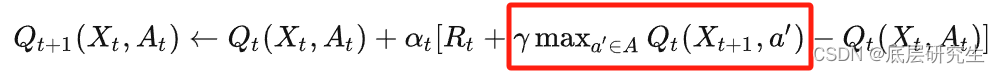
而q-learning在选取下一状态的action时,使用max操作,它计算在当前状态下所有可能action的Q值,并选取回报最大的action(这也就是q-learning容易出现高估问题的根因所在),然后利用这个样本再去更新当前的策略,所以,q-learning的behavior policy和target policy是不同的,自然就是off-policy了。


















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











