






官方文档在docs->torch.nn->Containers->Module
1、神经网络基本骨架 nn.Module
import torch.nn as nn
import torch.nn.functional as F
# 自定义一个模型,继承类
class Model(nn.Module):
def __init__(self): #初始化
super().__init__() #继承父类torch.nn的初始化
self.conv1 = nn.Conv2d(1, 20, 5) #卷积模型1
self.conv2 = nn.Conv2d(20, 20, 5) #卷积模型2
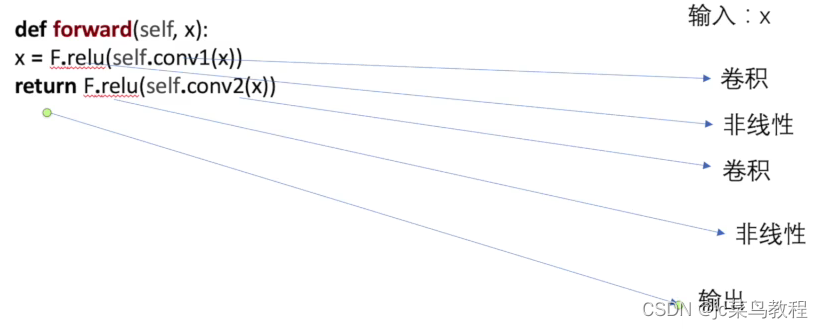
def forward(self, x):
x = F.relu(self.conv1(x)) #对x进行卷积1然后非线性
return F.relu(self.conv2(x)) #对x`进行卷积2然后非线性
————————————————
版权声明:本文为CSDN博主「ni哥跑的快」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Apple0631/article/details/127101925
关于前向传播:
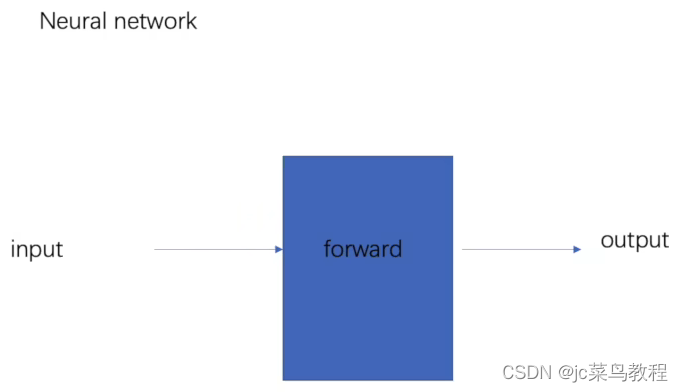
编写自己的简单神经网络
# Name : lsy
# Date : 2023/3/31
import torch
import torch.functional as F
from torch import nn
class Swallow(nn.Module):
# 小技巧 Code->generate -> override Methods
def __init__(self) -> None:
super().__init__()
def forward(self,input):
output = input +1
return output
# 创建自己的神经网络
swallow = Swallow()
x = torch.tensor(1.0)
# x进入forward
out = swallow(x)
print(out)
小技巧:写完class之后,可用pycharm中的这个完成初始化:
Code->Generate -> override Methods
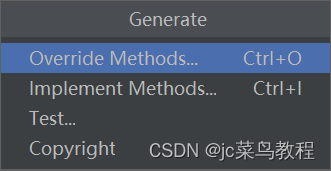
2、卷积操作
注意 torch.nn封装了torch.nn.function
重点看torch.nn即可
Conv2D
先横着扫,再竖着扫
参考链接:https://blog.csdn.net/weixin_43977640/article/details/111239357
简单代码实现
注意:conv2d的输入尺寸!!!
# Name : lsy
# Date : 2023/4/15
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
print(input.shape)
print(kernel.shape)
# 进行尺寸变换
input = torch.reshape(input,(1,1,5,5))
kernel = torch.reshape(kernel,(1,1,3,3))
print('---After reshape---')
print(input.shape)
print(kernel.shape)
output = F.conv2d(input,kernel,stride=1)
print(output)
output2 = F.conv2d(input,kernel,stride=2)
print(output2)
output3 = F.conv2d(input,kernel,stride=1,padding=2)
# 此时output尺寸变大
print(output3)
3、神经网络
(1)卷积层
未设置时,stride=1,padding=0
先横着扫,再竖着扫
(2)最大池化的使用
最大池化,下采样;不会改变channel数
kernel一般为3x3
cell:向上取整
floor:向下取整
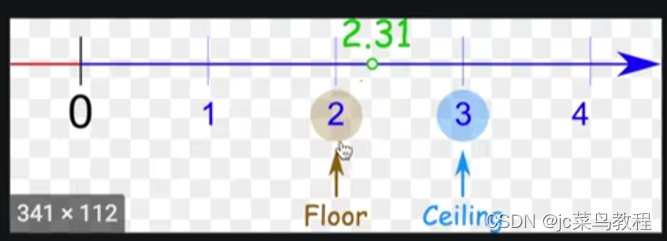
最大池化:选取3x3窗口内的最大值
下图,是否选该6个数的最大值,还是放弃? -> 看cell_model(默认为False不保留)
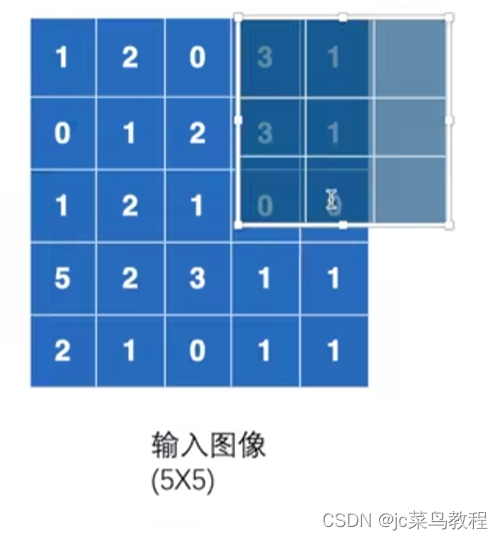
Cell_model = True 则保留
Cell_model = False 则不保留
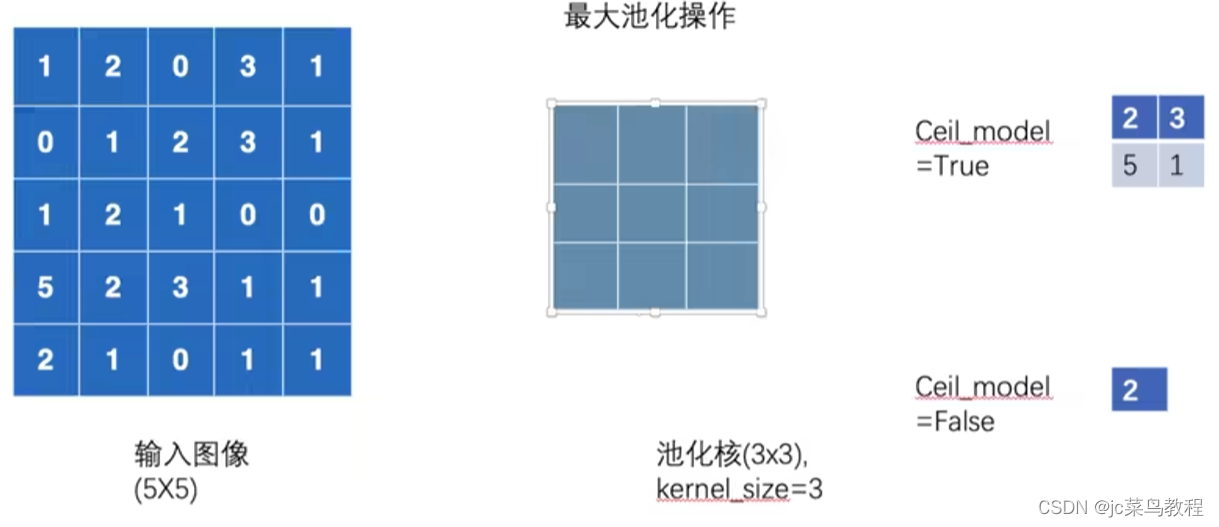
目的:保留特征,降低维度,减少参数,加快速度
(3)非线性激活
-
目的
非线性激活是为了向神经网络中引入非线性特征。
常见: -
ReLu
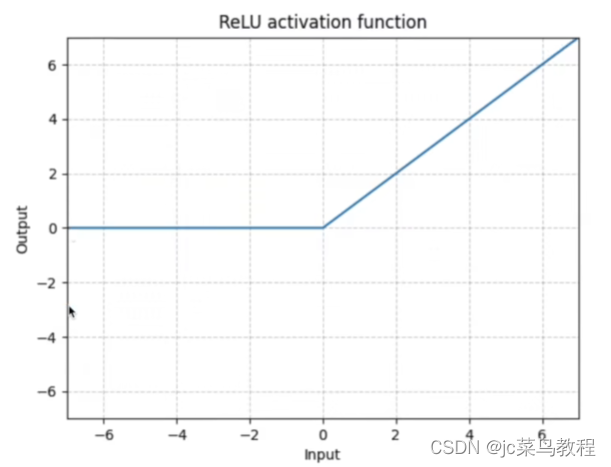
输入(N,*),N为batch_size
- Sigmoid
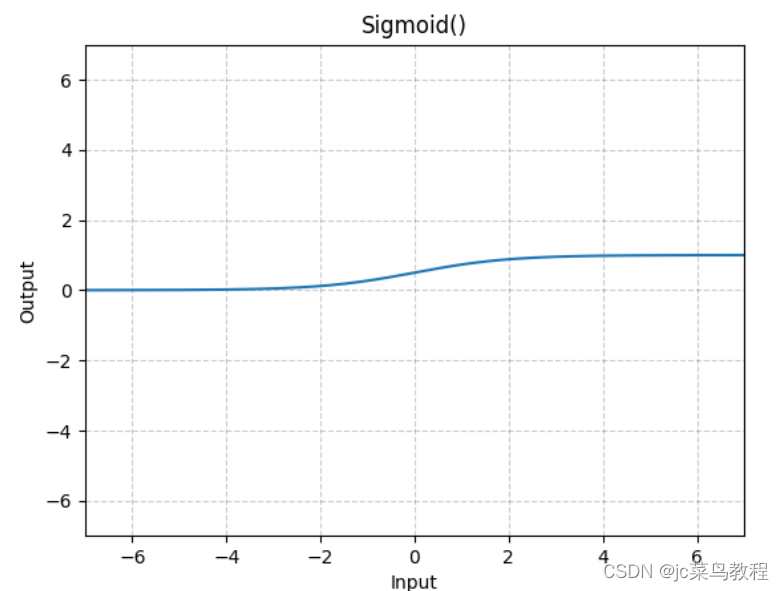
公式:
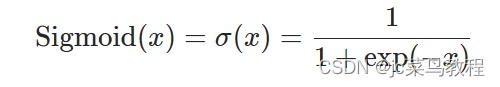

(4)线性层及其他层
-
正则化层 Normalization
用的相对较少 -
Recurrent
用于文字识别较多 -
Transformer
-
线性层 Linear 【重点学习】
用的较多
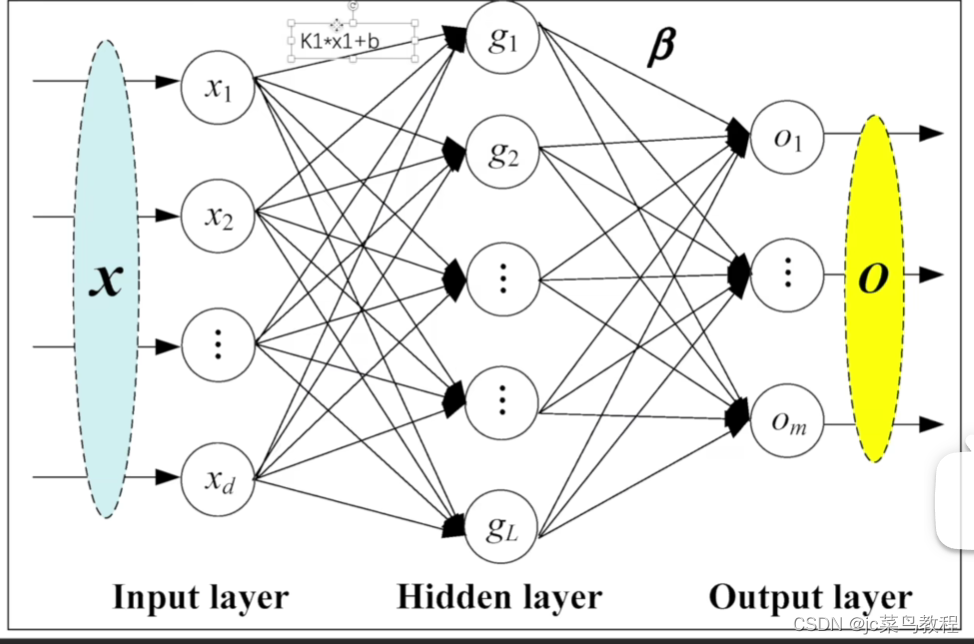
公式如下:
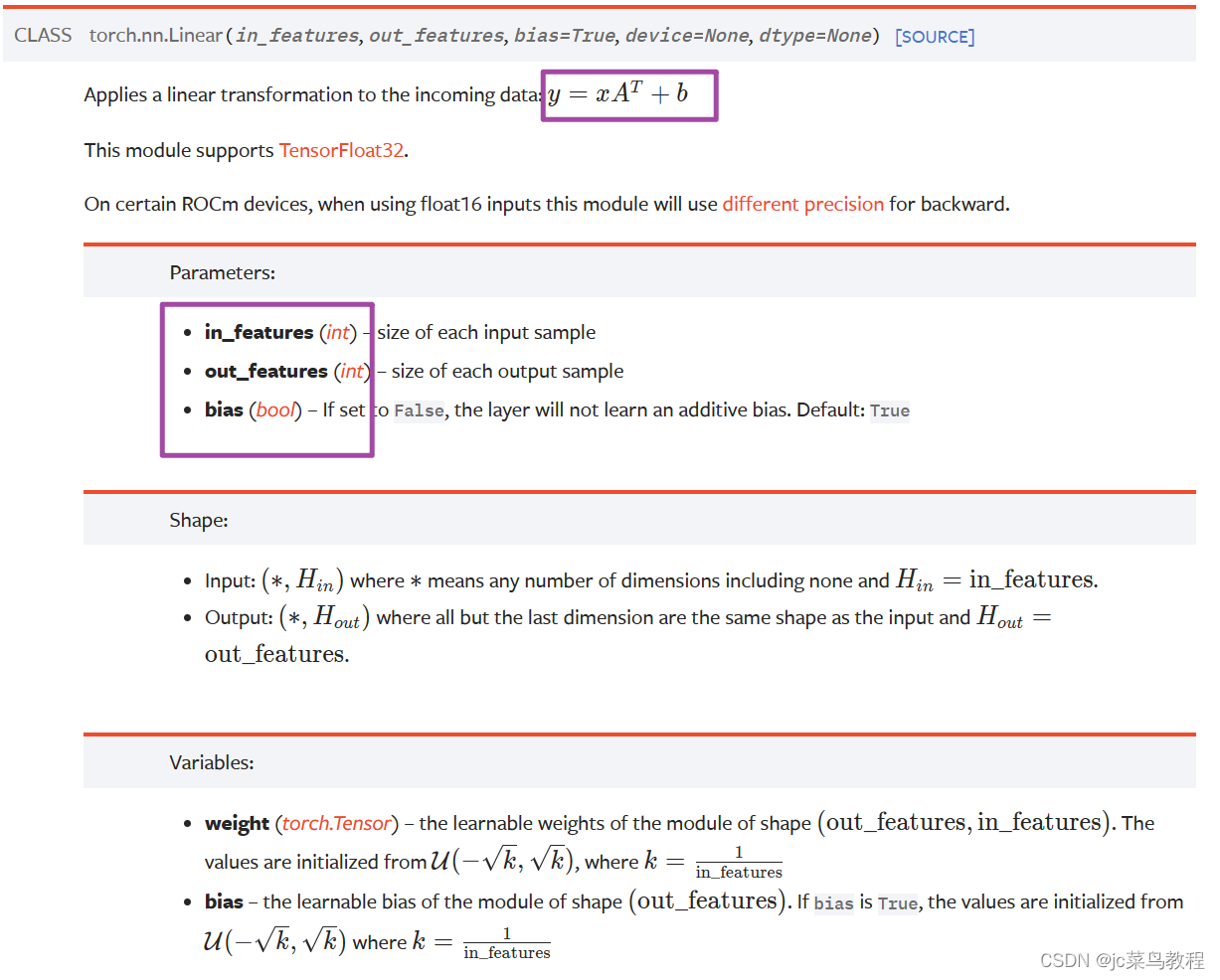
-
Dropout 【练手】
目的:防止过拟合 -
Embedding
用于自然语言处理
(5)搭建实战和Sequential的使用
例子:CIFAR-10-Structure

本例子使用的模型架构:
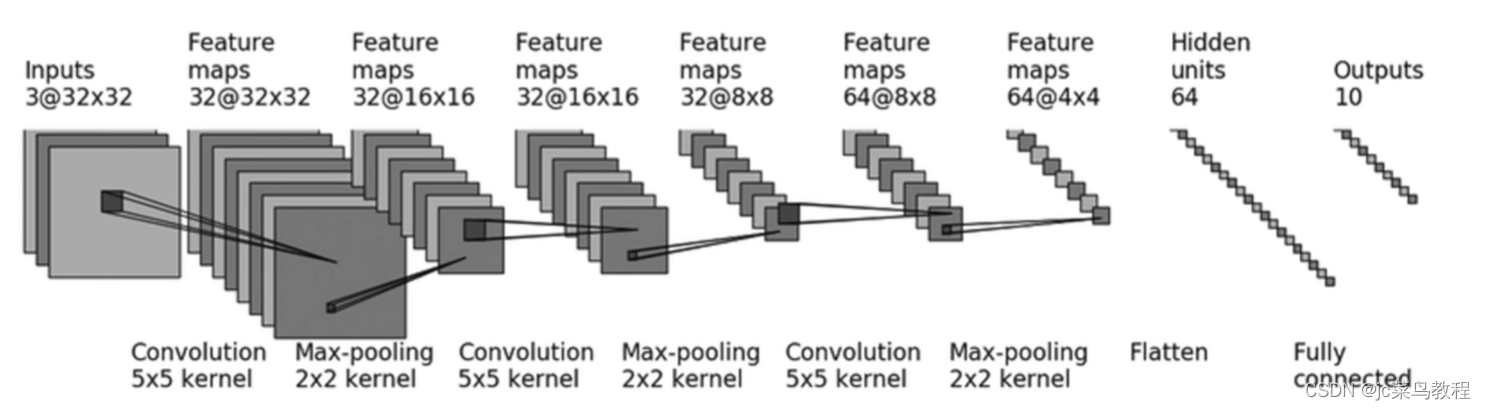
- conv1:
计算padding和stride
先回顾公式

注意:dilation默认为1
若stride取1,则padding为0
常规方法尝试实现:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Swallow(nn.Module):
def __init__(self):
super(Swallow, self).__init__()
self.conv1 = Conv2d(3,32,kernel_size=5,padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32,32,kernel_size=5,padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64,kernel_size=5,padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linearn1 = Linear(1024,64)
self.linearn12 = Linear(64,10)
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linearn1(x)
x = self.linearn12(x)
return x
swallow = Swallow()
print(swallow)
input = torch.ones((64,3,32,32))
y = swallow(input)
print(y.shape)
采用sequence:
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Swallow(nn.Module):
def __init__(self):
super(Swallow, self).__init__()
# self.conv1 = Conv2d(3,32,kernel_size=5,padding=2)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,kernel_size=5,padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(32,64,kernel_size=5,padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten()
# self.linearn1 = Linear(1024,64)
# self.linearn12 = Linear(64,10)
self.seq = Sequential(
Conv2d(3, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, kernel_size=5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linearn1(x)
# x = self.linearn12(x)
x = self.seq(x)
return x
swallow = Swallow()
print(swallow)
input = torch.ones((64,3,32,32))
y = swallow(input)
print(y.shape)
得到输出:
Swallow(
(seq): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
torch.Size([64, 10])
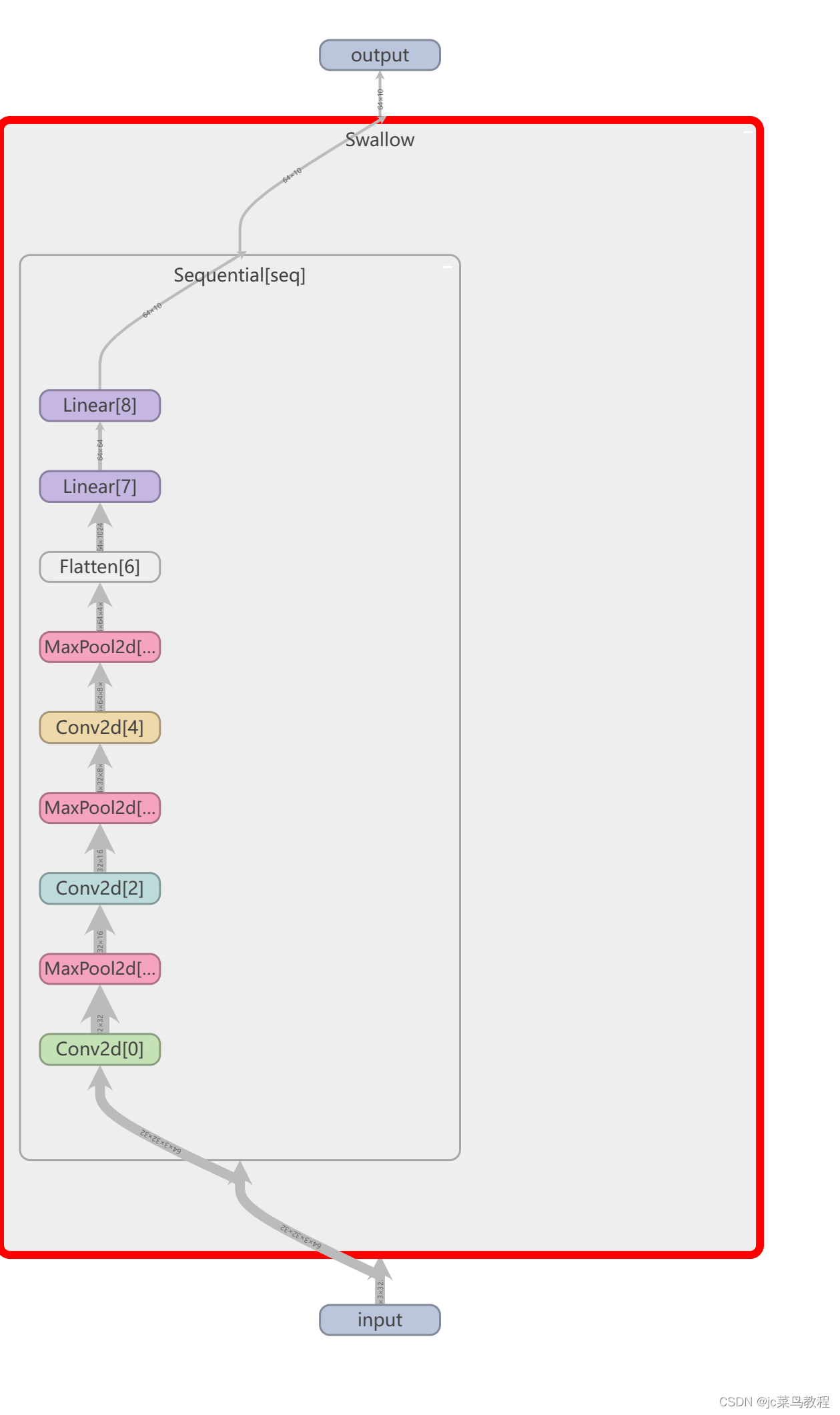
调用tensorboard可视化模型
writer = SummaryWriter('../logs_seq')
writer.add_graph(swallow,input)
writer.close()
得到:
双击swallow














 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









